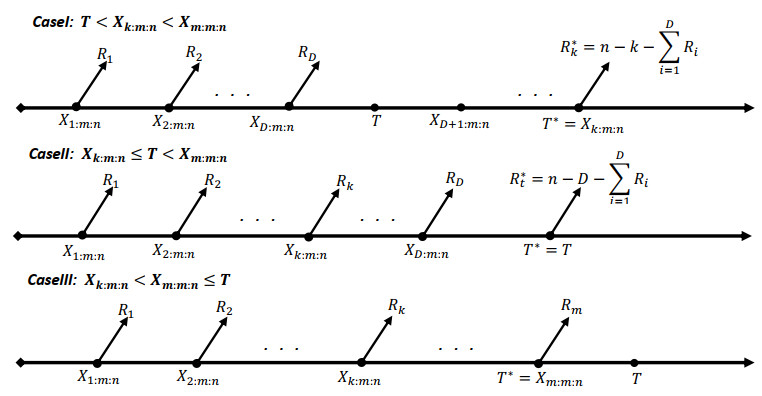
In this study, we estimate the unknown parameters, reliability, and hazard functions using a generalized Type-I progressive hybrid censoring sample from a Weibull distribution. Maximum likelihood (ML) and Bayesian estimates are calculated using a choice of prior distributions and loss functions, including squared error, general entropy, and LINEX. Unobserved failure point and interval Bayesian predictions, as well as a future progressive censored sample, are also developed. Finally, we run some simulation tests for the Bayesian approach and numerical example on real data sets using the MCMC algorithm.
Citation: M. Nagy, Adel Fahad Alrasheedi. The lifetime analysis of the Weibull model based on Generalized Type-I progressive hybrid censoring schemes[J]. Mathematical Biosciences and Engineering, 2022, 19(3): 2330-2354. doi: 10.3934/mbe.2022108
In this study, we estimate the unknown parameters, reliability, and hazard functions using a generalized Type-I progressive hybrid censoring sample from a Weibull distribution. Maximum likelihood (ML) and Bayesian estimates are calculated using a choice of prior distributions and loss functions, including squared error, general entropy, and LINEX. Unobserved failure point and interval Bayesian predictions, as well as a future progressive censored sample, are also developed. Finally, we run some simulation tests for the Bayesian approach and numerical example on real data sets using the MCMC algorithm.

| [1] | N. Balakrishnan, R. Aggarwala, Progressive censoring: theory, methods, and applications, Springer Science & Business Media, (2000). https://doi.org/10.1007/978-1-4612-1334-5. |
| [2] |
N. Balakrishnan, Progressive censoring methodology: An appraisal, Test, 16 (2007), 211–259. https://doi.org/10.1007/s11749-007-0061-y. doi: 10.1007/s11749-007-0061-y

|
| [3] |
E. Cramer, G. Iliopoulos, Adaptive progressive Type-II censoring, Test, 19 (2010), 342–358. https://doi.org/10.1007/s11749-009-0167-5. doi: 10.1007/s11749-009-0167-5
|
| [4] |
D. Kundu, A. Joarder, Analysis of Type-II progressively hybrid censored data, Comput. Stat. Data Anal., 50 (2006), 2509–2528. https://doi.org/10.1016/j.csda.2005.05.002. doi: 10.1016/j.csda.2005.05.002
|
| [5] | A. Childs, B. Chandrasekar, N. Balakrishnan, Exact likelihood inference for an exponential parameter under progressive hybrid censoring schemes, In: Statistical Models and Methods for Biomedical and Technical Systems, Birkhäuser Boston, (2008), 319–330. https://doi.org/10.1007/978-0-8176-4619-6_23. |
| [6] |
H. Panahi, Estimation methods for the generalized inverted exponential distribution under type II progressively hybrid censoring with application to spreading of micro-drops data, Commun. Math. Stat., 5 (2017), 159–174. https://doi.org/10.1007/s40304-017-0106-9. doi: 10.1007/s40304-017-0106-9
|
| [7] | R. Alshenawy, M. A. Sabry, E. M. Almetwally, H. M. Almongy, Product Spacing of Stress–Strength under Progressive Hybrid Censored for Exponentiated-Gumbel Distribution. Comput. Mater. Contin., 66 (2021), 2973–2995. doi$: $10.32604/cmc.2021.014289. |
| [8] |
F. Hemmati, E. Khorram, Statistical analysis of the log-normal distribution under Type-II progressive hybrid censoring schemes, Commun. Stat. Simul. Comput., 42 (2013), 52–75. https://doi.org/10.1080/03610918.2011.633195. doi: 10.1080/03610918.2011.633195
|
| [9] |
C. T. Lin, Y. L. Huang, On progressive hybrid censored exponential distribution, J. Stat. Comput. Simul., 82 (2012), 689–709. https://doi.org/10.1080/00949655.2010.550581. doi: 10.1080/00949655.2010.550581
|
| [10] |
Y. Cho, H. Sun, K. Lee, Exact likelihood inference for an exponential parameter under generalized progressive hybrid censoring scheme, Stat. Methodol., 23 (2015), 18–34. https://doi.org/10.1016/j.stamet.2014.09.002. doi: 10.1016/j.stamet.2014.09.002
|
| [11] |
M. M. El-Din, A. R. Shafay, M. Nagy, Statistical inference under adaptive progressive censoring scheme, Comput. Stat., 33 (2018), 31–74. https://doi.org/10.1007/s00180-017-0745-z. doi: 10.1007/s00180-017-0745-z
|
| [12] |
M. M. El-Din, M. Nagy, M. H. Abu-Moussa, Estimation and prediction for gompertz distribution under the generalized progressive hybrid censored data, Ann. Data Sci., 6 (2019), 673–705. https://doi.org/10.1007/s40745-019-00199-3. doi: 10.1007/s40745-019-00199-3
|
| [13] | M. Nagy, K. S. Sultan, M. H. Abu-Moussa, Analysis of the generalized progressive hybrid censoring from Burr Type-XII lifetime model. AIMS Math., 6 (2021), 9675–9704. doi$: $ 10.3934/math.2021564. |
| [14] | M. M. El-Din, M. Nagy, Estimation for Inverse Weibull distribution under Generalized Progressive Hybrid Censoring Scheme. J. Stat. Appl. Prob. Lett., 4 (2017), 1–11. doi$: $ org/10.18576/jsapl/paper. |
| [15] |
C. T. Lin, C. C. Chou, Y. L. Huang, Inference for the Weibull distribution with progressive hybrid censoring, Comput. Stat. Data Anal., 56 (2012), 451–467. https://doi.org/10.1016/j.csda.2011.09.002. doi: 10.1016/j.csda.2011.09.002
|
| [16] |
R. Calabria, G. Pulcini, Point estimation under asymmetric loss functions for left-truncated exponential samples, Commun. Stat. Theory Methods, 25 (1996), 585–600. https://doi.org/10.1080/03610929608831715. doi: 10.1080/03610929608831715
|
| [17] | W. H. Greene, Econometric analysis, Pearson Education India, (2003). https://spu.fem.uniag.sk |
| [18] | A. Agresti, Categorical data analysis, John Wiley & Sons, Inc, (2002). https://onlinelibrary.wiley.com/doi/book/10.1002/0471249688 |
| [19] | D. Kundu, Bayesian inference and life testing plan for the Weibull distribution in presence of progressive censoring. Technometrics, 50 (2008), 144–154. https://doi.org/10.1198/004017008000000217. |
| [20] |
N. Metropolis, A. W. Rosenbluth, M. N. Rosenbluth, A. H. Teller, E. Teller, Equation of state calculations by fast computing machines, J. Chem. Phys., 21 (1953), 1087–1092. https://doi.org/10.1063/1.1699114. doi: 10.1063/1.1699114
|
| [21] |
I. Basak, P. Basak, N. Balakrishnan, On some predictors of times to failure of censored items in progressively censored samples, Comput. Stat. Data Anal., 50 (2006), 1313–1337. https://doi.org/10.1016/j.csda.2005.01.011. doi: 10.1016/j.csda.2005.01.011
|
| [22] |
N. Balakrishnan, A. Childs, B. Chandrasekar, An efficient computational method for moments of order statistics under progressive censoring, Stat. Probab. Lett., 60 (2002), 359–365. https://doi.org/10.1016/S0167-7152(02)00267-5. doi: 10.1016/S0167-7152(02)00267-5
|
| [23] |
R. Viveros, N. Balakrishnan, Interval estimation of parameters of life from progressively censored data, Technometrics, 36 (1994), 84–91. https://doi.org/10.2307/1269201. doi: 10.2307/1269201
|
| [24] | W. Nelson, Applied life data analysis. Wiley, New York, (1982). doi$: $ 10.1002/0471725234. |
Figures(1) / Tables(10)

M. Nagy, Adel Fahad Alrasheedi. The lifetime analysis of the Weibull model based on Generalized Type-I progressive hybrid censoring schemes[J]. Mathematical Biosciences and Engineering, 2022, 19(3): 2330-2354. doi: 10.3934/mbe.2022108







 DownLoad:
DownLoad: