Citation: Shanqing Zhang, Xiaoyun Guo, Xianghua Xu, Li Li, Chin-Chen Chang. A video watermark algorithm based on tensor decomposition[J]. Mathematical Biosciences and Engineering, 2019, 16(5): 3435-3449. doi: 10.3934/mbe.2019172

| [1] | A. H. Tewfik, Digital Watermarking, IEEE Signal Processing Magazine, 17 (2000), 17–18. |
| [2] | T. Kalker, G. Depovere and J. Haitsma, Video watermarking system for broadcast monitoring, Secur. Watermark. Multim. Contents, 3657 (1999), 103–112. |
| [3] | F. Hartung and B. Girod, Watermarking of uncompressed and compressed video, Elsevier North-Holland, 66 (1998), 283–301. |
| [4] | I. G. Karybali and K. Berberidis, Efficient spatial image watermarking via new perceptual masking and blind detection schemes, IEEE Transact. Inform. Foren. Secur., 1 (2006), 256–274. |
| [5] | M. J. Lee, K. S. Kim and H. K. Lee, Digital cinema watermarking for estimating the position of the pirate, IEEE Transact. Multim., 12 (2010), 605–621. |
| [6] | J. Han and X. Zhao, An adaptive grayscale watermarking method in spatial domain, J. Inform. Comput. Sci., 12 (2015), 4759–4769. |
| [7] | S. Wang, D. Zheng and J. Zhao, Adaptive watermarking and tree structure based image quality estimation, IEEE Transact. Multim., 16 (2014), 311–325. |
| [8] | Z. Zhou, S. Chen and G. Wang, A robust digital image watermarking algorithm based on dct domain for copyright protection, Int. Symp. Smart Graph., 9317 (2012), 132–142. |
| [9] | I. J. Cox and M. L. Miller, A Review of watermarking and the importance of perceptual modeling, Human Vision Electron. Imag. Confer., 3016 (1997), 92–99. |
| [10] | D.V. S. Chandra, Digital image watermarking using singular value decomposition, Symposium on Circuits & Systems, USA, 2002. |
| [11] | S. Wang, J. Yang and M. Sun, Sparse tensor discriminant color space for face verification, IEEE Transact. Neural Networks Learn. Systems, 23 (2012), 876–888. |
| [12] | B. Ma, L. Huang and J. Shen, Discriminative tracking using tensor pooling, IEEE Transact. Cybernet., 46 (2017), 2411–2422. |
| [13] | J. Li, X. Mao and X. Wu, Human action recognition based on tensor shape descriptor, IET Computer Vision, 10 (2016), 905–911. |
| [14] | A. H. Phan, P. Tichavsky and A. Cichocki, CANDECOMP/PARAFAC decomposition of high-order tensors through tensor reshaping, IEEE Transact. Signal Process., 61 (2013), 4847–4860. |
| [15] | A. S. Jermyn, Efficient tree decomposition of high-rank tensors, J. Comput. Phys., 377 (2018), 142–154. |
| [16] | N. Sidiropoulos, L. L. De and X. Fu, Tensor Decomposition for Signal Processing and Machine Learning, IEEE Transact. Signal Process., 65 (2017), 3551–3582. |
| [17] | E. E. Abdallah, A. B. Hamza and P. Bhattacharya, MPEG Video Watermarking Using Tensor Singular Value Decomposition, Image Analysis & Recognition, Canada, 2007. |
| [18] | H. Xu, G. Jiang and M. Yu, A Color Image Watermarking Based on Tensor Analysis, IEEE Access, 6 (2018), 51500–51514. |
| [19] | P. Li and W. K. Leung, Decoding low density parity check codes with finite quantization bits, Commu. Lett. IEEE, 4 (2000), 62–64. |
| [20] | K. K. Sharma and A. Upadhyay, A novel image fusion technique for gray scale images using tensor unfolding in transform domains, Recent Advances & Innovations in Engineering, India, 2014. |
| [21] | R. Costantini, L. Sbaiz and S. Susstrunk, Higher Order SVD Analysis for Dynamic Texture Synthesis, IEEE Transact. Image Process., 17 (2008), 42–52. |
| [22] | Y. Wu, H. Tan and Y. Li, A fused CP factorization method for incomplete tensors, IEEE Transact. Neural Networks Learn. Systems, 30 (2018), 751–764. |
| [23] | G. Zhou, A. Cichocki and Q. Zhao, Efficient Nonnegative Tucker Decompositions: Algorithms and Uniqueness, IEEE Transact. Image Process., 24 (2015), 4990–5003. |
| [24] | A. Rajwade, A. Rangarajan and A. Banerjee, Image Denoising Using the Higher Order Singular Value Decomposition, IEEE Transact. Pattern Anal. Mac. Intell., 35 (2013), 849–862. |
| [25] | K. Wang, G. Zhou and G. Fu, An Approach to Fast Eye Location and Face Plane Rotation Correction, J. Computer-Aided Design Comput. Graph., 25 (2013), 865–879. |
| [26] | P. F. Checcacci and P. Spalla, Analysis and correction of errors in a polarimeter for Faraday rotation measurements, IEEE Transact. Antennas Propagat., 24 (1976), 253–255. |
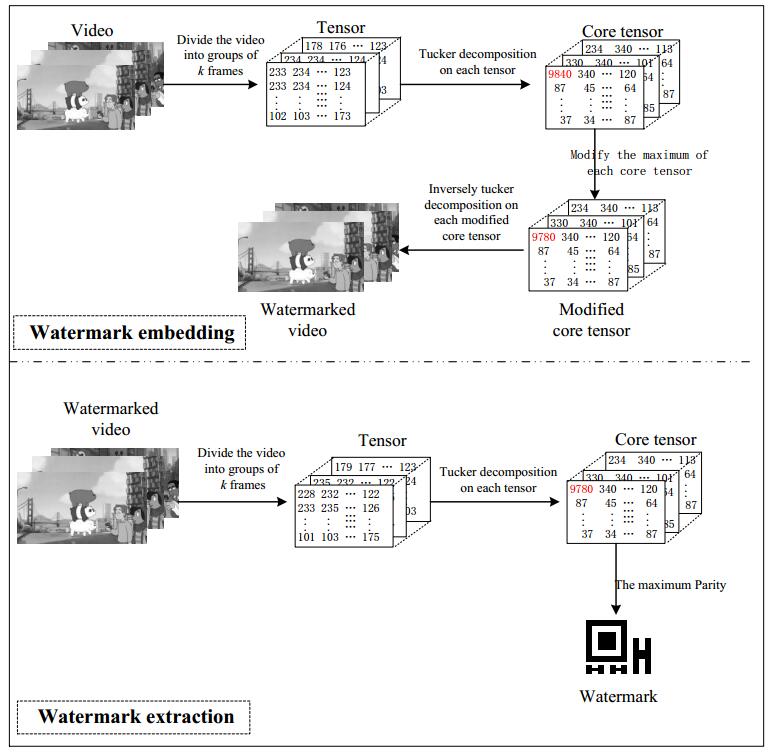
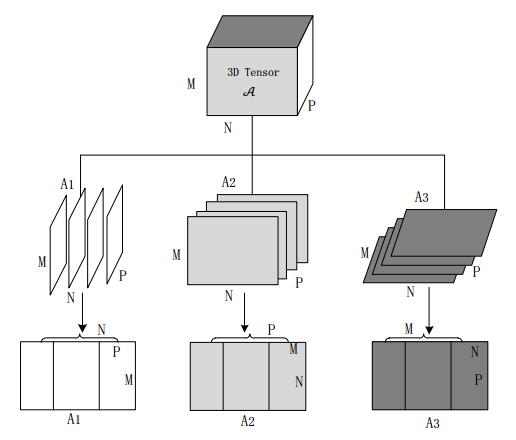
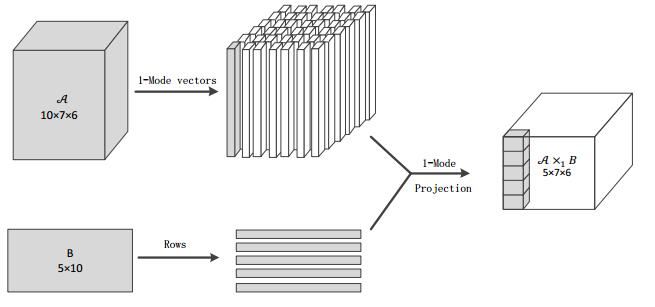
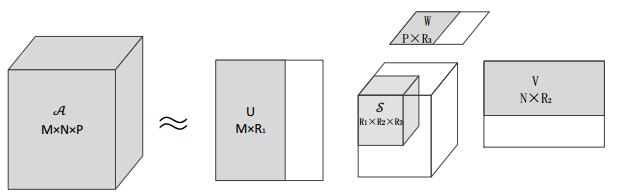


Figures(10) / Tables(4)

Shanqing Zhang, Xiaoyun Guo, Xianghua Xu, Li Li, Chin-Chen Chang. A video watermark algorithm based on tensor decomposition[J]. Mathematical Biosciences and Engineering, 2019, 16(5): 3435-3449. doi: 10.3934/mbe.2019172







 DownLoad:
DownLoad: