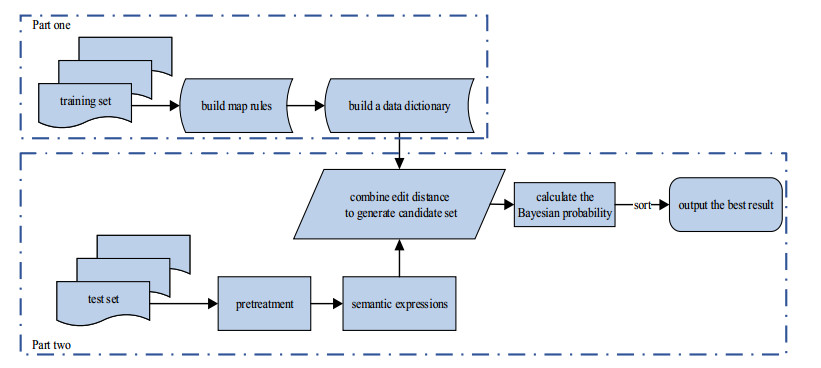
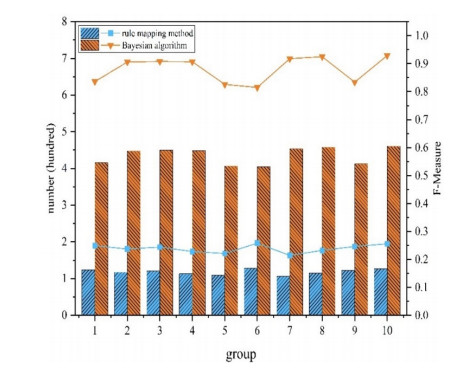
The semantic information of mathematical expressions plays an important role in information retrieval and similarity calculation. However, a large number of presentational expressions in the presentation MathML format contained in electronic scientific documents do not reflect semantic information. It is a shortcut to extract semantic information using the rule mapping method to convert presentational expressions in presentation MathML format into semantic expressions in the content MathML format. However, the conversion result is prone to semantic errors because the expressions in the two formats do not have exact correspondences in grammatical structures and markups. In this study, a Bayesian error correction algorithm is proposed to correct the semantic errors in the conversion results of mathematical expressions based on the rule mapping method. In this study, the expressions in presentation MathML and content MathML in the NTCIR data set are used as the training set to optimize the parameters of the Bayesian model. The expressions in presentation MathML in the documents collected by the laboratory from the CNKI website are used as the test set to test the error correction results. The experimental results show that the average $ {F_1} $ value is 0.239 with the rule mapping method, and the average $ {F_1} $ value is 0.881 with the Bayesian error correction method, with the average error correction rate is 0.853.
Citation: Xue Wang, Fang Yang, Hongyuan Liu, Qingxuan Shi. Error correction of semantic mathematical expressions based on bayesian algorithm[J]. Mathematical Biosciences and Engineering, 2022, 19(6): 5428-5445. doi: 10.3934/mbe.2022255
The semantic information of mathematical expressions plays an important role in information retrieval and similarity calculation. However, a large number of presentational expressions in the presentation MathML format contained in electronic scientific documents do not reflect semantic information. It is a shortcut to extract semantic information using the rule mapping method to convert presentational expressions in presentation MathML format into semantic expressions in the content MathML format. However, the conversion result is prone to semantic errors because the expressions in the two formats do not have exact correspondences in grammatical structures and markups. In this study, a Bayesian error correction algorithm is proposed to correct the semantic errors in the conversion results of mathematical expressions based on the rule mapping method. In this study, the expressions in presentation MathML and content MathML in the NTCIR data set are used as the training set to optimize the parameters of the Bayesian model. The expressions in presentation MathML in the documents collected by the laboratory from the CNKI website are used as the test set to test the error correction results. The experimental results show that the average $ {F_1} $ value is 0.239 with the rule mapping method, and the average $ {F_1} $ value is 0.881 with the Bayesian error correction method, with the average error correction rate is 0.853.

| [1] |
P. Amarnath, P. Partha, G. Alexander, A formula embedding approach to math information retrieval, Comput. Y Sistemas, 22 (2018), 819-833. https://doi.org/10.13053/CyS-22-3-3015 doi: 10.13053/CyS-22-3-3015

|
| [2] |
T. Chih-Fong, K. Shih-Wen, M. Kenneth, M. Y. Lin, LocalContent: A personal scientific document retrieval system, Electr. Lib., 33 (2015), 373-385. https://doi.org/10.1108/EL-08-2013-0148 doi: 10.1108/EL-08-2013-0148
|
| [3] | W. Zhong, S. Rohatgi, J. Wu, C. L. Giles, R. Zanibbi, Accelerating substructure similarity search for formula retrieval, in Proceedings of the European Conference on Information Retrieval, (2020), 714-727. https://doi.org/10.1007/978-3-030-45439-5_47 |
| [4] | B. Mansouri, S. Rohatgi, D. W. Oard, J. Wu, R. Zanibbi, Tangent-CFT: an embedding model for mathematical formulas, in Proceedings of the ACM SIGIR International Conference on the Theory of Information Retrieval (ICTIR), 2019. https://doi.org/10.1145/3341981.3344235 |
| [5] |
S. Dhar, A. Biswas, N. Singh, SciMath: A mathematical information retrieval system using signature based B tree indexing, Int. J. Innovat. Technol. Explor. Eng., 8 (2019), 234-244. https://doi.org/10.35940/ijitee.K1298.0981119 doi: 10.35940/ijitee.K1298.0981119
|
| [6] |
Y. Nagao, N. Suzuki, Classifying mathML expressions by multilayer perceptron, IEICE Trans. Inf. Syst., E101 (2018), 1954-1958. https://doi.org/10.1587/transinf.2017edl8211 doi: 10.1587/transinf.2017edl8211
|
| [7] |
Y. P. Qin, J. N. Guo, A. H. Zhang, A novel extreme learning fault diagnosis based supervision applied to mathematical formula contrastive analysis, Neurocomputing, 177 (2016), 166-273. https://doi.org/10.1016/j.neucom.2015.11.027 doi: 10.1016/j.neucom.2015.11.027
|
| [8] | P. Sojka, M. Líška, M. Růžička, Building corpora of technical texts : Approaches and Tools, in the Proceedings of the Fifth Workshop on Recent Advances in Slavonic Natural Languages, 2011. Available from: https://www.fi.muni.cz/usr/sojka/papers/sojka-liska-ruzicka-raslan2011.pdf. |
| [9] | M. Růžička, P. Sojka, M. Líška, Math indexer and searcher under the hood: history and development of a winning strategy, in Proceedings of the 11th NTCIR Conference, 2014. Available from: http://research.nii.ac.jp/ntcir/workshop/OnlineProceedings11/pdf/NTCIR/Math-2/07-NTCIR11-MATH-RuzickaM.pdf. |
| [10] | N. Kando, T. Sakai, C. Clarke, NTCIR (NⅡ Testbeds and Community for Information access Research) Project, 2016. Available from: http://research.nii.ac.jp/ntcir/index-en.html. |
| [11] | Tsinghua University, Ltd., CNKI (China National Knowledge Infrastructure). https://www.cnki.net. |
| [12] |
T. Zhang, L. Li, W. Su, Y. J. Zhao, A mathematical formulae converter based on Math Edit, Comput. Appl. Software, 27 (2010), 14-16. https://doi.org/10.3969/j.issn.1000-386X.2010.01.006 doi: 10.3969/j.issn.1000-386X.2010.01.006
|
| [13] |
H. Sharaf, B. Samita, K. Shakeel, Rule based conversion of LaTeX math equation into Content MathML (CMML), J. Inf. Sc. Eng., 36 (2020), 1021-1034. https://doi.org/10.1109/ICSCC.2019.8843592 doi: 10.1109/ICSCC.2019.8843592
|
| [14] | S. Y. Zhu, L. Hu, R. Zanibbi, Rotation-robust math symbol recognition and retrieval using outer contours and image subsampling, in Proceedings of Society of Photo-optical Instrumentation Engineers (SPIE), 2013. https://doi.org/10.1117/12.2008383 |
| [15] | W. Su, Research on web-based input and accessibility of mathematical expressions, 2010. Available from: http://cdmd.cnki.com.cn/article/cdmd-10730-1011034166.htm. |
| [16] | M. Schubotz, A. Grenier-Petter, P. Scharpf, N. Meuschke, H. Cohl, B. Gipp, Improving the representation and conversion of mathematical formulae by considering their textual context, in Proceedings of the 18th ACM/IEEE on Joint Conference on Digital Libraries (JCDL), 2018. https://doi.org/10.1145/3197026.3197058 |
| [17] |
C. Cai, W. Su, L. Li, On key issues of converting presentation mathematics formulas to content, Comput. Appl. Software, 29 (2012), 30-33. https://doi.org/10.3969/j.issn.1000-386X.2012.08.008 doi: 10.3969/j.issn.1000-386X.2012.08.008
|
| [18] | I. A. Doush, F. Alkhateeb, E. A. Maghayreh, Towards meaningful mathematical expressions in e-learning, in Proceedings of the 1st International Conference on Intelligent Semantic Web-Services and Applications, 2013. https://dl.acm.org/doi/pdf/10.1145/1874590.1874612 |
| [19] |
M. Nghiem, G. Y. Kristianto, A. Aizawa, Using mathML parallel markup corpora for semantic enrichment of mathematical expressions, Ieice Trans. Inf. Syst., 96 (2013), 1707-1715. https://doi.org/10.1587/transinf.E96.D.1707 doi: 10.1587/transinf.E96.D.1707
|
| [20] | I. Toloaca, M. Kohlhase, Notation-based semantification, in Conference on Intelligent Computer Mathematics, 2016. Available from: http://ceur-ws.org/Vol-1785/M6.pdf. |
| [21] |
A. Greiner-Petter, M. Schubotz, H. Cohl, B. Gipp, Semantic preserving bijective mappings for expressions involving special functions in computer algebra systems and document preparation systems, Aslib J. Inf. Manage., 71 (2019). https://doi.org/10.1108/AJIM-08-2018-0185 doi: 10.1108/AJIM-08-2018-0185
|
| [22] | M. Grigore, M. Wolska, M. Kohlhase, Towards context-based disambiguation of mathematical expressions, Asian Symp. Comput. Math. Math. Aspects Comput. Inf. Sci., 2009. Available from: https://kwarc.info/people/mkohlhase/papers/ASCM-DML09.pdf. |
| [23] |
A. K. Nketia, W. H. Tian. Toward perfect neural cascading architecture for grammatical error correction, Appl. Intell., 51 (2021), 3775-3788. https://doi.org/10.1007/s10489-020-01980-1 doi: 10.1007/s10489-020-01980-1
|
| [24] |
S. Li, J. B. Zhao, G. R. Shi, Y. P. Tan, H. F. Xu, G. Chen, Chinese grammatical error correction based on convolutional sequence to sequence model, IEEE Access, 7(2019), 72905-72913. https://doi.org/10.1109/ACCESS.2019.2917631 doi: 10.1109/ACCESS.2019.2917631
|
| [25] |
H. Daniel, S. Jan, P. Matus, Survey of automatic spelling correction, Electronics, 9 (2020). https://doi.org/10.3390/electronics9101670 doi: 10.3390/electronics9101670
|
| [26] | Y. E. Jing, Analysis of grammar error correction algorithm based on deep learning technology, Inf. Technol., 9 (2020), 143-148. https://doi.org/CNKI:SUN:HDZJ.0.2020-09-031 |
| [27] |
J. M. Ye, D. X. Luo, S. Chen, A text error correction model based on hierarchical editing framework, Acta Electr. Sinica, 49 (2021), 401-407. https://doi.org/10.12263/DZXB.20200448 doi: 10.12263/DZXB.20200448
|
| [28] |
J. X. Gu, B. Yang, Survey on Bayesian optimization methodology and application, J. Software, 29 (2018), 3068-3090. https://doi.org/10.13328/j.cnki.jos.005607 doi: 10.13328/j.cnki.jos.005607
|
| [29] |
M. U. Sadiq, M. M. Yousaf, L. Aslam, M. Aleem, S. Sarwar, S. W. Jaffry, NvPD: novel parallel edit distance algorithm, correctness, and performance evaluation, Cluster Comput. J. Netw. Software Tools Appl., 23 (2020), 879-894. https://doi.org/10.1007/s10586-019-02962-w doi: 10.1007/s10586-019-02962-w
|
| [30] |
G. Z. Sun, J. W. Lv, H. K. Li, MeTCa: Multi-entity trusted confirmation algorithm based on edit distance, Comput. Sci., 47 (2020). https://doi.org/10.11896/jsjkx.191100176 doi: 10.11896/jsjkx.191100176
|
| [31] |
P. Ni, J. Li, H. Hao, Q. Han, X. Du, Probabilistic model updating via variational Bayesian inference and adaptive Gaussian process modeling, Comput. Methods Appl. Mechan. Eng., 383 (2021). https://doi.org/10.1016/j.cma.2021.113915 doi: 10.1016/j.cma.2021.113915
|
| [32] |
J. Zhao, X. Liu, S. Sun, Probabilistic inference of Bayesian neural networks with generalized expectation propagation, Neurocomputing, 412 (2020), 392-398, https://doi.org/10.1016/j.neucom.2020.06.060 doi: 10.1016/j.neucom.2020.06.060
|
| [33] | A. Rahman, U. Qamar, A Bayesian classifiers based combination model for automatic text classification, in Proceedings of the 7st IEEE International Conference on Software Engineering and Service Science, (2016), 63-67. https://doi.org/10.1109/ICSESS.2016.7883016 |
| [34] |
Y. Qussai, J. Yaser, K. N. Viet, An evaluation and analysis of static and adaptive Bayesian spam filters, J. Int. Technol., 19 (2018), 1015-1022. https://doi.org/10.3966/160792642018081904005 doi: 10.3966/160792642018081904005
|
| [35] |
J. Liu, Z. Wang, H. Wang, Research on spam filtering technology based on IMI-WNB algorithm, Comput. Eng., 46 (2020), 299-305. https://doi.org/10.19678/j.issn.1000-3428.0056577 doi: 10.19678/j.issn.1000-3428.0056577
|
| [36] |
A. N. Ngaffo, E. A. Walid, C. Zied, A Bayesian inference based hybrid recommender system, IEEE Access, 8 (2020). 101682-101701. https://doi.org/10.1109/ACCESS.2020.2998824 doi: 10.1109/ACCESS.2020.2998824
|
| [37] |
F. Y. Liu, X. Q. Gao, Z. Zhang, Improved Bayesian probabilistic model based recommender system, Comput. Sci., 44 (2017). https://doi.org/10.11896/j.issn.1002-137X.2017.05.052. doi: 10.11896/j.issn.1002-137X.2017.05.052
|
| [38] |
M. L. Zhan, L. Roger, K. Andrew, Pronoun interpretation in Mandarin Chinese follows principles of Bayesian inference, Plos One, 15 (2020). https://doi.org/10.1371/journal.pone.0237012 doi: 10.1371/journal.pone.0237012
|
| [39] | X. Yi, Y. U. Chen, Y. Shi, Bayesian method for intention prediction in pervasive computing environments, Scientia Sinica (Informationis), 2018. Available from: Available from: http://en.cnki.com.cn/Article_en/CJFDTotal-PZKX201804006.html. |
| [40] |
K. Jebran, L. S. Chang, Enhancement of sentiment analysis by utilizing noisy social media texts, J. Korean Inst. Commun. Inf. Sci., 45 (2020), 1027-1037. https://doi.org/10.7840/kics.2020.45.6.1027 doi: 10.7840/kics.2020.45.6.1027
|
| [41] | K. Chatterjee, T. A. Henzinger, R. Ibsen-Jensen, J. Otop, Edit distance for pushdown automata, in Inrernational Coloquium on Automata, Languages, and Programming, (2015), 121-133. https://doi.org/10.1007/978-3-662-47666-6_10 |
| [42] |
R. Romain, On the unification of the graph edit distance and graph matching problems, Pattern Recognit. Lett., 145(2021), 240-246. https://doi.org/10.48550/arXiv.2104.06186 doi: 10.48550/arXiv.2104.06186
|
Figures(4) / Tables(6)

Xue Wang, Fang Yang, Hongyuan Liu, Qingxuan Shi. Error correction of semantic mathematical expressions based on bayesian algorithm[J]. Mathematical Biosciences and Engineering, 2022, 19(6): 5428-5445. doi: 10.3934/mbe.2022255







 DownLoad:
DownLoad: