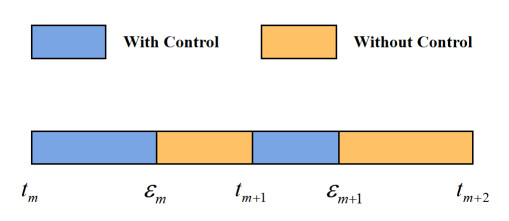
In this paper, the exponential bipartite consensus issue is investigated for multi-agent networks, whose dynamic is characterized by fractional diffusion partial differential equations (PDEs). The main contribution is that a novel exponential convergence principle is proposed for networks of fractional PDEs via aperiodically intermittent control scheme. First, under the aperiodically intermittent control strategy, an exponential convergence principle is developed for continuously differentiable function. Second, on the basis of the proposed convergence principle and the designed intermittent boundary control protocol, the exponential bipartite consensus condition is addressed in the form of linear matrix inequalities (LMIs). Compared with the existing works, the result of the exponential intermittent consensus presented in this paper is applied to the networks of PDEs. Finally, the high-speed aerospace vehicle model is applied to verify the effectiveness of the control protocol.
Citation: Xinxin Zhang, Huaiqin Wu. Bipartite consensus for multi-agent networks of fractional diffusion PDEs via aperiodically intermittent boundary control[J]. Mathematical Biosciences and Engineering, 2023, 20(7): 12649-12665. doi: 10.3934/mbe.2023563
In this paper, the exponential bipartite consensus issue is investigated for multi-agent networks, whose dynamic is characterized by fractional diffusion partial differential equations (PDEs). The main contribution is that a novel exponential convergence principle is proposed for networks of fractional PDEs via aperiodically intermittent control scheme. First, under the aperiodically intermittent control strategy, an exponential convergence principle is developed for continuously differentiable function. Second, on the basis of the proposed convergence principle and the designed intermittent boundary control protocol, the exponential bipartite consensus condition is addressed in the form of linear matrix inequalities (LMIs). Compared with the existing works, the result of the exponential intermittent consensus presented in this paper is applied to the networks of PDEs. Finally, the high-speed aerospace vehicle model is applied to verify the effectiveness of the control protocol.

| [1] |
C. Tomlin, G. J. Pappas, S. Sastry, Conflict resolution for air traffic management: a study in multiagent hybrid systems, IEEE Trans. Autom. Control, 43 (1998), 509–521. https://doi.org/10.1109/9.664154 doi: 10.1109/9.664154

|
| [2] |
Y. Zou, H. J. Zhang, W He, Adaptive coordinated formation control of heterogeneous vertical takeoff and landing UAVs subject to parametric uncertainties, IEEE Trans. Cybern., 52 (2022), 3184–3195. https://doi.org/10.1109/TCYB.2020.3009404 doi: 10.1109/TCYB.2020.3009404
|
| [3] |
L. Cao, Y. Q. Chen, Z. D. Zhang, H. N. Li, A. K. Misra, Predictive smooth variable structure filter for attitude synchronization estimation during satellite formation flying, IEEE Trans. Aerosp. Electron. Syst., 53 (2017), 1375–1383. https://doi.org/10.1109/TAES.2017.2671118 doi: 10.1109/TAES.2017.2671118
|
| [4] |
R. Olfati-Saber, R. Murray, Consensus problems in networks of agents with switching topology and time-delays, IEEE Trans. Autom. Control, 49 (2004), 1520–1533. https://doi.org/10.1109/TAC.2004.834113 doi: 10.1109/TAC.2004.834113
|
| [5] |
G. H. Wen, W. X. Zheng, On constructing multiple lyapunov functions for tracking control of multiple agents with switching topologies, IEEE Trans. Autom. Control, 64 (2019), 3796–3803. https://doi.org/10.1109/TAC.2018.2885079 doi: 10.1109/TAC.2018.2885079
|
| [6] |
H. Q. Li, X. F. Liao, T. W. Huang, W. Zhu, Event-triggering sampling based leader-following consensus in second-order multi-agent systems, IEEE Trans. Autom. Control, 60 (2015), 1998–2003. https://doi.org/10.1109/TAC.2014.2365073 doi: 10.1109/TAC.2014.2365073
|
| [7] | S. Wasserman, K. Faust, Social Network Analysis: Methods and Applications, Cambridge University Press, 1994. |
| [8] |
C. Altafini, G. Lini, Predictable dynamics of opinion forming for networks with antagonistic interactions, IEEE Trans. Autom. Control, 60 (2015), 342–357. https://doi.org/10.1109/TAC.2014.2343371 doi: 10.1109/TAC.2014.2343371
|
| [9] |
C. Altafini, Consensus problems on networks with antagonistic interactions, IEEE Trans. Autom. Control, 58 (2013), 935–946. https://doi.org/10.1109/TAC.2012.2224251 doi: 10.1109/TAC.2012.2224251
|
| [10] |
A. H. Hu, Y. Y. Wang, J. D. Cao, A. Alsaedi, Event-triggered bipartite consensus of multi-agent systems with switching partial couplings and topologies, Inf. Sci., 521 (2020), 1–13. https://doi.org/10.1016/j.ins.2020.02.038 doi: 10.1016/j.ins.2020.02.038
|
| [11] |
P. Gong, Exponential bipartite consensus of fractional-order non-linear multi-agent systems in switching directed signed networks, IET Control Theory Appl., 14 (2020), 2582–2591. https://doi.org/10.1049/iet-cta.2019.1241 doi: 10.1049/iet-cta.2019.1241
|
| [12] |
M. Shahvali, A. Azarbahram, M. Naghibi-Sistani, J. Askari, Bipartite consensus control for fractional-order nonlinear multi-agent systems: An output constraint approach, Neurocomputing, 397 (2020), 212–223. https://doi.org/10.1016/j.neucom.2020.02.036 doi: 10.1016/j.neucom.2020.02.036
|
| [13] |
Y. Cheng, Y. H. Wu, B. Z. Guo, Absolute boundary stabilization for an axially moving Kirchhoff beam, Automatica, 129 (2021), 109667. https://doi.org/10.1016/j.automatica.2021.109667 doi: 10.1016/j.automatica.2021.109667
|
| [14] |
S. T. Le, Y. H. Wu, Y. Q. Guo, C. D. Vecchio, Game theoretic approach for a service function chain routing in NFV with coupled constraints, IEEE Trans. Circuits Syst. Ⅱ Express Briefs, 68 (2021), 3557–3561. https://doi.org/10.1109/TCSII.2021.3070025 doi: 10.1109/TCSII.2021.3070025
|
| [15] |
Y. Cheng, Y. H. Wu, B. Z. Guo, Boundary stability criterion for a nonlinear axially moving beam, IEEE Trans. Autom. Control, 67 (2022), 5714–5729. https://doi.org/10.1109/TAC.2021.3124754 doi: 10.1109/TAC.2021.3124754
|
| [16] |
X. N. Song, Q. Y. Zhang, M. Wang, S. Song, Distributed estimation for nonlinear PDE systems using space-sampling approach: applications to high-speed aerospace vehicle, Nonlinear Dyn., 106 (2021), 3183–3198. https://doi.org/10.1007/s11071-021-06725-4 doi: 10.1007/s11071-021-06725-4
|
| [17] |
A. Pilloni, A. Pisano, Y. Orlov, E. Usai, Consensus-based control for a network of diffusion PDEs with boundary local interaction, IEEE Trans. Autom. Control, 61 (2016), 2708–2713. https://doi.org/10.1109/TAC.2015.2506990 doi: 10.1109/TAC.2015.2506990
|
| [18] |
P. He, Consensus of uncertain parabolic PDE agents via adaptive unit-vector control scheme, IET Control Theory Appl., 12 (2018), 2488–2494. https://doi.org/10.1049/iet-cta.2018.5202 doi: 10.1049/iet-cta.2018.5202
|
| [19] |
Y. N. Chen, Z. Q. Zuo, Y. J. Wang, Bipartite consensus for a network of wave PDEs over a signed directed graph, Automatica, 129 (2021), 109640. https://doi.org/10.1016/j.automatica.2021.109640 doi: 10.1016/j.automatica.2021.109640
|
| [20] |
L. R. Zhao, H. Q. Wu, J. D. Cao, Finite/fixed-time bipartite consensus for networks of diffusion PDEs via event-triggered control, Inf. Sci., 609 (2022), 1435–1450. https://doi.org/10.1016/j.ins.2022.07.151 doi: 10.1016/j.ins.2022.07.151
|
| [21] |
X. H. Wang, H. Q. Wu, J. D. Cao, Global leader-following consensus in finite time for fractional-order multi-agent systems with discontinuous inherent dynamics subject to nonlinear growth, Nonlinear Anal. Hybrid Syst, 37 (2020), 100888. https://doi.org/10.1016/j.nahs.2020.100888 doi: 10.1016/j.nahs.2020.100888
|
| [22] |
Y. Q. Zhang, H. Q. Wu, J. D. Cao, Global mittag-leffler consensus for fractional singularly perturbed multi-agent systems with discontinuous inherent dynamics via event-triggered control strategy, J. Franklin Inst., 358 (2021), 2086–2114. https://doi.org/10.1016/j.jfranklin.2020.12.033 doi: 10.1016/j.jfranklin.2020.12.033
|
| [23] |
Y. Q. Zhang, H. Q. Wu, J. D. Cao, Group consensus in finite time for fractional multiagent systems with discontinuous inherent dynamics subject to h$\ddot{o}$lder growth, IEEE Trans. Cybern., 52 (2022), 4161–4172. https://doi.org/10.1109/TCYB.2020.3023704 doi: 10.1109/TCYB.2020.3023704
|
| [24] |
X. N. Li, H. Q. Wu, J. D. Cao, Prescribed-time synchronization in networks of piecewise smooth systems via a nonlinear dynamic event-triggered control strategy, Math. Comput. Simul., 203 (2023), 647–668. https://doi.org/10.1016/j.matcom.2022.07.010 doi: 10.1016/j.matcom.2022.07.010
|
| [25] |
H. G. Zhang, Z. Y. Gao, Y. C. Wang, Y. L. Cai, Leader-following exponential consensus of fractional-order descriptor multiagent systems with distributed event-triggered strategy, IEEE Trans. Syst. Man Cybern.: Syst., 52 (2022), 3967–3979. https://doi.org/10.1109/TSMC.2021.3082549 doi: 10.1109/TSMC.2021.3082549
|
| [26] |
P. Gong, Exponential bipartite consensus of fractional-order non-linear multi-agent systems in switching directed signed networks, IET Control Theory Appl., 14 (2020), 2582–2591. https://doi.org/10.1049/iet-cta.2019.1241 doi: 10.1049/iet-cta.2019.1241
|
| [27] |
B. Mbodje, G. Montseny, Boundary fractional derivative control of the wave equation, IEEE Trans. Autom. Control, 40 (1995), 378–382. https://doi.org/10.1109/9.341815 doi: 10.1109/9.341815
|
| [28] | F. D. Ge, Y. Q. Chen, Event-driven boundary control for time fractional diffusion systems under time-varying input disturbance, in 2018 Annual American Control Conference (ACC), (2018), 140–145. https://doi.org/10.23919/ACC.2018.8431000 |
| [29] |
F. D. Ge, Y. Q. Chen, C. H. Kou, Boundary feedback stabilisation for the time fractional-order anomalous diffusion system, IET Control Theory Appl., 10 (2018), 1250–1257. https://doi.org/10.1049/iet-cta.2015.0882 doi: 10.1049/iet-cta.2015.0882
|
| [30] |
Y. Cao, Y. G. Kao, J. H. Park, H. B. Bao, Global Mittag-Leffler stability of the delayed fractional-coupled reaction-diffusion system on networks without strong connectedness, IEEE Trans. Neural Networks Learn. Syst., 33 (2021), 6473–6483. https://doi.org/10.1109/TNNLS.2021.3080830 doi: 10.1109/TNNLS.2021.3080830
|
| [31] |
J. D. Cao, G. Stamov, I. Stamova, S. Simeonov, Almost periodicity in impulsive fractional-order reaction-diffusion neural networks with time-varying delays, IEEE Trans. Cybern., 51 (2021), 151–161. https://doi.org/10.1109/TCYB.2020.2967625 doi: 10.1109/TCYB.2020.2967625
|
| [32] |
J. H. Qin, G. S. Zhang, W. X. Zheng, Y. Kang, Adaptive sliding mode consensus tracking for second-order nonlinear multiagent systems with actuator faults, IEEE Trans. Cybern., 49 (2019), 1605–1615. https://doi.org/10.1109/TCYB.2018.2805167 doi: 10.1109/TCYB.2018.2805167
|
| [33] |
J. Sun, C. Guo, L. Liu, Q. H. Shan, Adaptive consensus control of second-order nonlinear multi-agent systems with event-dependent intermittent communications, J. Franklin Inst., 360 (2023), 2289–2306. https://doi.org/10.1016/j.jfranklin.2022.10.045 doi: 10.1016/j.jfranklin.2022.10.045
|
| [34] |
J. Wang, M. Krstic, Output-feedback boundary control of a heat PDE sandwiched between two ODEs, IEEE Trans. Autom. Control, 64 (2019), 4653–4660. https://doi.org/10.1109/TAC.2019.2901704 doi: 10.1109/TAC.2019.2901704
|
| [35] |
J. Sun, Z. S. Wang, Event-triggered consensus control of high-order multi-agent systems with arbitrary switching topologies via model partitioning approach, Neurocomputing, 413 (2020), 14–22. https://doi.org/10.1016/j.neucom.2020.06.058 doi: 10.1016/j.neucom.2020.06.058
|
| [36] |
X. Z. Liu, K. N. Wu, Z. T. Li, Exponential stabilization of reaction-diffusion systems via intermittent boundary control, IEEE Trans. Autom. Control, 67 (2022), 3036–3042. https://doi.org/10.1109/TAC.2021.3100289 doi: 10.1109/TAC.2021.3100289
|
| [37] |
X. Z. Liu, K. N. Wu, W. H. Zhang, Intermittent boundary stabilization of stochastic reaction-diffusion Cohen -Grossberg neural networks, Neural Networks, 131 (2020), 1–13. https://doi.org/10.1016/j.neunet.2020.07.019 doi: 10.1016/j.neunet.2020.07.019
|
| [38] |
X. Y. Li, Q. L. Fan, X. Z. Liu, K. N. Wu, Boundary intermittent stabilization for delay reaction-diffusion cellular neural networks, Neural Comput. Appl., 34 (2022), 18561–18577. https://doi.org/10.1007/s00521-022-07457-1 doi: 10.1007/s00521-022-07457-1
|
| [39] |
N. Espitia, A. Polyakov, D. Efimov, W. Perruquetti, Boundary time-varying feedbacks for fixed-time stabilization of constant-parameter reaction-diffusion systems, Automatica, 103 (2019), 398–407. https://doi.org/10.1016/j.automatica.2019.02.013 doi: 10.1016/j.automatica.2019.02.013
|
| [40] |
T. Hashimoto, M. Krstic, Stabilization of reaction-diffusion equations with state delay using boundary control input, IEEE Trans. Autom. Control, 61 (2016), 4041–4047. https://doi.org/10.1109/TAC.2016.2539001 doi: 10.1109/TAC.2016.2539001
|
| [41] |
C. Prieur, E. Tr$\acute{e}$lat, Feedback stabilization of a 1-D linear reaction-diffusion equation with delay boundary control, IEEE Trans. Autom. Control, 64 (2019), 1415–1425. https://doi.org/10.1109/TAC.2018.2849560 doi: 10.1109/TAC.2018.2849560
|
| [42] |
J. Sun, Z. S. Wang, Consensus of multi-agent systems with intermittent communications via sampling time unit approach, Neurocomputing, 397 (2020), 149–159. https://doi.org/10.1016/j.neucom.2020.02.055 doi: 10.1016/j.neucom.2020.02.055
|
| [43] |
Z. S. Wang, J. Sun, H. G. Zhang, Stability analysis of T-S fuzzy control system with sampled-dropouts based on time-varying Lyapunov function method, IEEE Trans. Syst. Man Cybern.: Syst., 50 (2020), 2566–2577. https://doi.org/10.1109/TSMC.2018.2822482 doi: 10.1109/TSMC.2018.2822482
|
| [44] |
Z. B. Wang, H. Q. Wu, Stabilization in finite time for fractional-order hyperchaotic electromechanical gyrostat systems, Mech. Syst. Signal Proc., 111 (2018), 628–642. https://doi.org/10.1016/j.ymssp.2018.04.009 doi: 10.1016/j.ymssp.2018.04.009
|
| [45] |
C. D. Yang, T. W. Huang, A. C. Zhang, J. L. Qiu, J. D. Cao, F. E. Alsaadi, Output consensus of multiagent systems based on PDEs with input constraint: A boundary control approach, IEEE Trans. Syst. Man Cybern.: Syst., 51 (2021), 370–377. https://doi.org/10.1109/TSMC.2018.2871615 doi: 10.1109/TSMC.2018.2871615
|
| [46] |
P. Gong, Q. L. Han, W. Y. Lan, Finite-time consensus tracking for incommensurate fractional-order nonlinear multiagent systems with directed switching topologies, IEEE Trans. Cybern., 52 (2022), 65–76. https://doi.org/10.1109/TCYB.2020.2977169 doi: 10.1109/TCYB.2020.2977169
|
| [47] |
S. Q. Zhang, Monotone method for initial value problem for fractional diffusion equation, Sci. China Ser. A: Math., 49 (2006), 1223–1230. https://doi.org/10.1007/s11425-006-2020-6 doi: 10.1007/s11425-006-2020-6
|
| [48] |
V. Yadav, R. Padhi, S. N. Balakrishnan, Robust/optimal temperature profile control of a high-speed aerospace vehicle using neural networks, IEEE Trans. Neural Networks, 18 (2007), 1115–1128. https://doi.org/10.1109/TNN.2007.899229 doi: 10.1109/TNN.2007.899229
|






Figures(7) / Tables(1)

Xinxin Zhang, Huaiqin Wu. Bipartite consensus for multi-agent networks of fractional diffusion PDEs via aperiodically intermittent boundary control[J]. Mathematical Biosciences and Engineering, 2023, 20(7): 12649-12665. doi: 10.3934/mbe.2023563







 DownLoad:
DownLoad: