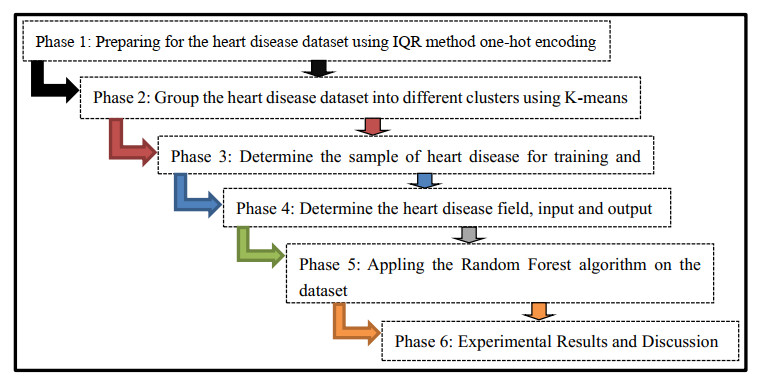
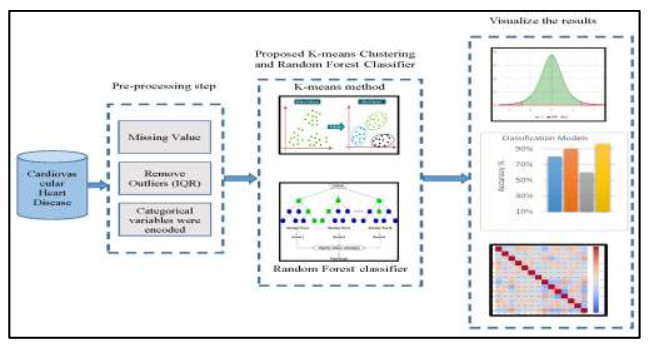
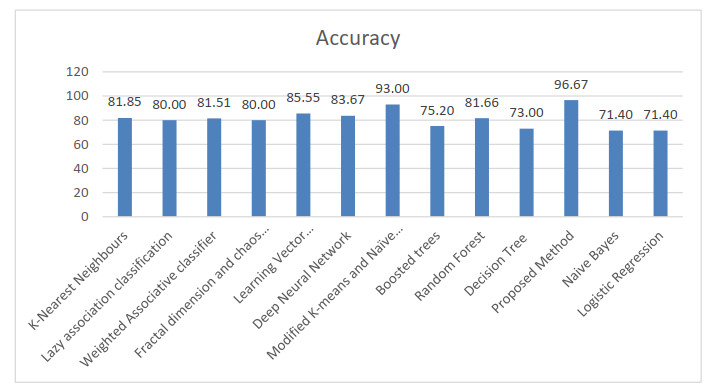
The ability to accurately anticipate heart failure risks in a timely manner is essential because heart failure has been identified as one of the leading causes of death. In this paper, we propose a novel method for identifying cardiovascular heart disease by utilizing a K-means clustering and Random Forest classifier combination. Based on their clinical and demographic traits, patients were classified into either healthy or diseased groups using the Random Forest classifier after being clustered using the K-means method. The performance of the proposed hybrid approach was evaluated using a dataset of patient records and compared with traditional diagnostic methods, namely support vector machine (SVM), logistic regression, and Naive Bayes classifiers. The outcomes indicated that the proposed hybrid method attained a high accuracy in diagnosing heart disease, with an overall accuracy of 96.8%. Additionally, the method showed a good performance in classifying patients at high risk of heart disease: the sensitivity reached 96.3% and the specificity reached 97.2%. In conclusion, the proposed method of combining K-means clustering and a Random Forest classifier is a promising approach for the accurate and efficient identification of heart disease. Further studies are needed to validate the proposed method in larger and more diverse patient populations.
Citation: Ahmed Hamza Osman, Ashraf Osman Ibrahim, Abeer Alsadoon, Ahmad A Alzahrani, Omar Mohammed Barukub, Anas W. Abulfaraj, Nesreen M. Alharbi. Breaking new ground in cardiovascular heart disease Diagnosis K-RFC: An integrated learning approach with K-means clustering and Random Forest classifier[J]. AIMS Mathematics, 2024, 9(4): 8262-8291. doi: 10.3934/math.2024402
The ability to accurately anticipate heart failure risks in a timely manner is essential because heart failure has been identified as one of the leading causes of death. In this paper, we propose a novel method for identifying cardiovascular heart disease by utilizing a K-means clustering and Random Forest classifier combination. Based on their clinical and demographic traits, patients were classified into either healthy or diseased groups using the Random Forest classifier after being clustered using the K-means method. The performance of the proposed hybrid approach was evaluated using a dataset of patient records and compared with traditional diagnostic methods, namely support vector machine (SVM), logistic regression, and Naive Bayes classifiers. The outcomes indicated that the proposed hybrid method attained a high accuracy in diagnosing heart disease, with an overall accuracy of 96.8%. Additionally, the method showed a good performance in classifying patients at high risk of heart disease: the sensitivity reached 96.3% and the specificity reached 97.2%. In conclusion, the proposed method of combining K-means clustering and a Random Forest classifier is a promising approach for the accurate and efficient identification of heart disease. Further studies are needed to validate the proposed method in larger and more diverse patient populations.

| [1] |
C. W. Tsao, A. W. Aday, Z. I. Almarzooq, C. A. M. Anderson, P. Arora, C. L. Avery, et al., Heart disease and stroke statistics 2023 update: A report from the American Heart Association, Circulation, 147 (2023), 93–621. https://doi.org/10.1161/cir.0000000000001167 doi: 10.1161/cir.0000000000001167

|
| [2] |
K. Chadaga, S. Prabhu, V. Bhat, N. Sampathila, S. Umakanth, R. Chadaga, A decision support system for diagnosis of COVID-19 from Non-COVID-19 influenza-like illness using explainable artificial intelligence, Bioengineering, 10 (2023), 439. https://doi.org/10.3390/bioengineering10040439 doi: 10.3390/bioengineering10040439
|
| [3] |
Y. Orlova, A. Gorobtsov, O. Sychev, V. Rozaliev, A. Zubkov, A. Donsckaia, Method for determining the dominant type of human breathing using motion capture and machine learning, Algorithms, 16 (2023), 249. https://doi.org/10.3390/a16050249 doi: 10.3390/a16050249
|
| [4] |
A. H. Osman, H. M. Aljahdali, S. M. Altarrazi, A. Ahmed, SOM-LWL method for identification of COVID-19 on chest X-rays, PloS one, 16 (2021): e0247176. https://doi.org/10.1371/journal.pone.0247176 doi: 10.1371/journal.pone.0247176
|
| [5] |
A. H. Osman, Coronavirus detection using two Step-AS clustering and ensemble neural network model, Comput. Mater. Con., 71 (2022). https://doi.org/10.32604/cmc.2022.024145 doi: 10.32604/cmc.2022.024145
|
| [6] |
A. H. Osman, H. M. A. Aljahdali, An effective of ensemble boosting learning method for breast cancer virtual screening using neural network model, IEEE Access, 8 (2020), 39165–39174. https://doi.org/10.1109/access.2020.2976149 doi: 10.1109/access.2020.2976149
|
| [7] |
A. Alsadoon, G. Al-Naymat, A. H. Osman, B. Alsinglawi, M. Maabreh, M. R. Islam, DFCV: A framework for evaluation deep learning in early detection and classification of lung cancer, Multimed. Tools Appl., 2023, 1–44. https://doi.org/10.1007/s11042-023-15238-8 doi: 10.1007/s11042-023-15238-8
|
| [8] |
A. H. Osman, H. M. Aljahdali, Diabetes disease diagnosis method based on feature extraction using K-SVM, Int. J. Adv. Comput. Sci. Appl., 8 (2017). https://doi.org/10.14569/ijacsa.2017.080130 doi: 10.14569/ijacsa.2017.080130
|
| [9] |
K. Chadaga, S. Prabhu, N. Sampathila, S. Nireshwalya, S. S. Katta, S. S. Katta, et al., Application of artificial intelligence techniques for monkeypox: A systematic review, Diagnostics, 13 (2023), 824. https://doi.org/10.3390/diagnostics13050824 doi: 10.3390/diagnostics13050824
|
| [10] |
C. Helma, E. Gottmann, S. Kramer, Knowledge discovery and data mining in toxicology, Stat. Methods Med. Res., 9 (2000), 329–358. https://doi.org/10.1201/9781420073980-5 doi: 10.1201/9781420073980-5
|
| [11] |
D. A. McPartlin, R. J. O'Kennedy, Point-of-care diagnostics, a major opportunity for change in traditional diagnostic approaches: Potential and limitations, Expert Rev. Mol. Diag., 14 (2014), 979–998. https://doi.org/10.1586/14737159.2014.960516 doi: 10.1586/14737159.2014.960516
|
| [12] |
S. F. Weng, J. Reps, J. Kai, J. M. Garibaldi, N. Qureshi, Can machine-learning improve cardiovascular risk prediction using routine clinical data, PloS one, 12 (2017), e0174944. https://doi.org/10.1371/journal.pone.0174944 doi: 10.1371/journal.pone.0174944
|
| [13] | W. Zhao, C. Wang, Y. Nakahira, Medical application on internet of things, 2011, IET, 660–665. https://doi.org/10.4018/978-1-5225-1820-4.ch010 |
| [14] |
F. Ali, S. El-Sappagh, S. R. Islam, D. Kwak, D. Kwak, M. Imran, et al., A smart healthcare monitoring system for heart disease prediction based on ensemble deep learning and feature fusion, Inform. Fusion., 63 (2020), 208–222. https://doi.org/10.1016/j.inffus.2020.06.008 doi: 10.1016/j.inffus.2020.06.008
|
| [15] |
R. Bharti, A. Khamparia, M. Shabaz, G. Dhiman, S. Pande, P. Singh, Prediction of heart disease using a combination of machine learning and deep learning, Comput. Intell. Neurosc., 2021 (2021). https://doi.org/10.29121/web/v18i4/106 doi: 10.29121/web/v18i4/106
|
| [16] |
L. Nass, S. Swift, A. Al Dallal, Indepth analysis of medical dataset mining: A comparitive analysis on a diabetes dataset before and after preprocessing, KnE Social Sci., 2019, 45–63. https://doi.org/10.18502/kss.v3i25.5190 doi: 10.18502/kss.v3i25.5190
|
| [17] |
A. T. Azar, S. M. El-Metwally, Decision tree classifiers for automated medical diagnosis, Neural Comput. Appl., 23 (2013), 2387–2403. https://doi.org/10.1007/s00521-012-1196-7 doi: 10.1007/s00521-012-1196-7
|
| [18] |
R. Spencer, F. Thabtah, N. Abdelhamid, M. Thompson, Exploring feature selection and classification methods for predicting heart disease, Digital Health, 6 (2020), 2055207620914777. https://doi.org/10.1177/2055207620914777 doi: 10.1177/2055207620914777
|
| [19] |
T. A. Gaziano, A. Bitton, S. Anand, S. Abrahams-Gessel, A. Murphy, Growing epidemic of coronary heart disease in low-and middle-income countries, Current problems in cardiology, 35 (2010), 72–115. https://doi.org/10.1016/j.cpcardiol.2009.10.002 doi: 10.1016/j.cpcardiol.2009.10.002
|
| [20] |
K. Subhadra, B. Vikas, Neural network based intelligent system for predicting heart disease, Int. J. Innovative Technol. Expl. Eng., 8 (2019), 484–487. https://doi.org/10.1109/isdea.2012.417 doi: 10.1109/isdea.2012.417
|
| [21] |
S. S. Virani, A. Alonso, E. J. Benjamin, Heart disease and stroke statistics 2020 update: A report from the American Heart Association, Circulation, 141 (2020), 139–596. https://doi.org/10.1161/cir.0000000000000746 doi: 10.1161/cir.0000000000000746
|
| [22] |
S. D. Fihn, J. M. Gardin, J. Abrams, K. Berra, J. C. Blankenship, A. P. Dallas, et al., 2012 ACCF/AHA/ACP/AATS/PCNA/SCAI/STS guideline for the diagnosis and management of patients with stable ischemic heart disease: A report of the American College of Cardiology Foundation/American Heart Association task force on practice guidelines, and the American College of Physicians, American Association for Thoracic Surgery, Preventive Cardiovascular Nurses Association, Society for Cardiovascular Angiography and Interventions, and Society of Thoracic Surgeons, Circulation, 126 (2012), e354–e471. https://doi.org/10.1161/cir.0000000000000452 doi: 10.1161/cir.0000000000000452
|
| [23] |
S. N. Yu, M. Y. Lee, Bispectral analysis and genetic algorithm for congestive heart failure recognition based on heart rate variability, Comput. Biol. Med., 42 (2012), 816–825. https://doi.org/10.1016/j.compbiomed.2012.06.005 doi: 10.1016/j.compbiomed.2012.06.005
|
| [24] |
M. Fatima, M. Pasha, Survey of machine learning algorithms for disease diagnostic, J. Intell. Learn. Syst. Appl., 9 (2017), 1–16. https://doi.org/10.4236/jilsa.2017.91001 doi: 10.4236/jilsa.2017.91001
|
| [25] |
J. Wassan, H. Wang, H. Zheng, Machine learning in bioinformatics, Encyclopedia Bioinformatics Comput. Biol., 1 (2018), 300–308. https://doi.org/10.1016/b978-0-12-809633-8.20331-2 doi: 10.1016/b978-0-12-809633-8.20331-2
|
| [26] |
M. S. Amin, Y. K. Chiam, K. D. Varathan, Identification of significant features and data mining techniques in predicting heart disease, Telemat. Inform., 36 (2019), 82–93. https://doi.org/10.1016/j.tele.2018.11.007 doi: 10.1016/j.tele.2018.11.007
|
| [27] | S. Pouriyeh, S. Vahid, G. Sannino, G. De Pietro, H. Arabnia, J. Gutierrez, A comprehensive investigation and comparison of machine learning techniques in the domain of heart disease, 2017. IEEE, 204–207. https://doi.org/10.1109/iscc.2017.8024530 |
| [28] |
B. Padmaja, C. Srinidhi, K. Sindhu, K. Vanaja, N. M. Deepika, E. K. R. Patro, Early and accurate prediction of heart disease using machine learning model, Turkish J. Comput. Math., Educ. (TURCOMAT), 12 (2021), 4516–4528. https://doi.org/10.17762/turcomat.v12i6.8438 doi: 10.17762/turcomat.v12i6.8438
|
| [29] |
K. H. Boon, M. Khalil-Hani, M. Malarvili, Paroxysmal atrial fibrillation prediction based on HRV analysis and non-dominated sorting genetic algorithm, Comput. Meth. Prog. Bio., 153 (2018), 171–184. https://doi.org/10.1016/j.cmpb.2017.10.012 doi: 10.1016/j.cmpb.2017.10.012
|
| [30] |
E. Ebrahimzadeh, M. Kalantari, M. Joulani, R. S. Shahraki, F. Fayaz, F. Fayaz, Prediction of paroxysmal Atrial Fibrillation: A machine learning based approach using combined feature vector and mixture of expert classification on HRV signal, Comput. Meth. Prog. Bio., 165 (2018), 53–67. https://doi.org/10.1016/j.cmpb.2018.07.014 doi: 10.1016/j.cmpb.2018.07.014
|
| [31] |
A. U. Haq, J. P. Li, M. H. Memon, S. Nazir, R. Sun, A hybrid intelligent system framework for the prediction of heart disease using machine learning algorithms, Mob. Inf. Syst., 2018 (2018), 1–21. https://doi.org/10.1155/2018/3860146 doi: 10.1155/2018/3860146
|
| [32] |
A. Parsi, M. Glavin, E. Jones, D. Byrne, Prediction of paroxysmal atrial fibrillation using new heart rate variability features, Comput. Biol. Med., 133 (2021), 104367. https://doi.org/10.1016/j.compbiomed.2021.104367 doi: 10.1016/j.compbiomed.2021.104367
|
| [33] |
J. Minou, J. Mantas, F. Malamateniou, D. Kaitelidou, Classification techniques for cardio-vascular diseases using supervised machine learning, Med. Archives, 74 (2020), 39. https://doi.org/10.5455/medarh.2020.74.39-41 doi: 10.5455/medarh.2020.74.39-41
|
| [34] |
M. M. Aborokbah, S. Al-Mutairi, A. K. Sangaiah, O. W. Samuel, Adaptive context aware decision computing paradigm for intensive health care delivery in smart cities—A case analysis, Sustain. Cities Soc., 41 (2018), 919–924. https://doi.org/10.1161/cir.0000000000001167 doi: 10.1161/cir.0000000000001167
|
| [35] |
A. Alabrah, An improved CCF detector to handle the problem of class imbalance with outlier normalization using IQR method, Sensors, 23 (2023), 4406. https://doi.org/10.3390/bioengineering10040439 doi: 10.3390/bioengineering10040439
|
| [36] | R. Xing, J. Meng, Machine learning for ischaemic heart disease diagnostic analysis, 2022. IEEE. 207–211. https://doi.org/10.1109/ecbios54627.2022.9944997 |
| [37] |
L. Li, W. Xie, Z. Liu, A novel quadrature particle filtering based on fuzzy c-means clustering, Knowl.-Based Syst., 106 (2016), 105–115. https://doi.org/10.1016/j.knosys.2016.05.034 doi: 10.1016/j.knosys.2016.05.034
|
| [38] | F. Previtali, G. Gemignani, L. Iocchi, D. Nardi, Disambiguating localization symmetry through a multi-clustered particle filtering, 2015. IEEE. 283–288. https://doi.org/10.1109/mfi.2015.7295822 |
| [39] | C. Kerdvibulvech, Human hand motion recognition using an extended particle filter, 2014. Springer, 71–80. https://doi.org/10.1007/978-3-319-08849-5_8 |
| [40] | R. Raziperchikolaei, M. Jamzad, Visual tracking using D2-clustering and particle filter, 2012. IEEE, 000230–000235. https://doi.org/10.1109/isspit.2012.6621292 |
| [41] | S. Palaniappan, R. Awang, Intelligent heart disease prediction system using data mining techniques, 2008, IEEE, 108–115. https://doi.org/10.1109/aiccsa.2008.4493524 |
| [42] |
V. Shorewala, Early detection of coronary heart disease using ensemble techniques, Inf. Med. Unlocked, 26 (2021), 100655. https://doi.org/10.1016/j.imu.2021.100655 doi: 10.1016/j.imu.2021.100655
|
| [43] |
R. R. Sanni, H. Guruprasad, Analysis of performance metrics of heart failured patients using Python and machine learning algorithms, Global Transitions Proceedings, 2 (2021), 233–237. https://doi.org/10.1016/j.gltp.2021.08.028 doi: 10.1016/j.gltp.2021.08.028
|
| [44] |
I. K. A. Enriko, M. Suryanegara, D. Gunawan, Heart disease prediction system using k-Nearest neighbor algorithm with simplified patient's health parameters, J. Telec. Electron.Comput. Eng. (JTEC), 8 (2016), 59–65. https://doi.org/10.21203/rs.3.rs-3297518/v1 doi: 10.21203/rs.3.rs-3297518/v1
|
| [45] | M. A. Jabbar, B. L. Deekshatulu, P. Chandra, Heart disease prediction using lazy associative classification, 2013, IEEE, 40–46. https://doi.org/10.1109/imac4s.2013.6526381 |
| [46] |
J. Soni, U. Ansari, D. Sharma, S. Soni, Intelligent and effective heart disease prediction system using weighted associative classifiers, Int. J. Comput. Sci. Eng., 3 (2011), 2385–2392. https://doi.org/10.21203/rs.3.rs-1790774/v1 doi: 10.21203/rs.3.rs-1790774/v1
|
| [47] | I. Sedielmaci, F. B. Reguig, Detection of some heart diseases using fractal dimension and chaos theory, 2013, IEEE, 89–94. https://doi.org/10.1016/s2213-2600(21)00181-8 |
| [48] | J. S. Sonawane, D. Patil, Prediction of heart disease using learning vector quantization algorithm, 2014, IEEE, 1–5. https://doi.org/10.1109/csibig.2014.7056973 |
| [49] |
K. H. Miao, J. H. Miao, Coronary heart disease diagnosis using deep neural networks, Int. J. Adv. Comput. Sci. Appl., 9 (2018). https://doi.org/10.14569/ijacsa.2018.091001 doi: 10.14569/ijacsa.2018.091001
|
| [50] |
S. H. Mujawar, P. Devale, Prediction of heart disease using modified K-means and by using naive Bayes, Int. J. Innovat. Res. Comput. Comm. Eng., 3 (2015), 10265–10273. https://doi.org/10.4066/biomedicalresearch.29-18-620 doi: 10.4066/biomedicalresearch.29-18-620
|
Figures(7) / Tables(11)

Ahmed Hamza Osman, Ashraf Osman Ibrahim, Abeer Alsadoon, Ahmad A Alzahrani, Omar Mohammed Barukub, Anas W. Abulfaraj, Nesreen M. Alharbi. Breaking new ground in cardiovascular heart disease Diagnosis K-RFC: An integrated learning approach with K-means clustering and Random Forest classifier[J]. AIMS Mathematics, 2024, 9(4): 8262-8291. doi: 10.3934/math.2024402







 DownLoad:
DownLoad: