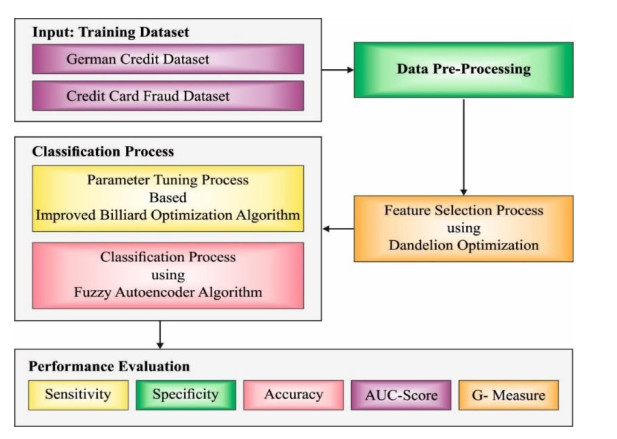
Digital transactions relying on credit cards are gradually improving in recent days due to their convenience. Due to the tremendous growth of e-services (e.g., mobile payments, e-commerce, and e-finance) and the promotion of credit cards, fraudulent transaction counts are rapidly increasing. Machine learning (ML) is crucial in investigating customer data for detecting and preventing fraud. Conversely, the advent of irrelevant and redundant features in most real-time credit card details reduces the execution of ML techniques. The feature selection (FS) approach's purpose is to detect the most prominent attributes required for developing an effective ML approach, making sure that the classification and computational complexity are improved and decreased, respectively. Therefore, this study presents an evolutionary computing with fuzzy autoencoder based data analytics for credit card fraud detection (ECFAE-CCFD) technique. The purpose of the ECFAE-CCFD technique is to recognize the presence of credit card fraud (CCF) in real time. To achieve this, the ECFAE-CCFD technique performs data normalization in the earlier stage. For selecting features, the ECFAE-CCFD technique applies the dandelion optimization-based feature selection (DO-FS) technique. Moreover, the fuzzy autoencoder (FAE) approach can be exploited for the recognition and classification of CCF. FAE is a category of artificial neural network (ANN) designed for unsupervised learning that leverages fuzzy logic (FL) principles to enhance the representation and reconstruction of input data. An improved billiard optimization algorithm (IBOA) could be implemented for the optimum selection of the parameters based on the FAE algorithm to improve the classification performance. The simulation outcomes of the ECFAE-CCFD algorithm are examined on the benchmark open-access database. The values display the excellent performance of the ECFAE-CCFD method with respect to various measures.
Citation: Ebtesam Al-Mansor, Mohammed Al-Jabbar, Arwa Darwish Alzughaibi, Salem Alkhalaf. Dandelion optimization based feature selection with machine learning for digital transaction fraud detection[J]. AIMS Mathematics, 2024, 9(2): 4241-4258. doi: 10.3934/math.2024209
Digital transactions relying on credit cards are gradually improving in recent days due to their convenience. Due to the tremendous growth of e-services (e.g., mobile payments, e-commerce, and e-finance) and the promotion of credit cards, fraudulent transaction counts are rapidly increasing. Machine learning (ML) is crucial in investigating customer data for detecting and preventing fraud. Conversely, the advent of irrelevant and redundant features in most real-time credit card details reduces the execution of ML techniques. The feature selection (FS) approach's purpose is to detect the most prominent attributes required for developing an effective ML approach, making sure that the classification and computational complexity are improved and decreased, respectively. Therefore, this study presents an evolutionary computing with fuzzy autoencoder based data analytics for credit card fraud detection (ECFAE-CCFD) technique. The purpose of the ECFAE-CCFD technique is to recognize the presence of credit card fraud (CCF) in real time. To achieve this, the ECFAE-CCFD technique performs data normalization in the earlier stage. For selecting features, the ECFAE-CCFD technique applies the dandelion optimization-based feature selection (DO-FS) technique. Moreover, the fuzzy autoencoder (FAE) approach can be exploited for the recognition and classification of CCF. FAE is a category of artificial neural network (ANN) designed for unsupervised learning that leverages fuzzy logic (FL) principles to enhance the representation and reconstruction of input data. An improved billiard optimization algorithm (IBOA) could be implemented for the optimum selection of the parameters based on the FAE algorithm to improve the classification performance. The simulation outcomes of the ECFAE-CCFD algorithm are examined on the benchmark open-access database. The values display the excellent performance of the ECFAE-CCFD method with respect to various measures.

| [1] | P. Roy, P. Rao, J. Gajre, K. Katake, A. Jagtap, Y. Gajmal, Comprehensive analysis for fraud detection of credit cards through machine learning. In: 2021 International conference on emerging smart computing and informatics (ESCI), 2021. https://doi.org/10.1109/ESCI50559.2021.9397029 |
| [2] |
J. Liu, X. Gu, C. Shang, Quantitative detection of financial fraud based on deep learning with combination of E-commerce big data, Complexity, 2020 (2020), 6685888. https://doi.org/10.1155/2020/6685888 doi: 10.1155/2020/6685888

|
| [3] |
E. Kim, J. Lee, H. Shin, H. Yang, S. Cho, S. K. Nam, et al., Champion-challenger analysis for credit card fraud detection: Hybrid ensemble and deep learning, Expert Syst. Appl., 128 (2019), 214–224. https://doi.org/10.1016/j.eswa.2019.03.042 doi: 10.1016/j.eswa.2019.03.042
|
| [4] |
A. RB, S. K. KR, Credit card fraud detection using artificial neural network, Global Transit. Proc., 2 (2021), 35–41. https://doi.org/10.1016/j.gltp.2021.01.006 doi: 10.1016/j.gltp.2021.01.006
|
| [5] |
F. K. Alarfaj, I. Malik, H. U. Khan, N. Almusallam, M. Ramzan, M. Ahmed, Credit card fraud detection using state-of-the-art machine learning and deep learning algorithms, IEEE Access, 10 (2022), 39700–39715. https://doi.org/10.1109/ACCESS.2022.3166891 doi: 10.1109/ACCESS.2022.3166891
|
| [6] |
O. Voican, Credit card fraud detection using deep learning techniques, Informatica Economica, 25 (2021), 70–85. https://doi.org/10.24818/issn14531305/25.1.2021.06 doi: 10.24818/issn14531305/25.1.2021.06
|
| [7] |
X. Zhang, Y. Han, W. Xu, Q. Wang, HOBA: A novel feature engineering methodology for credit card fraud detection with a deep learning architecture, Inform. Sci., 557 (2021), 302–316. https://doi.org/10.1016/j.ins.2019.05.023 doi: 10.1016/j.ins.2019.05.023
|
| [8] |
J. I. Z. Chen, K. L. Lai, Deep convolution neural network model for credit-card fraud detection and alert, J. Artif. Intell. Capsule Netw., 3 (2021), 101–112. https://doi.org/10.36548/jaicn.2021.2.003 doi: 10.36548/jaicn.2021.2.003
|
| [9] | G. Pratuzaitė, N. Maknickienė, Investigation of credit cards fraud detection by using deep learning and classification algorithms. In: 11th International scientific conference "business and management 2020", 2020,389–396. https://doi.org/10.3846/bm.2020.558 |
| [10] |
J. Forough, S. Momtazi, Ensemble of deep sequential models for credit card fraud detection, Appl. Soft Comput., 99 (2021), 106883. https://doi.org/10.1016/j.asoc.2020.106883 doi: 10.1016/j.asoc.2020.106883
|
| [11] |
A. R. Khalid, N. Owoh, O. Uthmani, M. Ashawa, J. Osamor, J. Adejoh, Enhancing credit card fraud detection: An ensemble machine learning approach, Big Data Cogn Comput, 8 (2024), 6. https://doi.org/10.3390/bdcc8010006 doi: 10.3390/bdcc8010006
|
| [12] | P. Raghavan, N. El Gayar, Fraud detection using machine learning and deep learning. In: 2019 international conference on computational intelligence and knowledge economy (ICCIKE), 2019,334–339. https://doi.org/10.1109/ICCIKE47802.2019.9004231 |
| [13] |
T. K. Dang, T. C. Tran, L. M. Tuan, M. V. Tiep, Machine learning based on resampling approaches and deep reinforcement learning for credit card fraud detection systems, Appl. Sci., 11 (2021), 10004. https://doi.org/10.3390/app112110004 doi: 10.3390/app112110004
|
| [14] |
A. Alharbi, M. Alshammari, O. D. Okon, A. Alabrah, H. T. Rauf, H. Alyami, et al., A novel text2IMG mechanism of credit card fraud detection: A deep learning approach, Electronics, 11 (2022), 756. https://doi.org/10.3390/electronics11050756 doi: 10.3390/electronics11050756
|
| [15] |
S. Sanober, I. Alam, S. Pande, F. Arslan, K. P. Rane, B. K. Singh, et al., An enhanced secure deep learning algorithm for fraud detection in wireless communication, Wirel. Commun. Mob. Com., 2021 (2021), 6079582. https://doi.org/10.1155/2021/6079582 doi: 10.1155/2021/6079582
|
| [16] |
N. Nguyen, T. Duong, T. Chau, V. H. Nguyen, T. Trinh, D. Tran, et al., A proposed model for card fraud detection based on CatBoost and deep neural network, IEEE Access, 10 (2022), 96852–96861. https://doi.org/10.1109/ACCESS.2022.3205416 doi: 10.1109/ACCESS.2022.3205416
|
| [17] |
D. Almhaithawi, A. Jafar, M. Aljnidi, Example-dependent cost-sensitive credit cards fraud detection using SMOTE and Bayes minimum risk, SN Appl. Sci., 2 (2020), 1574. https://doi.org/10.1007/s42452-020-03375-w doi: 10.1007/s42452-020-03375-w
|
| [18] |
A. A. Taha, S. J. Malebary, An intelligent approach to credit card fraud detection using an optimized light gradient boosting machine, IEEE Access, 8 (2020), 25579–25587. https://doi.org/10.1109/ACCESS.2020.2971354 doi: 10.1109/ACCESS.2020.2971354
|
| [19] |
V. R. Ganji, A. Chaparala, R. Sajja, Shuffled shepherd political optimization‐based deep learning method for credit card fraud detection, Concurr. Comp. Pract. E., 35 (2023), e7666. https://doi.org/10.1002/cpe.7666 doi: 10.1002/cpe.7666
|
| [20] | A. Dhyani, A. Bansal, A. Jain, S. Seniaray, Credit card fraud detection using machine learning and incremental learning, In: Proceedings of international conference on recent trends in computing, Singapore: Springer, 2023,337–349. https://doi.org/10.1007/978-981-19-8825-7_29 |
| [21] |
V. S. S. Karthik, A. Mishra, U. S. Reddy, Credit card fraud detection by modelling behaviour pattern using hybrid ensemble model, Arab. J. Sci. Eng., 47 (2022), 1987–1997. https://doi.org/10.1007/s13369-021-06147-9 doi: 10.1007/s13369-021-06147-9
|
| [22] |
G. Hu, Y. Zheng, L. Abualigah, A. G. Hussien, DETDO: An adaptive hybrid dandelion optimizer for engineering optimization, Adv. Eng. Inform., 57 (2023), 102004. https://doi.org/10.1016/j.aei.2023.102004 doi: 10.1016/j.aei.2023.102004
|
| [23] |
W. Yang, H. Wang, Y. Zhang, Z. Liu, T. Li, Self-supervised discriminative representation learning by fuzzy autoencoder, ACM T. Intel. Syst. Technol., 14 (2022), 1–18. https://doi.org/10.1145/3555777 doi: 10.1145/3555777
|
| [24] |
H. Ghafourian, S. S. Ershadi, D. K. Voronkova, S. Omidvari, L. Badrizadeh, M. L. Nehdi, Minimizing single-family homes' carbon dioxide emissions and life cycle costs: An improved billiard-based optimization algorithm approach, Buildings, 13 (2023), 1815. https://doi.org/10.3390/buildings13071815 doi: 10.3390/buildings13071815
|
| [25] |
I. D. Mienye, Y. Sun, A machine learning method with hybrid feature selection for improved credit card fraud detection, Appl. Sci., 13 (2023), 7254. https://doi.org/10.3390/app13127254 doi: 10.3390/app13127254
|









Figures(10) / Tables(4)

Ebtesam Al-Mansor, Mohammed Al-Jabbar, Arwa Darwish Alzughaibi, Salem Alkhalaf. Dandelion optimization based feature selection with machine learning for digital transaction fraud detection[J]. AIMS Mathematics, 2024, 9(2): 4241-4258. doi: 10.3934/math.2024209







 DownLoad:
DownLoad: