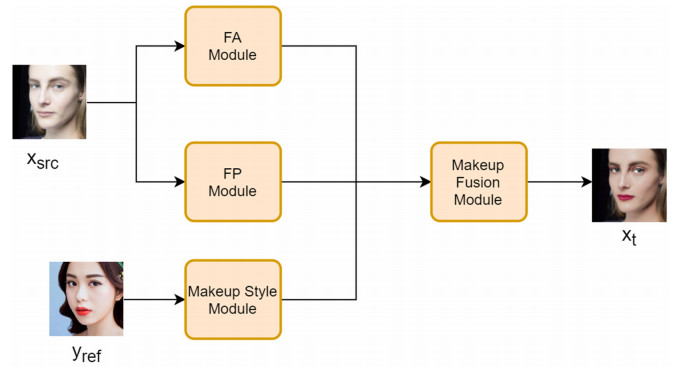
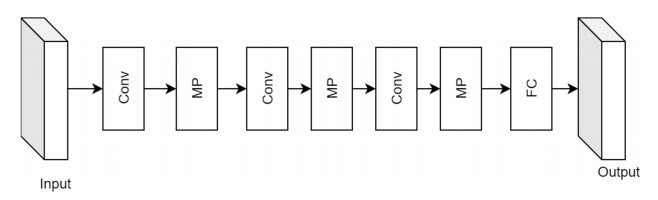
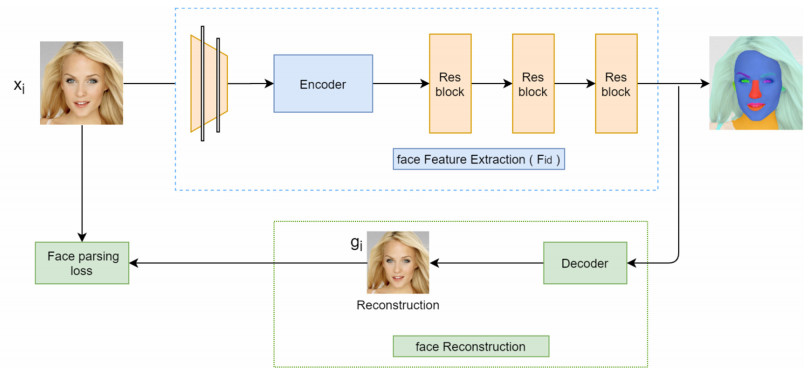
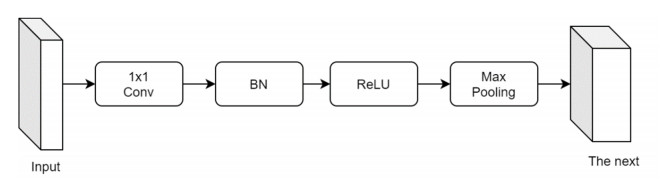
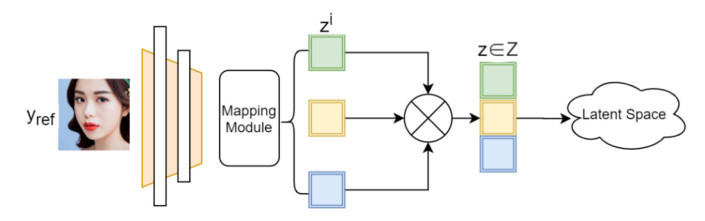
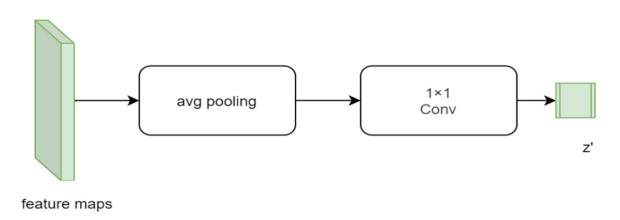
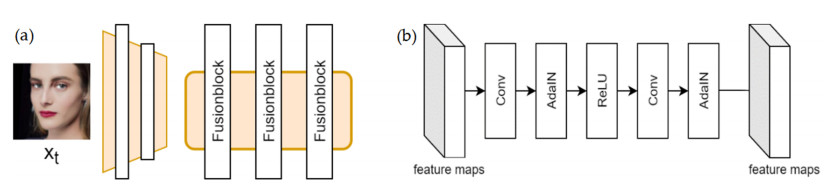
Facial makeup transfer is a special form of image style transfer. For the reference makeup image with large-pose, improving the quality of the image generated after makeup transfer is still a challenging problem worthy of discussion. In this paper, a large-pose makeup transfer algorithm based on generative adversarial network (GAN) is proposed. First, a face alignment module (FAM) is introduced to locate the key points, such as the eyes, mouth and skin. Secondly, a face parsing module (FPM) and face parsing losses are designed to analyze the source image and extract the face features. Then, the makeup style code is extracted from the reference image and the makeup transfer is completed through integrating facial features and makeup style code. Finally, a large-pose makeup transfer (LPMT) dataset is collected and constructed. Experiments are carried out on the traditional makeup transfer (MT) dataset and the new LPMT dataset. The results show that the image quality generated by the proposed method is better than that of the latest method for large-pose makeup transfer.
Citation: Qiming Li, Tongyue Tu. Large-pose facial makeup transfer based on generative adversarial network combined face alignment and face parsing[J]. Mathematical Biosciences and Engineering, 2023, 20(1): 737-757. doi: 10.3934/mbe.2023034
Facial makeup transfer is a special form of image style transfer. For the reference makeup image with large-pose, improving the quality of the image generated after makeup transfer is still a challenging problem worthy of discussion. In this paper, a large-pose makeup transfer algorithm based on generative adversarial network (GAN) is proposed. First, a face alignment module (FAM) is introduced to locate the key points, such as the eyes, mouth and skin. Secondly, a face parsing module (FPM) and face parsing losses are designed to analyze the source image and extract the face features. Then, the makeup style code is extracted from the reference image and the makeup transfer is completed through integrating facial features and makeup style code. Finally, a large-pose makeup transfer (LPMT) dataset is collected and constructed. Experiments are carried out on the traditional makeup transfer (MT) dataset and the new LPMT dataset. The results show that the image quality generated by the proposed method is better than that of the latest method for large-pose makeup transfer.

| [1] | W. S. Tong, C. K. Tang, M. S. Brown, Y. Q. Xu, Example-based cosmetic transfer, in 15th Pacific Conference on Computer Graphics and Applications (PG'07), (2007), 211-218. https://doi.org/10.1109/PG.2007.31 |
| [2] | S. Liu, X. Ou, R. Qian, W. Wang, X. Cao, Makeup like a superstar: deep localized makeup transfer network, preprint, arXiv: 1604.07102. |
| [3] | D. Guo, T. Sim, Digital face makeup by example, in 2009 IEEE Conference on Computer Vision and Pattern Recognition, (2009), 73-79. https://doi.org/10.1109/CVPR.2009.5206833 |
| [4] | L. Xu, Y. Du, Y. Zhang, An automatic framework for example-based virtual makeup, in 2013 IEEE International Conference on Image Processing, (2013), 3206-3210. https://doi.org/10.1109/ICIP.2013.6738660 |
| [5] | C. Li, K. Zhou, S. Lin, Simulating makeup through physics-based manipulation of intrinsic image layers, in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2015), 4621-4629. https://doi.org/10.1109/CVPR.2015.7299093 |
| [6] | W. Xu, C. Long, R. Wang, G. Wang, DRB-GAN: A dynamic resblock generative adversarial network for artistic style transfer, in 2021 IEEE/CVF International Conference on Computer Vision (ICCV), (2021), 6383-6392. https://doi.org/10.1109/ICCV48922.2021.00632 |
| [7] | H. Chen, L. Zhao, H. Zhang, Z. Wang, Z. Zuo, A. Li, et al., Diverse image style transfer via invertible cross-space mapping, in 2021 IEEE/CVF International Conference on Computer Vision (ICCV), (2021), 14860-14869. https://doi.org/10.1109/ICCV48922.2021.01461 |
| [8] | Y. Hou, L. Zheng, Visualizing adapted knowledge in domain transfer, in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2021), 13824-13833. https://doi.org/10.1109/CVPR46437.2021.01361 |
| [9] | X. Zhang, Z. Cheng, X. Zhang, H. Liu, Posterior promoted GAN with distribution discrimi-nator for unsupervised image synthesis, in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2021), 6519-6528. https://doi.org/10.1109/CVPR46437.2021.00645 |
| [10] | P. Wang, Y. Li, N. Vasconcelos, Rethinking and improving the robustness of image style transfer, in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2021), 124-133. https://doi.org/10.1109/CVPR46437.2021.00019 |
| [11] | J. Y. Zhu, T. Park, P. Isola, A. A. Efros, Unpaired image-to-image translation using cycle-consistent adversarial networks, in 2017 IEEE International Conference on Computer Vision (ICCV), (2017), 2223-2232. https://doi.org/10.1109/ICCV.2017.244 |
| [12] | H. Chang, J. Lu, F. Yu, A. Finkelstein, Pairedcyclegan: Asymmetric style transfer for applying and removing makeup, in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2018), 40-48. https://doi.org/10.1109/CVPR.2018.00012 |
| [13] | H. J. Chen, K. M. Hui, S. Y. Wang, L. W. Tsao, H. H. Shuai, W. H. Cheng, Beautyglow: On-demand makeup transfer framework with reversible generative network, in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 10042-10050. https://doi.org/10.1109/CVPR.2019.01028 |
| [14] | T. Li, R. Qian, C. Dong, S. Liu, Q. Yan, W. Zhu, et al., Beautygan: Instance-level facial makeup transfer with deep generative adversarial network, in Proceedings of the 26th ACM international conference on Multimedia, (2018), 645-653. https://doi.org/10.1145/3240508.3240618 |
| [15] | T. Nguyen, A. T. Tran, M. Hoai, Lipstick ain't enough: beyond color matching for in-the-wild makeup transfer, in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2021), 13305-13314. https://doi.org/10.1109/cvpr46437.2021.01310 |
| [16] | Z. Sun, Y. Chen, S. Xiong, SSAT: A symmetric semantic-aware transformer network for makeup transfer and removal, in Proceedings of the AAAI Conference on Artificial Intelligence, 36 (2022), 2325-2334. https://doi.org/10.1609/aaai.v36i2.20131 |
| [17] | Z. Huang, Z. Zheng, C. Yan, H. Xie, Y. Sun, J. Wang, et al., Real-world automatic makeup via identity preservation makeup net, in International Joint Conferences on Artificial Intelligence Organization, (2020), 652-658. https://doi.org/10.24963/ijcai.2020/91 |
| [18] | Z. Wan, H. Chen, J. An, W. Jiang, C. Yao, J. Luo, et al., Facial attribute transformers for precise and robust makeup transfer, in 2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), (2022), 1717-1726. https://doi.org/10.1109/wacv51458.2022.00317 |
| [19] | J. Lee, E. Kim, Y. Lee, D. Kim, J. Chang, J. Choo, Reference-based sketch image colorization using augmented-self reference and dense semantic correspondence, in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2020), 5800–5809. https://doi.org/10.1109/cvpr42600.2020.00584 |
| [20] | W. Jiang, S. Liu, C. Gao, J. Cao, R. He, J. Feng, et al., Psgan: Pose and expression robust spatial-aware gan for customizable makeup transfer, in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2020), 5194–5202. https://doi.org/10.1109/CVPR42600.2020.00524 |
| [21] | A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, et al., Attention is all you need, in Advances in Neural Information Processing Systems, 30 (2017), 5998-6008. |
| [22] | H. Deng, C. Han, H. Cai, G. Han, S. He, Spatially-invariant style-codes controlled makeup transfer, in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2021), 6549-6557. https://doi.org/10.1109/CVPR46437.2021.00648 |
| [23] |
K. Zhang, Z. Zhang, Z. Li, Y. Qiao, Joint face detection and alignment using multitask cascaded convolutional networks, IEEE Signal Process Lett., 23 (2016), 1499-1503. https://doi.org/10.1109/LSP.2016.2603342 doi: 10.1109/LSP.2016.2603342

|
| [24] | Y. Wang, J. M. Solomon, Prnet: Self-supervised learning for partial-to-partial registration, in 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), 32 (2019), 8812-8824. Available from: https://proceedings.neurips.cc/paper/2019/file/ebad33b3c9fa1d10327bb55f9e79e2f3-Paper.pdf. |
| [25] | K. Simonyan, A. Zisserman, Very deep convolutional networks for large-scale image recognition, preprint, arXiv: 1409.1556. |
| [26] | D. P. Kingma, P. Dhariwal, Glow: Generative flow with invertible 1x1 convolutions, in 32nd Conference on Neural Information Processing Systems (NeurIPS 2018), 31 (2018), 10236-10245. Available from: https://proceedings.neurips.cc/paper/2018/file/d139db6a236200b21cc7f752979132d0-Paper.pdf. |
| [27] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2016), 770-778. https://doi.org/10.1109/CVPR.2016.90 |
| [28] | C. Yu, J. Wang, C. Peng, C. Gao, G. Yu, N. Sang, Bisenet: Bilateral segmentation network for real-time semantic segmentation, in Computer Vision – ECCV 2018, 11217 (2018), 334-349. https://doi.org/10.1007/978-3-030-01261-8_20 |
| [29] | T. Karras, S. Laine, T. Aila, A style-based generator architecture for generative adversarial networks, in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 4401-4410. https://doi.org/10.1109/CVPR.2019.00453 |
| [30] | X. Huang, S. Belongie, Arbitrary style transfer in real-time with adaptive instance normalization, in 2017 IEEE International Conference on Computer Vision (ICCV), (2017), 1501-1510. https://doi.org/10.1109/ICCV.2017.167 |
| [31] | I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, et al., Generative adversarial nets, in Proceedings of the 27th International Conference on Neural Information Processing Systems, 2 (2014), 2672–2680. https://dl.acm.org/doi/10.5555/2969033.2969125 |
| [32] | J. Johnson, A. Alahi, L. Fei-Fei, Perceptual losses for real-time style transfer and super-resolution, in Computer Vision – ECCV 2016, 9906 (2016), 694-711. https://doi.org/10.1007/978-3-319-46475-6_43 |
| [33] | D. P. Kingma, J. Ba, Adam: a method for stochastic optimization, preprint, arXiv: 1412.6980. |
| [34] | Y. Lyu, J. Dong, B. Peng, W. Wang, T. Tan, SOGAN: 3D-aware shadow and occlusion robust GAN for makeup transfer, in Proceedings of the 29th ACM International Conference on Multimedia, (2021), 3601-3609. https://doi.org/10.1145/3474085.3475531 |
| [35] | J. Liao, Y. Yao, L. Yuan, G. Hua, S. B. Kang, Visual attribute transfer through deep image analogy, preprint, arXiv: 1705.01088. |
| [36] | Q. Gu, G. Wang, M. T. Chiu, Y. W. Tai, C. K. Tang, Ladn: Local adversarial disentangling network for facial makeup and de-makeup, in 2019 IEEE/CVF International Conference on Computer Vision (ICCV), (2019), 10481-10490. https://doi.org/10.1109/ICCV.2019.01058 |
| [37] | B. Yan, Q. Lin, W. Tan, S. Zhou, Assessing eye aesthetics for automatic multi-reference eye in-painting, in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2020), 13509-13517. https://doi.org/10.1109/CVPR42600.2020.01352 |









Figures(16) / Tables(2)

Qiming Li, Tongyue Tu. Large-pose facial makeup transfer based on generative adversarial network combined face alignment and face parsing[J]. Mathematical Biosciences and Engineering, 2023, 20(1): 737-757. doi: 10.3934/mbe.2023034







 DownLoad:
DownLoad: