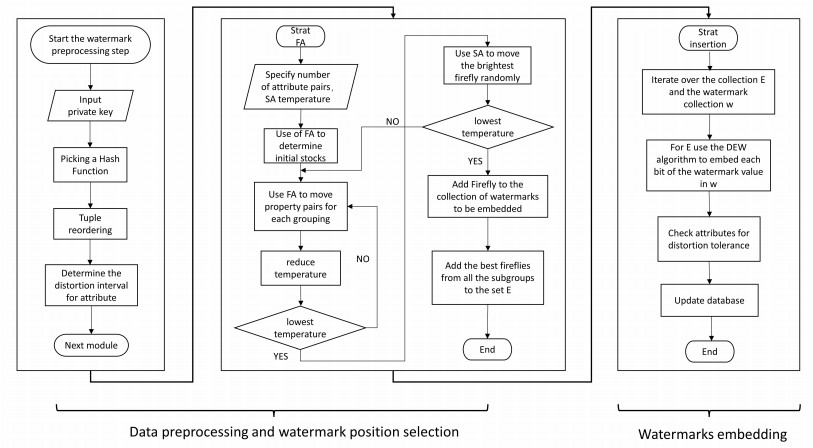
In many fields, such as medicine and the computer industry, databases are vital in the process of information sharing. However, databases face the risk of being stolen or misused, leading to security threats such as copyright disputes and privacy breaches. Reversible watermarking techniques ensure the ownership of shared relational databases, protect the rights of data owners and enable the recovery of original data. However, most of the methods modify the original data to a large extent and cannot achieve a good balance between protection against malicious attacks and data recovery. In this paper, we proposed a robust and reversible database watermarking technique using a hash function to group digital relational databases, setting the data distortion and watermarking capacity of the band weight function, adjusting the weight of the function to determine the watermarking capacity and the level of data distortion, using firefly algorithms (FA) and simulated annealing algorithms (SA) to improve the efficiency of the search for the location of the watermark embedded and, finally, using the differential expansion of the way to embed the watermark. The experimental results prove that the method maintains the data quality and has good robustness against malicious attacks.
Citation: Chuanda Cai, Changgen Peng, Jin Niu, Weijie Tan, Hanlin Tang. Low distortion reversible database watermarking based on hybrid intelligent algorithm[J]. Mathematical Biosciences and Engineering, 2023, 20(12): 21315-21336. doi: 10.3934/mbe.2023943
In many fields, such as medicine and the computer industry, databases are vital in the process of information sharing. However, databases face the risk of being stolen or misused, leading to security threats such as copyright disputes and privacy breaches. Reversible watermarking techniques ensure the ownership of shared relational databases, protect the rights of data owners and enable the recovery of original data. However, most of the methods modify the original data to a large extent and cannot achieve a good balance between protection against malicious attacks and data recovery. In this paper, we proposed a robust and reversible database watermarking technique using a hash function to group digital relational databases, setting the data distortion and watermarking capacity of the band weight function, adjusting the weight of the function to determine the watermarking capacity and the level of data distortion, using firefly algorithms (FA) and simulated annealing algorithms (SA) to improve the efficiency of the search for the location of the watermark embedded and, finally, using the differential expansion of the way to embed the watermark. The experimental results prove that the method maintains the data quality and has good robustness against malicious attacks.

| [1] | X. Tang, Z. Cao, X. Dong, J. Shen, PKMark: a robust zero-distortion blind reversible scheme for watermarking relational databases, in 2021 IEEE 15th International Conference on Big Data Science and Engineering (BigDataSE), (2021), 72–79. https://doi.org/10.1109/BigDataSE53435.2021.00020 |
| [2] |
M. L. P. Gort, M. Olliaro, A. Cortesi, C. F. Uribe, Semantic-driven watermarking of relational textual databases, Expert Syst. Appl., 167 (2021), 114013. https://doi.org/10.1016/j.eswa.2020.114013 doi: 10.1016/j.eswa.2020.114013

|
| [3] |
A. S. Alghamdi, S. Naz, A. Saeed, E. Al Solami, M. Kamran, M. S. Alkatheiri, , A novel database watermarking technique using blockchain as trusted third party, Comput. Mater. Con., 70 (2022), 1585–1601. https://doi.org/10.32604/cmc.2022.019936 doi: 10.32604/cmc.2022.019936
|
| [4] | K. E. Drandaly, W. Khedr, A. M. Mostafa, I. Mohamed, A digital watermarking for relational database: state of Art techniques, Int. J. Adv. Sci. Tech., 29 (2020), 870–883. |
| [5] |
R. Agrawal, P. J. Haas, J. Kiernan, Watermarking relational data: framework, algorithms and analysis, VLDB J., 12 (2003), 157–169. https://doi.org/10.1007/s00778-003-0097-x doi: 10.1007/s00778-003-0097-x
|
| [6] | Y. Zhang, B. Yang, X. M. Niu, Reversible watermarking for relational database authentication, J. Comput., 17 (2006), 59–65. |
| [7] | Y. Zhang, X. M. Niu, Reversible watermark technique for relational databases, Acta Electr. Sin., 34 (2006), 2425–2428. |
| [8] |
M. Shehab, E. Bertino, A. Ghafoor, Watermarking relational databases using optimization-based techniques, IEEE Trans. Knowl. Data Eng., 20 (2008), 116–129. https://doi.org/10.1109/TKDE.2007.190668 doi: 10.1109/TKDE.2007.190668
|
| [9] |
G. Gupta, J. Pieprzyk, Reversible and blind database watermarking using difference expansion, Int. J. Digital Crime and Forensics, 1 (2009), 42–54. https://doi.org/10.4018/jdcf.2009040104 doi: 10.4018/jdcf.2009040104
|
| [10] | C. C. Chang, T. S. Nguyen, C. C. Lin, A blind reversible robust watermarking scheme for relational databases, Sci. World J., 2013 (2013). https://doi.org/10.1155/2013/717165 |
| [11] |
S. Iftikhar, M. Kamran, Z. Anwar, RRW—A robust and reversible watermarking technique for relational data, IEEE Trans. Knowl. Data Eng., 27 (2014), 1132–1145. https://doi.org/10.1109/TKDE.2014.2349911 doi: 10.1109/TKDE.2014.2349911
|
| [12] | M. B. Imamoglu, M. Ulutas, G. Ulutas, A new reversible database watermarking approach with firefly optimization algorithm, Math. Probl. Eng., 2017 (2017). https://doi.org/10.1155/2017/1387375 |
| [13] |
D. Hu, D. Zhao, S. Zheng, A new Robust approach for reversible database watermarking with distortion control, IEEE Trans. Knowl. Data Eng., 3 (2019), 1024–1037. https://doi.org/10.1109/TKDE.2018.2851517 doi: 10.1109/TKDE.2018.2851517
|
| [14] |
S. Rani, R. Halder, Comparative analysis of relational database watermarking techniques: an empirical study, IEEE Access, 10 (2022), 27970–27989. https://doi.org/10.1109/ACCESS.2022.3157866 doi: 10.1109/ACCESS.2022.3157866
|
| [15] | S. Xiang, G. Ruan, H. Li, J. He, Robust watermarking of databases in order-preserving encrypted domain, Front. Comput. Sci., 16 (2022) 162804. https://doi.org/10.1007/s11704-020-0112-z |
| [16] |
K. Jawad, A. Khan, Genetic algorithm and difference expansion based reversible watermarking for relational databases, J. Syst. Softw., 86 (2013), 2742–2753. https://doi.org/10.1016/j.jss.2013.06.023 doi: 10.1016/j.jss.2013.06.023
|
| [17] | K. E. Parsopoulos, M. N. Vrahatis, Particle swarm optimization method for constrained optimization problems, in Intelligent Technologies: From Theory to Applications, IOS Press, (2002), 214–220. |
| [18] | J. Kennedy, R. Eberhart, Particle swarm optimization, in Proceedings of ICNN'95 - International Conference on Neural Networks, 4 (1995), 1942–1948. https://doi.org/10.1109/ICNN.1995.488968 |
| [19] | A. Colorni, M. Dorigo, V. Maniezzo, and others, Distributed optimization by ant colonies, in Proceedings of the first European conference on artificial life, (1991), 134–142. |
| [20] | D. Karaboga, An idea based on honey bee swarm for numerical optimization, in Technical report-tr06, Erciyes university, engineering faculty, computer engineering department, 2005. |
| [21] |
K. Unnikrishnan, K. V. Pramod, Prediction-based robust blind reversible watermarking for relational databases, Int. J. Inform. Comput. Secur., 14 (2021), 211–228. https://doi.org/10.1504/IJICS.2021.114702 doi: 10.1504/IJICS.2021.114702
|
| [22] | X. S. Yang, Nature-inspired Metaheuristic Algorithms, Luniver Press, Frome, 2008. |
| [23] |
A. M. Alattar, Reversible watermark using the difference expansion of a generalized integer transform, IEEE Trans. Image Process., 13 (2004), 1147–1156. https://doi.org/10.1109/TIP.2004.828418 doi: 10.1109/TIP.2004.828418
|
| [24] | Y. Li, J. Wang, X. Luo, A reversible database watermarking method non-redundancy shifting-based histogram gaps, Int. J. Distrib. Sens. Netw., 16 (2020). https://doi.org/10.1177/1550147720921769 |
| [25] | A. Khan, S. A. Husain, A fragile zero watermarking scheme to detect and characterize malicious modifications in database relations, Sci. World J., 2013 (2013). https://doi.org/10.1155/2013/796726 |
| [26] | L. Camara, J. Li, R. Li, W. Xie, Distortion-free watermarking approach for relational database integrity checking, Math. Probl. Eng., 2014 (2014). https://doi.org/10.1155/2014/697165 |
| [27] |
Y. Li, J. Wang, S. Ge, X. Luo, B. Wang, A reversible database watermarking method with low distortion, Math. Biosci. Eng., 16 (2019), 4053–4068. https://doi.org/10.3934/mbe.2019200 doi: 10.3934/mbe.2019200
|
| [28] |
S. Xiao, X. Zuo, Z. Zhang, F. Li, Large-capacity reversible image watermarking based on improved DE, Math. Biosci. Eng., 19 (2022), 1108–1127. https://doi.org/10.3934/mbe.2022051 doi: 10.3934/mbe.2022051
|
| [29] |
A. Alqassab, M. Alanezi, Relational database watermarking techniques: A survey, J. Phys.: Conf. Ser., 1818 (2021), 012185. https://doi.org/10.1088/1742-6596/1818/1/012185 doi: 10.1088/1742-6596/1818/1/012185
|
| [30] | X. Shen, Y. Zhang, T. Wang, Y. Sun, Relational database watermarking for data tracing, in 2020 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery (CyberC), (2020), 224–231. https://doi.org/10.1109/CyberC49757.2020.00043 |
| [31] | H. M. Sardroudi, S. Ibrahim, A new approach for relational database watermarking using image, in 5th International Conference on Computer Sciences and Convergence Information Technology, (2010), 606–610. https://doi.org/10.1109/ICCIT.2010.5711126 |
| [32] |
A. Phadikar, S. P. Maity, B. Verma, Region based QIM digital watermarking scheme for image database in DCT domain, Comput. Electr. Eng., 37 (2011), 339–355. https://doi.org/10.1016/j.compeleceng.2011.02.002 doi: 10.1016/j.compeleceng.2011.02.002
|
| [33] | S. Melkundi, C. Chandankhede, A robust technique for relational database watermarking and verification, in 2015 International Conference on Communication, Information and Computing Technology (ICCICT), (2015), 1–7. https://doi.org/10.1109/ICCICT.2015.7045676 |










Figures(11) / Tables(3)

Chuanda Cai, Changgen Peng, Jin Niu, Weijie Tan, Hanlin Tang. Low distortion reversible database watermarking based on hybrid intelligent algorithm[J]. Mathematical Biosciences and Engineering, 2023, 20(12): 21315-21336. doi: 10.3934/mbe.2023943







 DownLoad:
DownLoad: