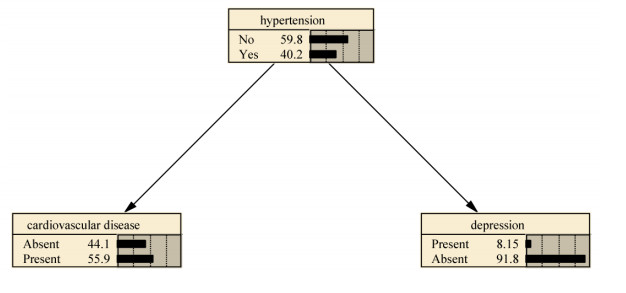
Stroke is a major chronic non-communicable disease with high incidence, high mortality, and high recurrence. To comprehensively digest its risk factors and take some relevant measures to lower its prevalence is of great significance. This study aimed to employ Bayesian Network (BN) model with Max-Min Hill-Climbing (MMHC) algorithm to explore the risk factors for stroke. From April 2019 to November 2019, Shanxi Provincial People's Hospital conducted opportunistic screening for stroke in ten rural areas in Shanxi Province. First, we employed propensity score matching (PSM) for class balancing for stroke. Afterwards, we used Chi-square testing and Logistic regression model to conduct a preliminary analysis of risk factors for stroke. Statistically significant variables were incorporated into BN model construction. BN structure learning was achieved using MMHC algorithm, and its parameter learning was achieved with Maximum Likelihood Estimation. After PSM, 748 non-stroke cases and 748 stroke cases were included in this study. BN was built with 10 nodes and 12 directed edges. The results suggested that age, fasting plasma glucose, systolic blood pressure, and family history of stroke constitute direct risk factors for stroke, whereas sex, educational levels, high density lipoprotein cholesterol, diastolic blood pressure, and urinary albumin-to-creatinine ratio represent indirect risk factors for stroke. BN model with MMHC algorithm not only allows for a complicated network relationship between risk factors and stroke, but also could achieve stroke risk prediction through Bayesian reasoning, outshining traditional Logistic regression model. This study suggests that BN model boasts great prospects in risk factor detection for stroke.
Citation: Wenzhu Song, Lixia Qiu, Jianbo Qing, Wenqiang Zhi, Zhijian Zha, Xueli Hu, Zhiqi Qin, Hao Gong, Yafeng Li. Using Bayesian network model with MMHC algorithm to detect risk factors for stroke[J]. Mathematical Biosciences and Engineering, 2022, 19(12): 13660-13674. doi: 10.3934/mbe.2022637
Stroke is a major chronic non-communicable disease with high incidence, high mortality, and high recurrence. To comprehensively digest its risk factors and take some relevant measures to lower its prevalence is of great significance. This study aimed to employ Bayesian Network (BN) model with Max-Min Hill-Climbing (MMHC) algorithm to explore the risk factors for stroke. From April 2019 to November 2019, Shanxi Provincial People's Hospital conducted opportunistic screening for stroke in ten rural areas in Shanxi Province. First, we employed propensity score matching (PSM) for class balancing for stroke. Afterwards, we used Chi-square testing and Logistic regression model to conduct a preliminary analysis of risk factors for stroke. Statistically significant variables were incorporated into BN model construction. BN structure learning was achieved using MMHC algorithm, and its parameter learning was achieved with Maximum Likelihood Estimation. After PSM, 748 non-stroke cases and 748 stroke cases were included in this study. BN was built with 10 nodes and 12 directed edges. The results suggested that age, fasting plasma glucose, systolic blood pressure, and family history of stroke constitute direct risk factors for stroke, whereas sex, educational levels, high density lipoprotein cholesterol, diastolic blood pressure, and urinary albumin-to-creatinine ratio represent indirect risk factors for stroke. BN model with MMHC algorithm not only allows for a complicated network relationship between risk factors and stroke, but also could achieve stroke risk prediction through Bayesian reasoning, outshining traditional Logistic regression model. This study suggests that BN model boasts great prospects in risk factor detection for stroke.

| [1] |
C. M. Stinear, C. E. Lang, S. Zeiler, W. D. Byblow, Advances and challenges in stroke rehabilitation, Lancet Neurol., 19 (2020), 348-360. https://doi.org/10.1016/S1474-4422(19)30415-6 doi: 10.1016/S1474-4422(19)30415-6

|
| [2] |
C. Iadecola, M. S. Buckwalter, J. Anrather, Immune responses to stroke: mechanisms, modulation, and therapeutic potential, J. clin. invest., 130 (2020), 2777-2788. https://doi.org/10.1172/JCI135530 doi: 10.1172/JCI135530
|
| [3] |
S. Wu, B. Wu, M. Liu, Z. Chen, W. Wang, C. S. Anderson, et al., Stroke in China: advances and challenges in epidemiology, prevention, and management, Lancet Neurol., 18 (2019), 394-405. https://doi.org/10.1016/S1474-4422(18)30500-3 doi: 10.1016/S1474-4422(18)30500-3
|
| [4] |
W. Wang, B. Jiang, H. Sun, X. Ru, D. Sun, L. Wang, et al., Prevalence, incidence, and mortality of stroke in China: results from a nationwide population-based survey of 480 687 adults, Circulation, 135 (2017), 759-771. https://doi.org/10.1161/CIRCULATIONAHA.116.025250 doi: 10.1161/CIRCULATIONAHA.116.025250
|
| [5] |
X. Xia, W. Yue, B. Chao, M. Li, L. Cao, L. Wang, et al., Prevalence and risk factors of stroke in the elderly in Northern China: data from the National Stroke Screening Survey, J. Neurol., 266 (2019), 1449-1458. https://doi.org/10.1007/s00415-019-09281-5 doi: 10.1007/s00415-019-09281-5
|
| [6] |
Y. Wu, Y. Fang, Stroke prediction with machine learning methods among older Chinese, Int. J. Environ. Res. Public Health, 17 (2020), 1828. https://doi.org/10.3390/ijerph17061828 doi: 10.3390/ijerph17061828
|
| [7] |
A. Aigner, U. Grittner, A. Rolfs, B. Norrving, B. Siegerink, M. A. Busch, Contribution of established stroke risk factors to the burden of stroke in young adults, Stroke, 48 (2017), 1744-1751. https://doi.org/10.1161/STROKEAHA.117.016599 doi: 10.1161/STROKEAHA.117.016599
|
| [8] |
Y. Dong, W. Cao, X. Cheng, K. Fang, X. Zhang, Y. Gu, et al., Risk factors and stroke characteristic in patients with postoperative strokes, J. Stroke Cerebrovasc. Dis., 26 (2017), 1635-1640. https://doi.org/10.1016/j.jstrokecerebrovasdis.2016.12.017 doi: 10.1016/j.jstrokecerebrovasdis.2016.12.017
|
| [9] |
Z. Wei, X. L. Zhang, H. X. Rao, H. F. Wang, X. Wang, L. X. Qiu, Using the Tabu-search-algorithm-based Bayesian network to analyze the risk factors of coronary heart diseases, Chin. J. Epidemiol., 37 (2016), 895-899. https://doi.org/10.3760/cma.j.issn.0254-6450.2016.06.031 doi: 10.3760/cma.j.issn.0254-6450.2016.06.031
|
| [10] |
S. J. Moe, J. F. Carriger, M. Glendell, Increased use of bayesian network models has improved environmental risk assessments, Integr. Environ. Assess. Manage., 17 (2021), 53-61. https://doi.org/10.1002/ieam.4369 doi: 10.1002/ieam.4369
|
| [11] |
A. Frolova, B. Wilczyński, Distributed Bayesian networks reconstruction on the whole genome scale, PeerJ, 6 (2018), e5692. https://doi.org/10.7717/peerj.5692 doi: 10.7717/peerj.5692
|
| [12] |
J. Pan, H. Rao, X. Zhang, W. Li, Z. Wei, Z. Zhang, et al., Application of a Tabu search-based Bayesian network in identifying factors related to hypertension, Medicine, 98 (2019), e16058. https://doi.org/10.1097/MD.0000000000016058 doi: 10.1097/MD.0000000000016058
|
| [13] |
D. Quan, J. Ren, H. Ren, L. Linghu, X. Wang, M. Li, et al., Exploring influencing factors of chronic obstructive pulmonary disease based on elastic net and Bayesian network, Sci. Rep., 12 (2022), 7563. https://doi.org/10.1038/s41598-022-11125-8 doi: 10.1038/s41598-022-11125-8
|
| [14] |
Z. Xu, D. Shen, T. Nie, Y. Kou, A hybrid sampling algorithm combining M-SMOTE and ENN based on Random forest for medical imbalanced data, J. Biomed. Inf., 107 (2020), 103465. https://doi.org/10.1016/j.jbi.2020.103465 doi: 10.1016/j.jbi.2020.103465
|
| [15] |
M. S. Pathan, A Nag, M. M. Pathan, S. Dev, Analyzing the impact of feature selection on the accuracy of heart disease prediction, Healthcare Anal., 2 (2022), 100060. https://doi.org/10.1016/j.health.2022.100060 doi: 10.1016/j.health.2022.100060
|
| [16] |
S. Dev, H. Wang, C. S. Nwosu, N. Jain, B. Veeravalli, D. John, A predictive analytics approach for stroke prediction using machine learning and neural networks, Healthcare Anal., 2 (2022), 100032. https://doi.org/10.1016/j.health.2022.100032 doi: 10.1016/j.health.2022.100032
|
| [17] |
L. T. Kane, T. Fang, M. S. Galetta, D. K. C. Goyal, K. J. Nicholson, C. K. Kepler, et al., Propensity score matching: a statistical method, Clin. Spine Surg., 33 (2020), 120-122. https://doi.org/10.1097/BSD.0000000000000932 doi: 10.1097/BSD.0000000000000932
|
| [18] |
J. Liang, Z. Hu, C. Zhan, Q. Wang, Using propensity score matching to balance the baseline characteristics, J. Thorac. Oncol., 16 (2021), E45-E46. https://doi.org/10.1016/j.jtho.2020.11.030 doi: 10.1016/j.jtho.2020.11.030
|
| [19] |
E. Park, H. J. Chang, H. S. Nam, A Bayesian network model for predicting post-stroke outcomes with available risk factors, Front. Neurol., 9 (2018), 699. https://doi.org/10.3389/fneur.2018.00699 doi: 10.3389/fneur.2018.00699
|
| [20] |
D. E. da Cunha Leme, The use of Bayesian network models to identify factors related to frailty phenotype and health outcomes in middle-aged and older persons, Arch. Gerontol. Geriatr., 92 (2021), 104212. https://doi.org/10.1016/j.archger.2020.104212 doi: 10.1016/j.archger.2020.104212
|
| [21] |
X. Wang, J. Pan, Z. Ren, M. Zhai, Z. Zhang, H. Ren, et al., Application of a novel hybrid algorithm of Bayesian network in the study of hyperlipidemia related factors: a cross-sectional study, BMC Public Health, 21 (2021), 1375. https://doi.org/10.1186/s12889-021-11412-5 doi: 10.1186/s12889-021-11412-5
|
| [22] |
Y. Huang, L. Gao, X. Xie, S. C. Tan, Epidemiology of dyslipidemia in Chinese adults: meta-analysis of prevalence, awareness, treatment, and control, Popul. Health Metrics, 12 (2014), 1-9. https://doi.org/10.1186/s12963-014-0028-7 doi: 10.1186/s12963-014-0028-7
|
| [23] |
L. P. Zhao, T. You, S. P. Chan, J. C. Chen, W. T. Xu, Adropin is associated with hyperhomocysteine and coronary atherosclerosis, Exp. Ther. Med., 11 (2016), 1065-1670. https://doi.org/10.3892/etm.2015.2954 doi: 10.3892/etm.2015.2954
|
| [24] |
Z. Wang, Z. Chen, L. Zhang, X. Wang, G. Hao, Z. Zhang, et al., Status of hypertension in China: results from the China hypertension survey, 2012-2015, Circulation. 137 (2018):2344-2356. https://doi.org/10.1161/CIRCULATIONAHA.117.032380 doi: 10.1161/CIRCULATIONAHA.117.032380
|
| [25] |
N. Shi, K. Liu, Y. Fan, L. Yang, S. Zhang, X. Li, et al., The association between obesity and risk of acute kidney injury after cardiac surgery, Front. Endocrinol., 11 (2020), 534294. https://doi.org/10.3389/fendo.2020.534294 doi: 10.3389/fendo.2020.534294
|
| [26] |
P. Arora, D. Boyne, J. J. Slater, A. Gupta, D. R. Brenner, M. J. Druzdzel, Bayesian networks for risk prediction using real-world data: a tool for precision medicine, Value health, 22 (2019):439-445. https://doi.org/10.1016/j.jval.2019.01.006 doi: 10.1016/j.jval.2019.01.006
|
| [27] |
Y. Dimitrov, M. Ducher, M. Kribs, G. Laurent, S. Richter, J. P. Fauvel, Variables linked to hepatitis B vaccination success in non-dialyzed chronic kidney disease patients: use of a bayesian model, Nephrol. Ther., 15 (2019), 215-219. https://doi.org/10.1016/j.nephro.2019.02.010 doi: 10.1016/j.nephro.2019.02.010
|
| [28] |
C. S. Anderson, Progress-defining risk factors for stroke prevention, Cerebrovasc. Dis., 50 (2021), 615-616. https://doi.org/10.1159/000516996 doi: 10.1159/000516996
|
| [29] |
W. Qi, J. Ma, T. Guan, D. Zhao, A. Abu-Hanna, M. Schut, et al., Risk factors for incident stroke and its subtypes in China: a prospective study, J. Am. Heart Assoc., 9 (2020), e016352. https://doi.org/10.1161/JAHA.120.016352 doi: 10.1161/JAHA.120.016352
|
| [30] | C. S. Nwosu, S. Dev, P. Bhardwaj, B. Veeravalli, D. John, Predicting stroke from electronic health records, in 2019 41st Annual International Conference of the IEEE Engineering in Medicine and Biology Society, IEEE, Berlin, Germany, (2019), 5704-5707. https://doi.org/10.1109/EMBC.2019.8857234 |
| [31] |
M. S. Pathan, Z. Jianbiao, D. John, A. Nag, S. Dev. Identifying stroke indicators using rough sets, IEEE Access, 8 (2020), 210318-210327, https://doi.org/10.1109/ACCESS.2020.3039439 doi: 10.1109/ACCESS.2020.3039439
|
| [32] |
M. N. Cocchi, J. A. Edlow, Managing hypertension in patients with acute stroke, Ann. Emerg. Med. 75 (2020), 767-771. https://doi.org/10.1016/j.annemergmed.2019.09.015 doi: 10.1016/j.annemergmed.2019.09.015
|
| [33] |
Y. C. Cheng, J. M. Sheen, W. L. Hu, Y. C. Hung. Polyphenols and oxidative stress in atherosclerosis-related ischemic heart disease and stroke, Oxid. Med. Cell. Longevity, 2017 (2017), 8526438. https://doi.org/10.1155/2017/8526438 doi: 10.1155/2017/8526438
|
| [34] |
S. N. Bhupathiraju, F. B. Hu, Epidemiology of obesity and diabetes and their cardiovascular complications, Circ. Res., 118 (2016), 1723-1735. https://doi.org/10.1161/CIRCRESAHA.115.306825 doi: 10.1161/CIRCRESAHA.115.306825
|
| [35] |
F. Denorme, I. Portier, Y. Kosaka, R. A. Campbell, Hyperglycemia exacerbates ischemic stroke outcome independent of platelet glucose uptake, J. Thromb. Haemostasis, 19 (2021), 536-546. https://doi.org/10.1111/jth.15154 doi: 10.1111/jth.15154
|
| [36] |
S. L. Stevens, S. Wood, C. Koshiaris, K. Law, P. Glasziou, R. J. Stevens, et al., Blood pressure variability and cardiovascular disease: systematic review and meta-analysis, BMJ, 354 (2016), i4098. https://doi.org/10.1136/bmj.i4098 doi: 10.1136/bmj.i4098
|
| [37] |
X. Zheng, N. Zeng, A. Wang, Z. Zhu, H. Peng, C. Zhong, et al., Family history of stroke and death or vascular events within one year after ischemic stroke, Neurol. Res., 41 (2019), 466-472. https://doi.org/10.1080/01616412.2019.1577342 doi: 10.1080/01616412.2019.1577342
|
 MBE-19-12-637-supplementary.pdf MBE-19-12-637-supplementary.pdf |
 |


Figures(3) / Tables(2)

Wenzhu Song, Lixia Qiu, Jianbo Qing, Wenqiang Zhi, Zhijian Zha, Xueli Hu, Zhiqi Qin, Hao Gong, Yafeng Li. Using Bayesian network model with MMHC algorithm to detect risk factors for stroke[J]. Mathematical Biosciences and Engineering, 2022, 19(12): 13660-13674. doi: 10.3934/mbe.2022637







 DownLoad:
DownLoad: