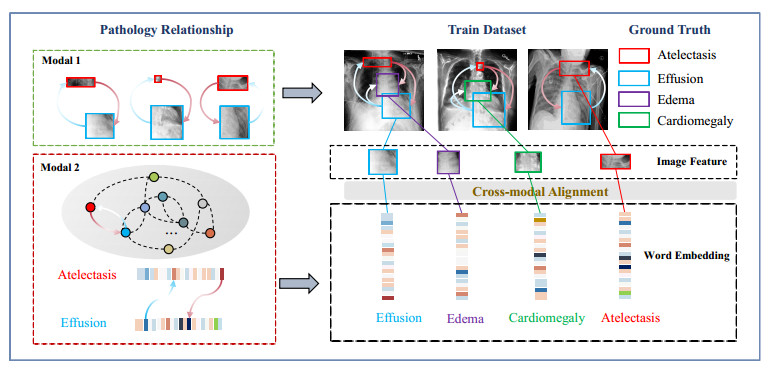
While diagnosing multiple lesion regions in chest X-ray (CXR) images, radiologists usually apply pathological relationships in medicine before making decisions. Therefore, a comprehensive analysis of labeling relationships in different data modes is essential to improve the recognition performance of the model. However, most automated CXR diagnostic methods that consider pathological relationships treat different data modalities as independent learning objects, ignoring the alignment of pathological relationships among different data modalities. In addition, some methods that use undirected graphs to model pathological relationships ignore the directed information, making it difficult to model all pathological relationships accurately. In this paper, we propose a novel multi-label CXR classification model called MRChexNet that consists of three modules: a representation learning module (RLM), a multi-modal bridge module (MBM) and a pathology graph learning module (PGL). RLM captures specific pathological features at the image level. MBM performs cross-modal alignment of pathology relationships in different data modalities. PGL models directed relationships between disease occurrences as directed graphs. Finally, the designed graph learning block in PGL performs the integrated learning of pathology relationships in different data modalities. We evaluated MRChexNet on two large-scale CXR datasets (ChestX-Ray14 and CheXpert) and achieved state-of-the-art performance. The mean area under the curve (AUC) scores for the 14 pathologies were 0.8503 (ChestX-Ray14) and 0.8649 (CheXpert). MRChexNet effectively aligns pathology relationships in different modalities and learns more detailed correlations between pathologies. It demonstrates high accuracy and generalization compared to competing approaches. MRChexNet can contribute to thoracic disease recognition in CXR.
Citation: Guoli Wang, Pingping Wang, Jinyu Cong, Benzheng Wei. MRChexNet: Multi-modal bridge and relational learning for thoracic disease recognition in chest X-rays[J]. Mathematical Biosciences and Engineering, 2023, 20(12): 21292-21314. doi: 10.3934/mbe.2023942
While diagnosing multiple lesion regions in chest X-ray (CXR) images, radiologists usually apply pathological relationships in medicine before making decisions. Therefore, a comprehensive analysis of labeling relationships in different data modes is essential to improve the recognition performance of the model. However, most automated CXR diagnostic methods that consider pathological relationships treat different data modalities as independent learning objects, ignoring the alignment of pathological relationships among different data modalities. In addition, some methods that use undirected graphs to model pathological relationships ignore the directed information, making it difficult to model all pathological relationships accurately. In this paper, we propose a novel multi-label CXR classification model called MRChexNet that consists of three modules: a representation learning module (RLM), a multi-modal bridge module (MBM) and a pathology graph learning module (PGL). RLM captures specific pathological features at the image level. MBM performs cross-modal alignment of pathology relationships in different data modalities. PGL models directed relationships between disease occurrences as directed graphs. Finally, the designed graph learning block in PGL performs the integrated learning of pathology relationships in different data modalities. We evaluated MRChexNet on two large-scale CXR datasets (ChestX-Ray14 and CheXpert) and achieved state-of-the-art performance. The mean area under the curve (AUC) scores for the 14 pathologies were 0.8503 (ChestX-Ray14) and 0.8649 (CheXpert). MRChexNet effectively aligns pathology relationships in different modalities and learns more detailed correlations between pathologies. It demonstrates high accuracy and generalization compared to competing approaches. MRChexNet can contribute to thoracic disease recognition in CXR.

| [1] | L. Yao, E. Poblenz, D. Dagunts, B. Covington, D. Bernard, K. Lyman, Learning to diagnose from scratch by exploiting dependencies among labels, preprint, arXiv: 1710.10501. |
| [2] | X. Wang, Y. Peng, L. Lu, Z. Lu, M. Bagheri, R. M. Summers, ChestX-ray8: Hospital-scale chest X-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2017), 2097–2106. https://doi.org/10.1109/cvpr.2017.369 |
| [3] | C. Galleguillos, A. Rabinovich, S. Belongie, Object categorization using co-occurrence, location and appearance, in 2008 IEEE Conference on Computer Vision and Pattern Recognition, IEEE, (2008), 1–8. https://doi.org/10.1109/cvpr.2008.4587799 |
| [4] | L. Luo, D. Xu, H. Chen, T. T. Wong, P. A. Heng, Pseudo bias-balanced learning for debiased chest X-ray classification, in Medical Image Computing and Computer Assisted Intervention, (2022), 621–631. https://doi.org/10.1007/978-3-031-16452-1_59 |
| [5] | G. Karwande, A. B. Mbakwe, J. T. Wu, L. A. Celi, M. Moradi, I. Lourentzou, Chexrelnet: An anatomy-aware model for tracking longitudinal relationships between chest X-rays, in International Conference on Medical Image Computing and Computer-Assisted Intervention, (2022), 581–591. https://doi.org/10.1007/978-3-031-16431-6_55 |
| [6] |
B. Chen, J. Li, G. Lu, H. Yu, D. Zhang, Label co-occurrence learning with graph convolutional networks for multi-label chest X-ray image classification, IEEE J. Biomed. Health Inf., 24 (2020), 2292–2302. https://doi.org/10.1109/jbhi.2020.2967084 doi: 10.1109/jbhi.2020.2967084

|
| [7] | L. Luo, H. Chen, Y. Zhou, H. Lin, P. A. Heng, Oxnet: deep omni-supervised thoracic disease detection from chest X-rays, in Medical Image Computing and Computer Assisted Intervention, (2021), 537–548. https://doi.org/10.1007/978-3-030-87196-3_50 |
| [8] | B. Hou, G. Kaissis, R. M. Summers, B. Kainz, Ratchet: Medical transformer for chest X-ray diagnosis and reporting, in Medical Image Computing and Computer Assisted Intervention, (2021), 293–303. https://doi.org/10.1007/978-3-030-87234-2_28 |
| [9] | W. Liao, H. Xiong, Q. Wang, Y. Mo, X. Li, Y. Liu, et al., Muscle: Multi-task self-supervised continual learning to pre-train deep models for X-ray images of multiple body parts, in Medical Image Computing and Computer Assisted Intervention, (2022), 151–161. https://doi.org/10.1007/978-3-031-16452-1_15 |
| [10] | P. Rajpurkar, J. Irvin, K. Zhu, B. Yang, H. Mehta, T. Duan, et al., Chexnet: Radiologist-level pneumonia detection on chest X-rays with deep learning, preprint, arXiv: 1711.05225. |
| [11] | G. Huang, Z. Liu, L. Van Der Maaten, K. Q. Weinberger, Densely connected convolutional networks, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2017), 4700–4708. https://doi.org/10.1109/cvpr.2017.243 |
| [12] | Y. Shen, M. Gao, Dynamic routing on deep neural network for thoracic disease classification and sensitive area localization, in International Workshop on Machine Learning in Medical Imaging, Springer, (2018), 389–397. https://doi.org/10.1007/978-3-030-00919-9_45 |
| [13] | F. Zhu, H. Li, W. Ouyang, N. Yu, X. Wang, Learning spatial regularization with image-level supervisions for multi-label image classification, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2017), 5513–5522. https://doi.org/10.1109/cvpr.2017.219 |
| [14] | Z. Wang, T. Chen, G. Li, R. Xu, L. Lin, Multi-label image recognition by recurrently discovering attentional regions, in Proceedings of the IEEE International Conference on Computer Vision, (2017), 464–472. https://doi.org/10.1109/iccv.2017.58 |
| [15] | Q. Guan, Y. Huang, Z. Zhong, Z. Zheng, L. Zheng, Y. Yang, Diagnose like a radiologist: Attention guided convolutional neural network for thorax disease classification, preprint, arXiv: 1801.09927. |
| [16] | J. Wang, Y. Yang, J. Mao, Z. Huang, C. Huang, W. Xu, CNN-RNN: A unified framework for multi-label image classification, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2016), 2285–2294. https://doi.org/10.1109/cvpr.2016.251 |
| [17] | P. P. Ypsilantis, G. Montana, Learning what to look in chest X-rays with a recurrent visual attention model, preprint, arXiv: 1701.06452. |
| [18] | X. Wang, Y. Peng, L. Lu, Z. Lu, R. M. Summers, Tienet: Text-image embedding network for common thorax disease classification and reporting in chest X-rays, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2018), 9049–9058. https://doi.org/10.1109/cvpr.2018.00943 |
| [19] | Y. Tang, X. Wang, A. P. Harrison, L. Lu, J. Xiao, R. M. Summers, Attention-guided curriculum learning for weakly supervised classification and localization of thoracic diseases on chest radiographs, in International Workshop on Machine Learning in Medical Imaging, Springer, (2018), 249–258. https://doi.org/10.1007/978-3-030-00919-9_29 |
| [20] | C. W. Lee, W. Fang, C. K. Yeh, Y. C. F. Wang, Multi-label zero-shot learning with structured knowledge graphs, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2018), 1576–1585. https://doi.org/10.1109/cvpr.2018.00170 |
| [21] | J. Yu, Y. Lu, Z. Qin, W. Zhang, Y. Liu, J. Tan, et al., Modeling text with graph convolutional network for cross-modal information retrieval, in Pacific Rim Conference on Multimedia, Springer, (2018), 223–234. https://doi.org/10.1007/978-3-030-00776-8_21 |
| [22] | Z. M. Chen, X. S. Wei, P. Wang, Y. Guo, Multi-label image recognition with graph convolutional networks, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2019), 5177–5186. https://doi.org/10.1109/cvpr.2019.00532 |
| [23] | J. Irvin, P. Rajpurkar, M. Ko, Y. Yu, S. Ciurea-Ilcus, C. Chute, et al., Chexpert: A large chest radiograph dataset with uncertainty labels and expert comparison, in Proceedings of the AAAI Conference on Artificial Intelligence, 33 (2019), 590–597. https://doi.org/10.1609/aaai.v33i01.3301590 |
| [24] | Z. Li, C. Wang, M. Han, Y. Xue, W. Wei, L. J. Li, et al., Thoracic disease identification and localization with limited supervision, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2018), 8290–8299. https://doi.org/10.1109/cvpr.2018.00865 |
| [25] |
B. Chen, J. Li, X. Guo, G. Lu, Dualchexnet: dual asymmetric feature learning for thoracic disease classification in chest X-rays, Biomed. Signal Process. Control, 53 (2019), 101554. https://doi.org/10.1016/j.bspc.2019.04.031 doi: 10.1016/j.bspc.2019.04.031
|
| [26] | H. Sak, A. Senior, F. Beaufays, Long short-term memory based recurrent neural network architectures for large vocabulary speech recognition, preprint, arXiv: 1402.1128. |
| [27] | Q. Li, X. Peng, Y. Qiao, Q. Peng, Learning category correlations for multi-label image recognition with graph networks, preprint, arXiv: 1909.13005. |
| [28] | A. Fukui, D. H. Park, D. Yang, A. Rohrbach, T. Darrell, M. Rohrbach, Multimodal compact bilinear pooling for visual question answering and visual grounding, preprint, arXiv: 1606.01847. |
| [29] |
Y. Hu, K. Liu, K. Ho, D. Riviello, J. Brown, A. R. Chang, et al., A simpler machine learning model for acute kidney injury risk stratification in hospitalized patients, J. Clin. Med., 11 (2022), 5688. https://doi.org/10.3390/jcm11195688 doi: 10.3390/jcm11195688
|
| [30] | R. Xu, F. Shen, H. Wu, J. Zhu, H. Zeng, Dual modal meta metric learning for attribute-image person re-identification, in 2021 IEEE International Conference on Networking, Sensing and Control (ICNSC), IEEE, 1 (2021), 1–6. https://doi.org/10.1109/icnsc52481.2021.9702261 |
| [31] | J. H. Kim, K. W. On, W. Lim, J. Kim, J. W. Ha, B. T. Zhang, Hadamard product for low-rank bilinear pooling, preprint, arXiv: 1610.04325. |
| [32] |
Z. Yu, J. Yu, C. Xiang, J. Fan, D. Tao, Beyond bilinear: Generalized multimodal factorized high-order pooling for visual question answering, IEEE Trans. Neural Networks Learn. Syst., 29 (2018), 5947–5959. https://doi.org/10.1109/tnnls.2018.2817340 doi: 10.1109/tnnls.2018.2817340
|
| [33] | Y. Wang, Y. Xie, Y. Liu, K. Zhou, X. Li, Fast graph convolution network based multi-label image recognition via cross-modal fusion, in Proceedings of the 29th ACM International Conference on Information & Knowledge Management, (2020), 1575–1584. https://doi.org/10.1145/3340531.3411880 |
| [34] | M. Lin, Q. Chen, S. Yan, Network in network, preprint, arXiv: 1312.4400. |
| [35] | T. Y. Lin, A. RoyChowdhury, S. Maji, Bilinear cnn models for fine-grained visual recognition, in Proceedings of the IEEE International Conference on Computer Vision, (2015), 1449–1457. https://doi.org/10.1109/iccv.2015.170 |
| [36] | P. Veličković, G. Cucurull, A. Casanova, A. Romero, P. Lio, Y. Bengio, Graph attention networks, preprint, arXiv: 1710.10903. |
| [37] | Z. Cao, T. Qin, T. Y. Liu, M. F. Tsai, H. Li, Learning to rank: from pairwise approach to listwise approach, in Proceedings of the 24th International Conference on Machine Learning, (2007), 129–136. https://doi.org/10.1145/1273496.1273513 |
| [38] |
X. Robin, N. Turck, A. Hainard, N. Tiberti, F. Lisacek, J. C. Sanchez, et al., pROC: an open-source package for R and S+ to analyze and compare ROC curves, BMC Bioinf., 12 (2011), 1–8. https://doi.org/10.1186/1471-2105-12-77 doi: 10.1186/1471-2105-12-77
|
| [39] | S. Guendel, S. Grbic, B. Georgescu, S. Liu, A. Maier, D. Comaniciu, Learning to recognize abnormalities in chest X-rays with location-aware dense networks, in Iberoamerican Congress on Pattern Recognition, Springer, (2018), 757–765. https://doi.org/10.1007/978-3-030-13469-3_88 |
| [40] | J. Pennington, R. Socher, C. D. Manning, Glove: Global vectors for word representation, in Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), (2014), 1532–1543, https://doi.org/10.3115/v1/d14-1162 |
| [41] | T. Mikolov, K. Chen, G. Corrado, J. Dean, Efficient estimation of word representations in vector space, preprint, arXiv: 1301.3781. |
| [42] |
R. K. Meleppat, K. E. Ronning, S. J. Karlen, M. E. Burns, E. N. Pugh Jr, R. J. Zawadzki, In vivo multimodal retinal imaging of disease-related pigmentary changes in retinal pigment epithelium, Sci. Rep., 11 (2021), 16252. https://doi.org/10.1038/s41598-021-95320-z doi: 10.1038/s41598-021-95320-z
|
| [43] |
R. Meleppat, M. Matham, L. Seah, An efficient phase analysis-based wavenumber linearization scheme for swept source optical coherence tomography systems, Laser Phys. Lett., 12 (2015), 055601. https://doi.org/10.1088/1612-2011/12/5/055601. doi: 10.1088/1612-2011/12/5/055601
|
| [44] |
R. Meleppat, C. Fortenbach, Y. Jian, E. Martinez, K. Wagner, B. Modjtahedi, et al., In vivo imaging of retinal and choroidal morphology and vascular plexuses of vertebrates using swept-source optical coherence tomography, Transl. Vision Sci. Technol., 11 (2022), 11. https://doi.org/10.1167/tvst.11.8.11 doi: 10.1167/tvst.11.8.11
|
| [45] |
K. Ratheesh, L. Seah, V. Murukeshan, Spectral phase-based automatic calibration scheme for swept source-based optical coherence tomography systems, Phys. Med. Biol., 61 (2016), 7652. https://doi.org/10.1088/0031-9155/61/21/7652 doi: 10.1088/0031-9155/61/21/7652
|
| [46] | D. A. Clevert, T. Unterthiner, S. Hochreiter, Fast and accurate deep network learning by exponential linear units (elus), preprint, arXiv: 1511.07289. |









Figures(10) / Tables(6)

Guoli Wang, Pingping Wang, Jinyu Cong, Benzheng Wei. MRChexNet: Multi-modal bridge and relational learning for thoracic disease recognition in chest X-rays[J]. Mathematical Biosciences and Engineering, 2023, 20(12): 21292-21314. doi: 10.3934/mbe.2023942







 DownLoad:
DownLoad: