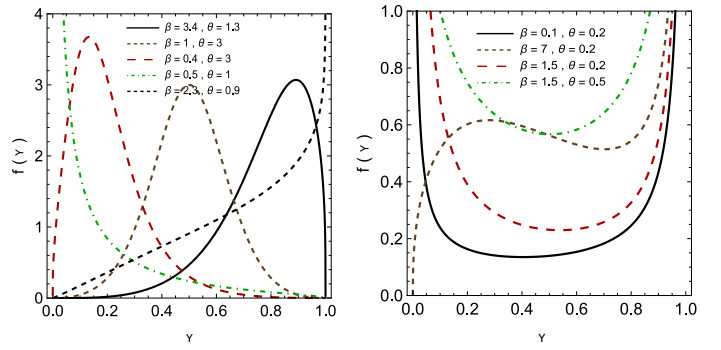
Continuous developments in unit interval distributions have shown effectiveness in modeling proportional data. However, challenges persist in diverse dispersion characteristics in real-world scenarios. This study introduces the unit logistic-exponential (ULE) distribution, a flexible probability model built upon the logistic-exponential distribution and designed for data confined to the unit interval. The statistical properties of the ULE distribution were studied, and parameter estimation through maximum likelihood estimation, Bayesian methods, maximum product spacings, and least squares estimates were conducted. A thorough simulation analysis using numerical techniques such as the quasi-Newton method and Markov chain Monte Carlo highlights the performance of the estimation methods, emphasizing their accuracy and reliability. The study reveals that the ULE distribution, paired with tools like randomized quantile and Cox-Snell residuals, provides robust assessments of goodness of fit, making it well-suited for real-world applications. Key findings demonstrate that the unit logistic-exponential distribution captures diverse data patterns effectively and improves reliability assessment in practical contexts. When applied to two real-world datasets—one from the medical field and the other from the economic sector—the ULE distribution consistently outperforms existing unit interval models, showcasing lower error rates and enhanced flexibility in tail behavior. These results underline the distribution's potential impact in areas requiring precise proportions modeling, ultimately supporting better decision-making and predictive analyses.
Citation: Hanan Haj Ahmad, Kariema A. Elnagar. A novel quantile regression for fractiles based on unit logistic exponential distribution[J]. AIMS Mathematics, 2024, 9(12): 34504-34536. doi: 10.3934/math.20241644
Continuous developments in unit interval distributions have shown effectiveness in modeling proportional data. However, challenges persist in diverse dispersion characteristics in real-world scenarios. This study introduces the unit logistic-exponential (ULE) distribution, a flexible probability model built upon the logistic-exponential distribution and designed for data confined to the unit interval. The statistical properties of the ULE distribution were studied, and parameter estimation through maximum likelihood estimation, Bayesian methods, maximum product spacings, and least squares estimates were conducted. A thorough simulation analysis using numerical techniques such as the quasi-Newton method and Markov chain Monte Carlo highlights the performance of the estimation methods, emphasizing their accuracy and reliability. The study reveals that the ULE distribution, paired with tools like randomized quantile and Cox-Snell residuals, provides robust assessments of goodness of fit, making it well-suited for real-world applications. Key findings demonstrate that the unit logistic-exponential distribution captures diverse data patterns effectively and improves reliability assessment in practical contexts. When applied to two real-world datasets—one from the medical field and the other from the economic sector—the ULE distribution consistently outperforms existing unit interval models, showcasing lower error rates and enhanced flexibility in tail behavior. These results underline the distribution's potential impact in areas requiring precise proportions modeling, ultimately supporting better decision-making and predictive analyses.

| [1] | M. Ç. Korkmaz, The unit generalized half normal distribution: A new bounded distribution with inference and application, U.P.B. Sci. Bull., 82 (2020), 133–140. |
| [2] |
M. E. Ghitany, J. Mazucheli, A. F. B. Menezes, F. Alqallaf, The unit-inverse Gaussian distribution: A new alternative to two-parameter distributions on the unit interval, Comm. Statist. Theory Methods, 48 (2019), 3423–3438. https://doi.org/10.1080/03610926.2018.1476717 doi: 10.1080/03610926.2018.1476717

|
| [3] |
P. C. Consul, G. C. Jain, On the log-gamma distribution and its properties, Statistische Hefte, 12 (1971), 100–106. https://doi.org/10.1007/BF02922944 doi: 10.1007/BF02922944
|
| [4] | J. Mazucheli, A. F. B. Menezes, M. E. Ghitany, The unit-Weibull distribution and associated inference, J. Appl. Probab. Stat., 13 (2018), 1–22. |
| [5] |
J. Mazucheli, A. F. Menezes, S. Dey, Unit-Gompertz distribution with applications, Statistica, 79 (2019), 25–43. https://doi.org/10.6092/issn.1973-2201/8497 doi: 10.6092/issn.1973-2201/8497
|
| [6] |
M. M. E. Abd El-Monsef, M. M. El-Awady, M. M. Seyam, A new quantile regression model for modeling child mortality, Int. J. Biomath., 15 (2022), 2250031. https://doi.org/10.1142/S1793524522500310 doi: 10.1142/S1793524522500310
|
| [7] |
M. Ç. Korkmaz, C. Chesneau, On the unit Burr-XII distribution with the quantile regression modeling and applications, Comp. Appl. Math., 40 (2021), 29. https://doi.org/10.1007/s40314-021-01418-5 doi: 10.1007/s40314-021-01418-5
|
| [8] |
H. S. Bakouch, A. S. Nik, A. Asgharzadeh, H. S. Salinas, A flexible probability model for proportion data: Unit-half-normal distribution, Comm. Statist. Case Stud. Data Anal. Appl., 7 (2021), 271–288. https://doi.org/10.1080/23737484.2021.1882355 doi: 10.1080/23737484.2021.1882355
|
| [9] |
H. Haj Ahmad, E. M. Almetwally, M. Elgarhy, D. A. Ramadan, On unit exponential Pareto distribution for modeling the recovery rate of COVID-19, Processes, 11 (2023), 232. https://doi.org/10.3390/pr11010232 doi: 10.3390/pr11010232
|
| [10] |
A. S. Hassan, A. Fayomi, A. Algarni, E. M. Almetwally, Bayesian and non-Bayesian inference for unit-exponentiated half-logistic distribution with data analysis, Appl. Sci., 12 (2022), 11253. https://doi.org/10.3390/app122111253 doi: 10.3390/app122111253
|
| [11] | A. S. Hassan, A. M. Khalil, H. F. Nagy, Data analysis and classical estimation methods of the bounded power Lomax distribution, Reliab. Theory Appl., 19 (2024), 770–789. |
| [12] |
A. Fayomi, A. S. Hassan, E. M. Almetwally, Inference and quantile regression for the unit-exponentiated Lomax distribution, Plos one, 18 (2023), e0288635. https://doi.org/10.1371/journal.pone.0288635 doi: 10.1371/journal.pone.0288635
|
| [13] |
A. Fayomi, A. S. Hassan, H. Baaqeel, E. M. Almetwally, Bayesian inference and data analysis of the unit-power Burr X distribution, Axioms, 12 (2023), 297. https://doi.org/10.3390/axioms12030297 doi: 10.3390/axioms12030297
|
| [14] |
A. S. Hassan, R. E. Mohamed, O. Kharazmi, H. F. Nagy, A new four-parameter extended exponential distribution with statistical properties and applications, Pak. J. Stat. Oper. Res., 18 (2022), 179–193. https://doi.org/10.18187/pjsor.v18i1.3872 doi: 10.18187/pjsor.v18i1.3872
|
| [15] |
R. D. Gupta, D. Kundu, Generalized exponential distribution: Different method of estimations, J. Stat. Comput. Simul., 69 (2001), 315–337. https://doi.org/10.1080/00949650108812098 doi: 10.1080/00949650108812098
|
| [16] |
M. C. Jones, Families of distributions arising from distributions of order statistics, Test, 13 (2004), 1–43. https://doi.org/10.1007/BF02602999 doi: 10.1007/BF02602999
|
| [17] |
M. S. Khan, R. King, I. L. Hudson, Transmuted generalized exponential distribution: A generalization of the exponential distribution with applications to survival data, Commun. Statist., 46 (2017), 4377–4398. https://doi.org/10.1080/03610918.2015.1118503 doi: 10.1080/03610918.2015.1118503
|
| [18] |
A. Z. Afify, G. M. Cordeiro, H. M. Yousof, Z. M. Nofal, A. Alzaatreh, The Kumaraswamy transmuted-G family of distributions: Properties and applications, J. Data Sci., 14 (2016), 245–270. https://doi.org/10.6339/JDS.201604_14(2).0004 doi: 10.6339/JDS.201604_14(2).0004
|
| [19] |
A. J. Lemonte, G. M. Cordeiro, G. Moreno-Arenas, A new useful three-parameter extension of the exponential distribution, Statistics, 50 (2016), 312–337. https://doi.org/10.1080/02331888.2015.1095190 doi: 10.1080/02331888.2015.1095190
|
| [20] |
A. Mahdavi, D. Kundu, A new method for generating distributions with an application to exponential distribution, Comm. Statist. Theory Methods, 46 (2017), 6543–6557. https://doi.org/10.1080/03610926.2015.1130839 doi: 10.1080/03610926.2015.1130839
|
| [21] |
M. Nassar, A. Z. Afify, M. K. Shakhatreh, Estimation methods of alpha power exponential distribution with applications to engineering and medical data, Pak. J. Stat. Oper. Res., 16 (2020), 149–166. http://dx.doi.org/10.18187/pjsor.v16i1.3129 doi: 10.18187/pjsor.v16i1.3129
|
| [22] |
A. Z. Afify, O. A. Mohamed, A new three-parameter exponential distribution with variable shapes for the hazard rate: Estimation and applications, Mathematics, 8 (2020), 135. https://doi.org/10.3390/math8010135 doi: 10.3390/math8010135
|
| [23] |
M. Nassar, D. Kumar, S. Dey, G. M. Cordeiro, A. Z. Afify, The Marshall-Olkin alpha power family of distributions with applications, J. Comput. Appl. Math., 351 (2019), 41–53. https://doi.org/10.1016/j.cam.2018.10.052 doi: 10.1016/j.cam.2018.10.052
|
| [24] | M. A. Aldahlan, A. Z. Afify, A new three-parameter exponential distribution with applications in reliability and engineering, J. Nonlinear Sci. Appl., 13 (2020), 258–269. |
| [25] | S. Abbas, A. Jahngeer, S. H. Shahbaz, A. Z. Afify, M. Q. Shahbaz, Topp-Leone moment exponential distribution: Properties and applications, J. Natl. Sci. Found. Sri Lanka, 48 (2020), 265–274. |
| [26] |
Y. Lan, L. M. Leemis, The logistic-exponential survival distribution, Naval Res. Logist., 55 (2008), 252–264. https://doi.org/10.1002/nav.20279 doi: 10.1002/nav.20279
|
| [27] | M. Shaked, J. G. Shanthikumar, Stochastic orders, New York: Springer, 2007. https://doi.org/10.1007/978-0-387-34675-5 |
| [28] | A. Zellner, Bayesian estimation and prediction using asymmetric loss functions, J. Amer. Statist. Assoc., 81 (1986), 446–451. |
| [29] |
S. Dey, S. Ali, C. Park, Weighted exponential distribution: Properties and different methods of estimation, J. Stat. Comput. Simul., 85 (2015), 3641–3661. https://doi.org/10.1080/00949655.2014.992346 doi: 10.1080/00949655.2014.992346
|
| [30] |
D. Kundu, H. Howlader, Bayesian inference and prediction of the inverse Weibull distribution for Type-Ⅱ censored data, Comput. Statist. Data Anal., 54 (2010), 1547–1558. https://doi.org/10.1016/j.csda.2010.01.003 doi: 10.1016/j.csda.2010.01.003
|
| [31] | L. Tierney, Markov chains for exploring posterior distributions, Ann. Statist., 22 (1994), 1701–1728. |
| [32] | A. Gelman, J. B. Carlin, H. S. Stern, D. B. Rubin, Bayesian data analysis, New York: Chapman and Hall/CRC, 1995. https://doi.org/10.1201/9780429258411 |
| [33] |
G. O. Roberts, J. S. Rosenthal, Optimal scaling of discrete approximations to Langevin diffusions, J. R. Stat. Soc. Ser. B Stat. Methodol., 60 (1998), 255–268. https://doi.org/10.1111/1467-9868.00123 doi: 10.1111/1467-9868.00123
|
| [34] |
R. C. H. Cheng, N. A. K. Amin, Estimating parameters in continuous univariate distributions with a shifted origin, J. R. Stat. Soc. Ser. B Stat. Methodol, 45 (1983), 394–403. https://doi.org/10.1111/j.2517-6161.1983.tb01268.x doi: 10.1111/j.2517-6161.1983.tb01268.x
|
| [35] | B. Ranneby, The maximum spacing method. An estimation method related to the maximum likelihood method, Scand. J. Statist., 11 (1984), 93–112. |
| [36] | E. J. G. Pitman, Some basic theory for statistical inference: Monographs on applied probability and statistics, New York: Chapman & Hall, 1979. https://doi.org/10.1201/9781351076777 |
| [37] |
R. C. H. Cheng, L. Traylor, Non-regular maximum likelihood problems, J. R. Stat. Soc. Ser. B Stat. Methodol., 57 (1995), 3–24. https://doi.org/10.1111/j.2517-6161.1995.tb02013.x doi: 10.1111/j.2517-6161.1995.tb02013.x
|
| [38] |
K. Ghosh, S. R. Jammalamadaka, A general estimation method using spacings, J. Statist. Plann. Inference, 93 (2001), 71–82. https://doi.org/10.1016/S0378-3758(00)00160-9 doi: 10.1016/S0378-3758(00)00160-9
|
| [39] |
S. Anatolyev, G. Kosenok, An alternative to maximum likelihood based on spacings, Econometric Theory, 21 (2005), 472–476. https://doi.org/10.1017/S0266466605050255 doi: 10.1017/S0266466605050255
|
| [40] | R. Koenker, G. Bassett, Regression quantiles, Econometrica, 46 (1978), 33–50. |
| [41] | P. K. Dunn, G. K. Smyth, Randomized quantile residuals, J. Comput. Graph. Statist., 5 (1996), 236–244. |
| [42] |
D. R. Cox, E. J. Snell, A general definition of residuals, J. R. Stat. Soc. Ser. B Stat. Methodol., 30 (1968), 248–265. https://doi.org/10.1111/j.2517-6161.1968.tb00724.x doi: 10.1111/j.2517-6161.1968.tb00724.x
|
| [43] |
A. C. Atkinson, Two graphical displays for outlying and influential observations in regression, Biometrika, 68 (1981), 13–20. https://doi.org/10.1093/biomet/68.1.13 doi: 10.1093/biomet/68.1.13
|
| [44] |
P. Zhang, Z. Qiu, C. Shi, simplexreg: An R package for regression analysis of proportional data using the simplex distribution, J. Statist. Softw., 71 (2016), 1–21. https://doi.org/10.18637/jss.v071.i11 doi: 10.18637/jss.v071.i11
|
| [45] | J. T. Schmit, K. Roth, Cost effectiveness of risk management practices, J. Risk Insurance, 57 (1990), 455–470. |








Figures(9) / Tables(13)

Hanan Haj Ahmad, Kariema A. Elnagar. A novel quantile regression for fractiles based on unit logistic exponential distribution[J]. AIMS Mathematics, 2024, 9(12): 34504-34536. doi: 10.3934/math.20241644







 DownLoad:
DownLoad: