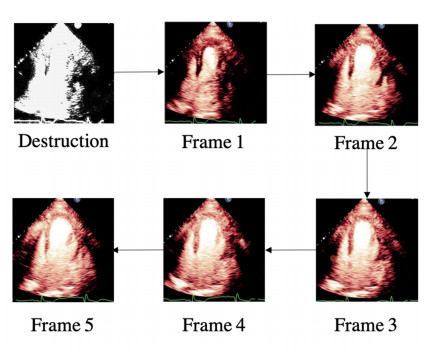
Myocardial contrast echocardiography (MCE) has been proposed as a method to assess myocardial perfusion for the detection of coronary artery diseases in a non-invasive way. As a critical step of automatic MCE perfusion quantification, myocardium segmentation from the MCE frames faces many challenges due to the low image quality and complex myocardial structure. In this paper, a deep learning semantic segmentation method is proposed based on a modified DeepLabV3+ structure with an atrous convolution and atrous spatial pyramid pooling module. The model was trained separately on three chamber views (apical two-chamber view, apical three-chamber view, and apical four-chamber view) on 100 patients' MCE sequences, divided by a proportion of 7:3 into training and testing datasets. The results evaluated by using the dice coefficient (0.84, 0.84, and 0.86 for three chamber views respectively) and Intersection over Union(0.74, 0.72 and 0.75 for three chamber views respectively) demonstrated the better performance of the proposed method compared to other state-of-the-art methods, including the original DeepLabV3+, PSPnet, and U-net. In addition, we conducted a trade-off comparison between model performance and complexity in different depths of the backbone convolution network, which illustrated model application feasibility.
Citation: Huan Cheng, Jucheng Zhang, Yinglan Gong, Zhaoxia Pu, Jun Jiang, Yonghua Chu, Ling Xia. Semantic segmentation method for myocardial contrast echocardiogram based on DeepLabV3+ deep learning architecture[J]. Mathematical Biosciences and Engineering, 2023, 20(2): 2081-2093. doi: 10.3934/mbe.2023096
Myocardial contrast echocardiography (MCE) has been proposed as a method to assess myocardial perfusion for the detection of coronary artery diseases in a non-invasive way. As a critical step of automatic MCE perfusion quantification, myocardium segmentation from the MCE frames faces many challenges due to the low image quality and complex myocardial structure. In this paper, a deep learning semantic segmentation method is proposed based on a modified DeepLabV3+ structure with an atrous convolution and atrous spatial pyramid pooling module. The model was trained separately on three chamber views (apical two-chamber view, apical three-chamber view, and apical four-chamber view) on 100 patients' MCE sequences, divided by a proportion of 7:3 into training and testing datasets. The results evaluated by using the dice coefficient (0.84, 0.84, and 0.86 for three chamber views respectively) and Intersection over Union(0.74, 0.72 and 0.75 for three chamber views respectively) demonstrated the better performance of the proposed method compared to other state-of-the-art methods, including the original DeepLabV3+, PSPnet, and U-net. In addition, we conducted a trade-off comparison between model performance and complexity in different depths of the backbone convolution network, which illustrated model application feasibility.

| [1] |
M. Dewey, M. Siebes, M. Kachelriess, K. Kofoed, P. Maurovich-Horvat, K. Nikolaou, et al., Clinical quantitative cardiac imaging for the assessment of myocardial ischaemia, Nat. Rev. Cardiol., 17 (2020), 427–450. http://dx.doi.org/10.1038/s41569-020-0341-8 doi: 10.1038/s41569-020-0341-8

|
| [2] |
G. Q. Du, J. Y. Xue, Y. Guo, S. Chen, P. Du, Y. Wu, et al., Measurement of myocardial perfusion and infarction size using computer-aided diagnosis system for myocardial contrast echocardiography, Ultrasound Med. Biol., 41 (2015), 2466–2477. https://doi.org/10.1016/j.ultrasmedbio.2015.04.012 doi: 10.1016/j.ultrasmedbio.2015.04.012
|
| [3] |
Y. Guo, G. Q. Du, W. Q. Shen, C. Du, P. He, S. Siuly, Automatic myocardial infarction detection in contrast echocardiography based on polar residual network, Comput. Methods Programs Biomed., 198 (2021), 105791. https://doi.org/10.1016/j.cmpb.2020.105791 doi: 10.1016/j.cmpb.2020.105791
|
| [4] |
J. Cho, S. Her, H. Youn, C. Kim, M. Park, G. Kim, et al., Usefulness of the parameters of quantitative myocardial perfusion contrast echocardiography in patients with chronic total occlusion and collateral flow, Echocardiography, 32 (2015), 475–482. https://doi.org/10.1111/echo.12663 doi: 10.1111/echo.12663
|
| [5] |
T. Rutz, S. F. de Marchi, P. Roelli, S. Gloekler, T. Traupe, H. Steck, et al., Quantitative myocardial contrast echocardiography: a new method for the non-invasive detection of chronic heart transplant rejection, Eur. Heart J. Cardiovasc. Imaging, 14 (2014), 1187–1194. https://doi.org/10.1093/ehjci/jet066 doi: 10.1093/ehjci/jet066
|
| [6] |
A. L. Klibanov, P. T Rasche, M. S. Hughes, J. K. Wojdyla, K. P. Galen, J. H.Wible, et al., Detection of individual microbubbles of ultrasound contrast agents: imaging of free-floating and targeted bubbles, Invest. Radiol., 39 (2004), 187–195. https://doi.org/10.1097/01.rli.0000115926.96796.75 doi: 10.1097/01.rli.0000115926.96796.75
|
| [7] |
M. X. Tang, H. Mulvana, T. Gauthier, A. Lim, D. Cosgrove, R. Eckersley, et al., Quantitative contrast-enhanced ultrasound imaging: a review of sources of variability, Interface Focus, 1 (2011), 520–539. http://doi.org/10.1098/rsfs.2011.0026 doi: 10.1098/rsfs.2011.0026
|
| [8] |
M. Kass, A. Witkin, D. Terzopoulos, Snakes: Active contour models, Int. J. Comput. Vision, 1 (1988), 321–331. https://doi.org/10.1007/BF00133570 doi: 10.1007/BF00133570
|
| [9] |
T. F. Cootes, C. J. Taylor, D. H. Cooper, J. Graham, Active shape models-their training and application, Comput. Vision Image Understanding, 61 (1995), 38–59. https://doi.org/10.1006/cviu.1995.1004 doi: 10.1006/cviu.1995.1004
|
| [10] | N. Malpica, M. Ledesma-Carbayo, A. Santos, E. Perez-David, M. Garcia-Fernandez, M. Desco, A coupled active contour model for myocardial tracking in contrast echocardiography, Image Understanding and Anal., 2004 (2004). |
| [11] | J. E. Pickard, J. A. Hossack, S. T. Acton, Shape model segmentation of long-axis contrast enhanced echocardiography, in 3rd IEEE International Symposium on Biomedical Imaging: Nano to Macro, (2006), 1112–1115. https://doi.org/10.1109/ISBI.2006.1625117 |
| [12] |
Y. Guo, G. Du, J. Xue, R. Xia, Y. Wang, A novel myocardium segmentation approach based on neutrosophic active contour model, Comput. Methods Programs Biomed., 142 (2017), 109–116. https://doi.org/10.1016/j.cmpb.2017.02.020 doi: 10.1016/j.cmpb.2017.02.020
|
| [13] |
Y. Li, C. Ho, M. Toulemonde, N. Chahal, R. Senior, M. Tang, Fully automatic myocardial segmentation of contrast echocardiography sequence using random forests guided by shape model, IEEE Trans. Med. Imaging, 37 (2017), 1081–1091. https://doi.org/10.1109/tmi.2017.2747081 doi: 10.1109/tmi.2017.2747081
|
| [14] | N. Azarmehr, X. Ye, S. Sacchi, J. Howard, D. Francis, M. Zolgharni, Segmentation of left ventricle in 2D echocardiography using deep learning, in Annual Conference on Medical Image Understanding and Analysis, (2019), 497–504. https://doi.org/10.1007/978-3-030-39343-4_43 |
| [15] | G. Veni, M. Moradi, H. Bulu, G. Narayan, T. Syeda-Mahmood, Echocardiography segmentation based on a shape-guided deformable model driven by a fully convolutional network prior, in 2018 IEEE 15th International Symposium on Biomedical Imaging, (2018), 898–902. https://doi.org/10.1109/ISBI.2018.8363716 |
| [16] | Y. Hu, L. Guo, B. Lei, M. Mao, Z. Jin, A. Elazab, et al., Fully automatic pediatric echocardiography segmentation using deep convolutional networks based on BiSeNet, in 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), (2019), 6561–6564. https://doi.org/10.1109/EMBC.2019.8856457 |
| [17] |
M. Li, D. Zeng, Q. Xie, R. Xu, Y. Wang, D. Ma, et al., A deep learning approach with temporal consistency for automatic myocardial segmentation of quantitative myocardial contrast echocardiography, Int. J. Cardiovasc. Imaging, 37 (2021), 1967–1978. https://doi.org/10.1007/s10554-021-02181-8 doi: 10.1007/s10554-021-02181-8
|
| [18] | L. Chen, Y. Zhu, G. Papandreou, F. Schroff, H. Adam, Encoder-decoder with atrous separable convolution for semantic image segmentationm, preprint, arXiv: 1802.02611. |
| [19] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, preprint, arXiv: 1512.03385. |
| [20] | T. He, Z. Zhang, H. Zhang, Z. Zhang, J. Xie, M. Li, Bag of tricks for image classification with convolutional neural networks, preprint, arXiv: 1812.01187. |
| [21] | F. Yu, V. Koltun, Multi-scale context aggregation by dilated convolutions, preprint, arXiv: 1511.07122. |
| [22] | L. Chen, Y. Zhu, G. Papandreou, F. Schroff, H. Adam, Rethinking atrous convolution for semantic image segmentation, preprint, arXiv: 1706.05587. |
| [23] | F. Milletari, N. Navab, S. Ahmadi, V-net: Fully convolutional neural networks for volumetric medical image segmentation, in 2016 fourth international conference on 3D vision (3DV), (2016), 565–571. https://doi.org/10.1109/3DV.2016.79 |
| [24] | H. Zhao, J. Shi, X. Qi, X. Wang, J. Jia, Pyramid scene parsing network, preprint, arXiv: 1612.01105. |
| [25] | O. Ronneberger, P. Fischer, T. Brox, U-net: Convolutional networks for biomedical image segmentation, in International Conference on Medical Image Computing and Computer-Assisted Intervention, (2015), 234–241. https://doi.org/10.1007/978-3-319-24574-4_28 |







Figures(8) / Tables(3)

Huan Cheng, Jucheng Zhang, Yinglan Gong, Zhaoxia Pu, Jun Jiang, Yonghua Chu, Ling Xia. Semantic segmentation method for myocardial contrast echocardiogram based on DeepLabV3+ deep learning architecture[J]. Mathematical Biosciences and Engineering, 2023, 20(2): 2081-2093. doi: 10.3934/mbe.2023096







 DownLoad:
DownLoad: