Citation: Siyu Chen, Yin Zhang, Yuhang Zhang, Jiajia Yu, Yanxiang Zhu. Embedded system for road damage detection by deep convolutional neural network[J]. Mathematical Biosciences and Engineering, 2019, 16(6): 7982-7994. doi: 10.3934/mbe.2019402

| [1] | E. Chuo, Research history and prospect of domestic pavement automatic detection system, China High-Tech. Enterp., 1 (2011), 1-3. |
| [2] | G. E. Hinton, S. Osindero and Y. W. Teh, A fast learning alg Comput., 18 (2006), 1527-1554. rithm for deep belief nets, Neural |
| [3] | L. Zhang, F. Yang, Y. D. Zhang, et al., Road crack detection using deep convolutional neural network, 2016 IEEE Int. Conf. Image Process. (ICIP), 3708-3712. |
| [4] |
H. Maeda, Y. Sekimoto, T. Seto, et al., Road damage detection using deep neural networks with images captured through a smartphone, Comput. Aided Civ. Infrastruct. Eng., 33 (2018), 1127-1141. doi: 10.1111/mice.12387

|
| [5] | W. Liu, D. Anguelov, D. Erhan, et al., SSD:Single shot multiBox detector, 2016 European Conf. Comput. Vision (ECCV), 21-37. |
| [6] | A. G. Howard, M. Zhu, B. Chen, et al., MobileNets:Efficient convolutional neural networks for mobile vision applications, preprint, arXiv:1704.04861. |
| [7] | A. He, Advantages of JG-1 laser 3D pavement inspection system, China Highw., 16 (2005), 94-95. |
| [8] | R. Girshick, J. Donahue, T. Darrell, et al., Rich feature hierarchies for accurate object detection and semantic segmentation, 2014 IEEE Conf. Comput. Vision Pattern 587. Recogn. (CVPR), 580-587 |
| [9] | S. Ren, K. He, R. Girshick, et al., Faster R-CNN:Towards real-time object detection with region Proposal networks, Adv. Neural Inf. Process. Syst., (2015), 91-99. |
| [10] | J. Redmon, S. Divvala, R. Girshick, et al., You only look once:Unified, Real-Time object detection, 2016 IEEE Conf. Comput. Vision Pattern Recogn. (CVPR), 779-788. |
| [11] | R. Joseph and A. Farhadi, YOLO v3:An incremental improvement, preprint, arXiv:1804.02767. |
| [12] | S. Karen and A. Zisserman, Very recognition, preprint, arXiv:1409.1556. deep convolutional networks for Large-Scale image |
| [13] | Z. Zhou, Model evaluating and selecting, in Machine Learn ng (eds. Zhihua Zhou), Tsinghua University Press, (2016), 23-52. |
| [14] | T. Lin, M. Maire, S. Belongie, et al., Microsoft COCO:Common objects in context, 2014 European Conf. Comput. Vision (ECCV), 740-755. |

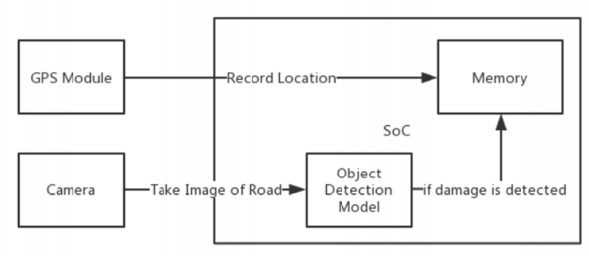

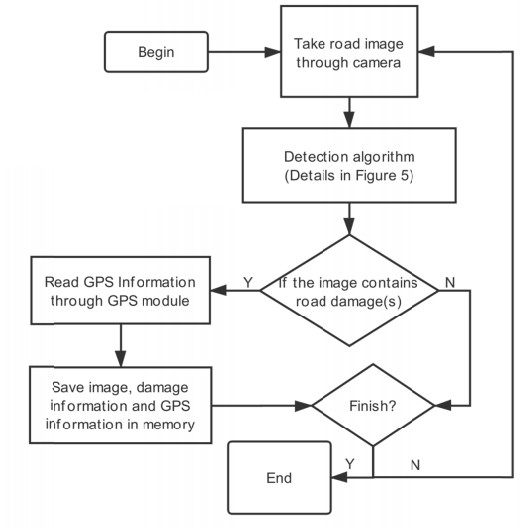






Figures(10) / Tables(2)

Siyu Chen, Yin Zhang, Yuhang Zhang, Jiajia Yu, Yanxiang Zhu. Embedded system for road damage detection by deep convolutional neural network[J]. Mathematical Biosciences and Engineering, 2019, 16(6): 7982-7994. doi: 10.3934/mbe.2019402







 DownLoad:
DownLoad: