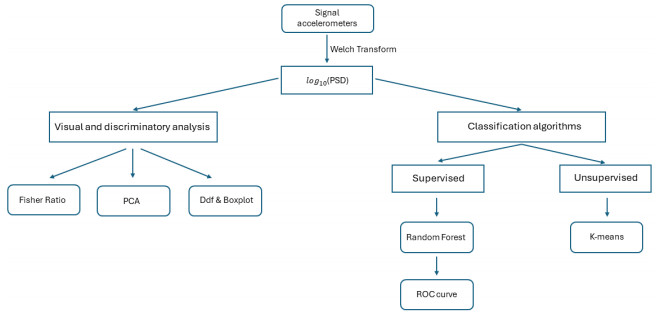
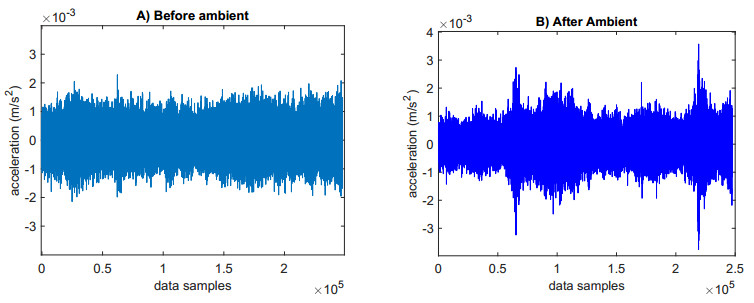
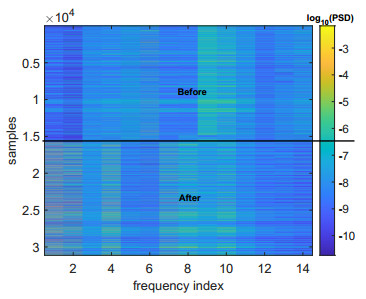
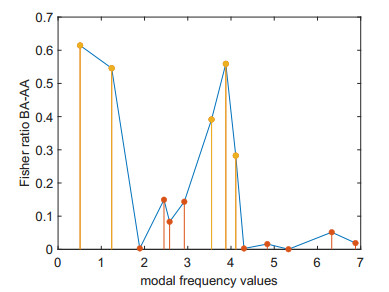
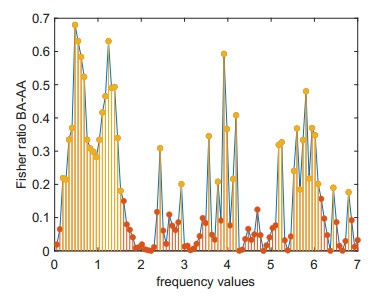
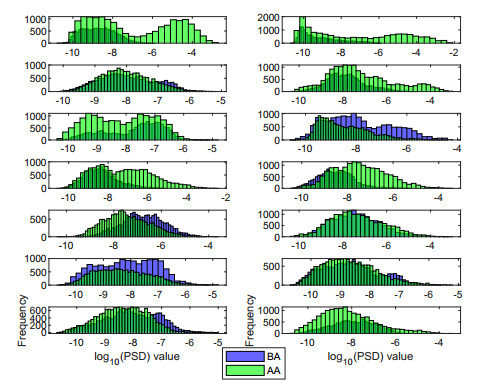
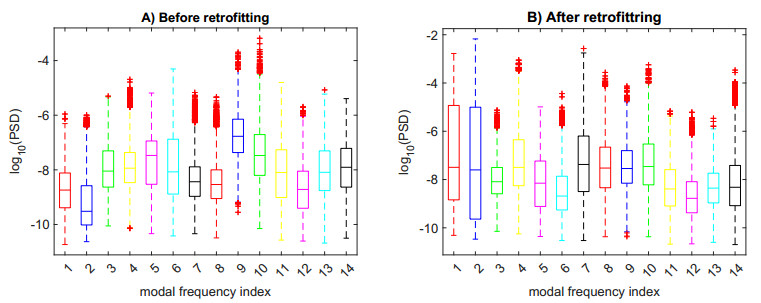
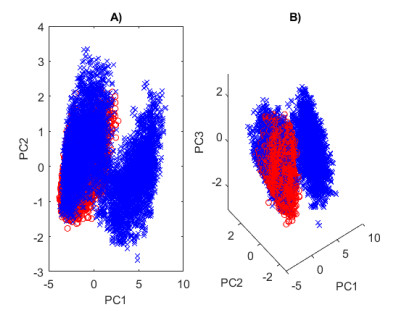
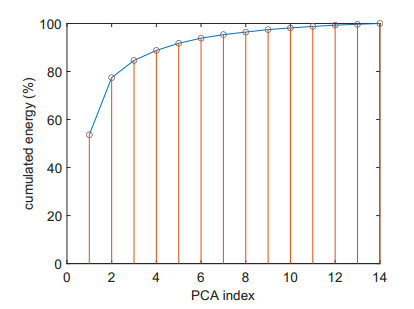
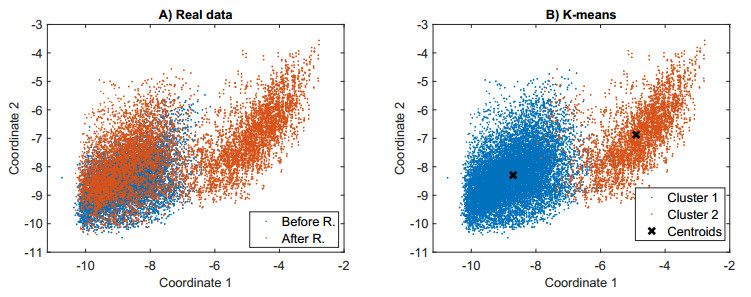
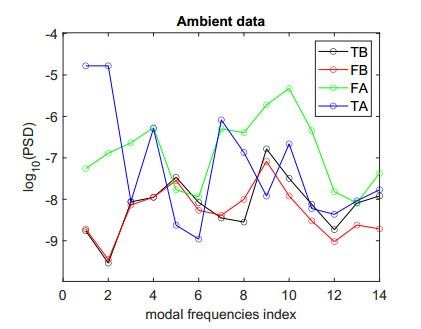
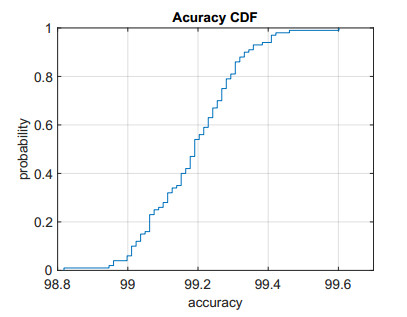
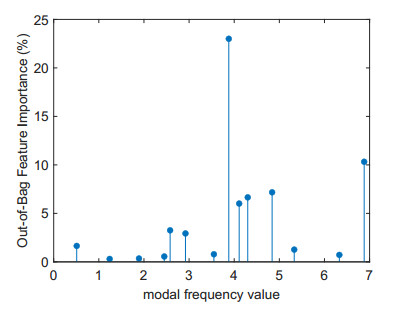
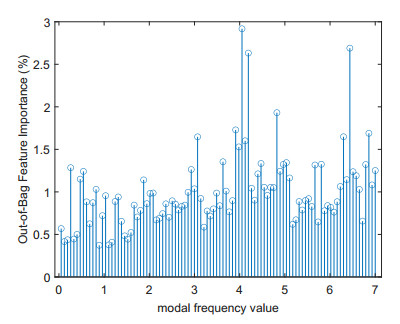
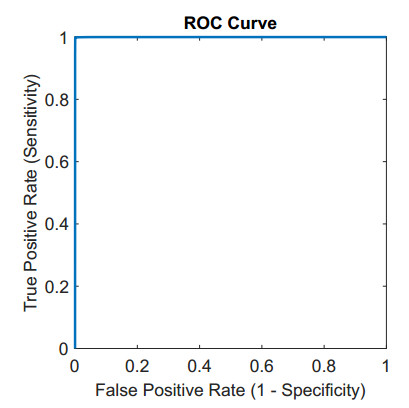
Structural health in civil engineering involved maintaining a structure's integrity and performance over time, resisting loads and environmental effects. Ensuring long-term functionality was vital to prevent accidents, economic losses, and service interruptions. Structural health monitoring (SHM) systems used sensors to detect damage indicators such as vibrations and cracks, which were crucial for predicting service life and planning maintenance. Machine learning (ML) enhanced SHM by analyzing sensor data to identify damage patterns often missed by human analysts. ML models captured complex relationships in data, leading to accurate predictions and early issue detection. This research aimed to develop a methodology for training an artificial intelligence (AI) system to predict the effects of retrofitting on civil structures, using data from the KW51 bridge (Leuven). Dimensionality reduction with the Welch transform identified the first seven modal frequencies as key predictors. Unsupervised principal component analysis (PCA) projections and a K-means algorithm achieved $ 70 \% $ accuracy in differentiating data before and after retrofitting. A random forest algorithm achieved $ 99.19 \% $ median accuracy with a nearly perfect receiver operating characteristic (ROC) curve. The final model, tested on the entire dataset, achieved $ 99.77 \% $ accuracy, demonstrating its effectiveness in predicting retrofitting effects for other civil structures.
Citation: A. Presno Vélez, M. Z. Fernández Muñiz, J. L. Fernández Martínez. Enhancing structural health monitoring with machine learning for accurate prediction of retrofitting effects[J]. AIMS Mathematics, 2024, 9(11): 30493-30514. doi: 10.3934/math.20241472
Structural health in civil engineering involved maintaining a structure's integrity and performance over time, resisting loads and environmental effects. Ensuring long-term functionality was vital to prevent accidents, economic losses, and service interruptions. Structural health monitoring (SHM) systems used sensors to detect damage indicators such as vibrations and cracks, which were crucial for predicting service life and planning maintenance. Machine learning (ML) enhanced SHM by analyzing sensor data to identify damage patterns often missed by human analysts. ML models captured complex relationships in data, leading to accurate predictions and early issue detection. This research aimed to develop a methodology for training an artificial intelligence (AI) system to predict the effects of retrofitting on civil structures, using data from the KW51 bridge (Leuven). Dimensionality reduction with the Welch transform identified the first seven modal frequencies as key predictors. Unsupervised principal component analysis (PCA) projections and a K-means algorithm achieved $ 70 \% $ accuracy in differentiating data before and after retrofitting. A random forest algorithm achieved $ 99.19 \% $ median accuracy with a nearly perfect receiver operating characteristic (ROC) curve. The final model, tested on the entire dataset, achieved $ 99.77 \% $ accuracy, demonstrating its effectiveness in predicting retrofitting effects for other civil structures.

| [1] |
R. Katam, V. D. K. Pasupuleti, P. Kalapatapu, A review on structural health monitoring: past to present, Innov. Infrastruct. Solut., 8 (2023), 248. https://doi.org/10.1007/s41062-023-01217-3 doi: 10.1007/s41062-023-01217-3

|
| [2] |
O. S. Sonbul, M. Rashid, Algorithms and techniques for the structural health monitoring of bridges: systematic literature review, Sensors, 23 (2023), 4230. https://doi.org/10.3390/s23094230 doi: 10.3390/s23094230
|
| [3] |
M. Shibu, K. P. Kumar, V. J. Pillai, H. Murthy, S. Chandra, Structural health monitoring using AI and ML based multimodal sensors data, Meas. Sens., 27 (2023), 100762. https://doi.org/10.1016/j.measen.2023.100762 doi: 10.1016/j.measen.2023.100762
|
| [4] |
Y. J. Cha, R. Ali, J. Lewis, O. Büyüköztürk, Deep learning-based structural health monitoring, Automat. Constr., 161 (2024), 105328. https://doi.org/10.1016/j.autcon.2024.105328 doi: 10.1016/j.autcon.2024.105328
|
| [5] |
A. Anjum, M. Hrairi, A. Aabid, N. Yatim, M. Ali, Civil structural health monitoring and machine learning: a comprehensive review, Fratt. Integr. Strutturale, 69 (2024), 43–59. https://doi.org/10.3221/IGF-ESIS.69.04 doi: 10.3221/IGF-ESIS.69.04
|
| [6] |
M. Rodrigues, V. L. Miguéis, C. Felix, C. Rodrigues, Machine learning and cointegration for structural health monitoring of a model under environmental effects, Expert Syst. Appl., 238 (2024), 121739. https://doi.org/10.1016/j.eswa.2023.121739 doi: 10.1016/j.eswa.2023.121739
|
| [7] |
H. Son, Y. Jang, S. E. Kim, D. Kim, J. W. Park, Deep learning-based anomaly detection to classify inaccurate data and damaged condition of a cable-stayed bridge, IEEE Access, 9 (2021), 124549–124559. https://doi.org/10.1109/ACCESS.2021.3100419 doi: 10.1109/ACCESS.2021.3100419
|
| [8] |
K. Maes, L. Van Meerbeeck, E. P. B. Reynders, G. Lombaert, Validation of vibration-based structural health monitoring on retrofitted railway bridge KW51, Mech. Syst. Signal Process., 165 (2022), 108380. https://doi.org/10.1016/j.ymssp.2021.108380 doi: 10.1016/j.ymssp.2021.108380
|
| [9] | C. R. Farrar, K. Worden, Structural health monitoring: a machine learning perspective, John Wiley and Sons, 2012. https://doi.org/10.1002/9781118443118 |
| [10] |
C. Scuro, F. Lamonaca, S. Porzio, G. Milani, R. S. Olivito, Internet of Things (IoT) for masonry structural health monitoring (SHM): overview and examples of innovative systems, Constr. Build. Mater., 290 (2021), 123092. https://doi.org/10.1016/j.conbuildmat.2021.123092 doi: 10.1016/j.conbuildmat.2021.123092
|
| [11] |
A. Malekloo, E. Ozer, M. AlHamaydeh, M. Girolami, Machine learning and structural health monitoring overview with emerging technology and high-dimensional data source highlights, Struct. Health Monit., 21 (2022), 1906–1955. https://doi.org/10.1177/14759217211036880 doi: 10.1177/14759217211036880
|
| [12] |
A. Pelle, B. Briseghella, G. Fiorentino, G. F. Giaccu, D. Lavorato, G. Quaranta, et al., Repair of reinforced concrete bridge columns subjected to chloride-induced corrosion with ultra-high performance fiber reinforced concrete, Struct. Concr., 24 (2023), 332–344. https://doi.org/10.1002/suco.202200555 doi: 10.1002/suco.202200555
|
| [13] |
M. Omori Yano, E. Figueiredo, S. da Silva, A. Cury, I. Moldovan, Transfer learning for structural health monitoring in bridges that underwent retrofitting, Buildings, 13 (2023), 2323. https://doi.org/10.3390/buildings13092323 doi: 10.3390/buildings13092323
|
| [14] | C. Flexa, W. Gomes, C. Sales, Data normalization in structural health monitoring by means of nonlinear filtering, 2019 8th Brazilian Conference on Intelligent Systems (BRACIS), 2019,204–209. https://doi.org/10.1109/BRACIS.2019.00044 |
| [15] |
K. Worden, L. A. Bull, P. Gardner, J. Gosliga, T. J. Rogers, E. J. Cross, et al., A brief introduction to recent developments in population-based structural health monitoring, Front. Built Environ., 6 (2020), 146. https://doi.org/10.3389/fbuil.2020.00146 doi: 10.3389/fbuil.2020.00146
|
| [16] |
P. Gardner, L. A. Bull, N. Dervilis, K. Worden, Domain-adapted Gaussian mixture models for population-based structural health monitoring, J. Civil Struct. Health Monit., 12 (2022), 1343–1353. https://doi.org/10.1007/s13349-022-00565-5 doi: 10.1007/s13349-022-00565-5
|
| [17] |
K. Maes, G. Lombaert, Monitoring railway bridge KW51 before, during, and after retrofitting, J. Bridge Eng., 26 (2021), 04721001. https://doi.org/10.1061/(ASCE)BE.1943-5592.0001668 doi: 10.1061/(ASCE)BE.1943-5592.0001668
|
| [18] |
P. Welch, The use of fast Fourier transform for the estimation of power spectra: a method based on time averaging over short, modified periodograms, IEEE Trans. Audio Electroacoust., 15 (1967), 70–73. https://doi.org/10.1109/TAU.1967.1161901 doi: 10.1109/TAU.1967.1161901
|
| [19] |
R. Katam, V. D. K. Pasupuleti, P. Kalapatapu, A review on structural health monitoring: past to present, Innov. Infrastruct. Solut., 8 (2023), 248. https://doi.org/10.1007/s41062-023-01217-3 doi: 10.1007/s41062-023-01217-3
|
| [20] |
F. A. Amjad, H. Toozandehjani, Time-Frequency analysis using Stockwell transform with application to guided wave structural health monitoring, Iran. J. Sci. Technol. Trans. Civ. Eng., 47 (2023), 3627–3647. https://doi.org/10.1007/s40996-023-01224-5 doi: 10.1007/s40996-023-01224-5
|
| [21] | I. T. Joliffe, Principal component analysis, 2 Eds., Springer, 2011. |
| [22] |
D. H. Wolpert, W. G. Macready, No free lunch theorems for optimization, IEEE Trans. Evolut. Comput., 1 (1997), 67–82. https://doi.org/10.1109/4235.585893 doi: 10.1109/4235.585893
|
| [23] | T. K. Ho, Random decision forests, Proceedings of 3rd International Conference on Document Analysis and Recognition, 1 (1995), 278–282. https://doi.org/10.1109/ICDAR.1995.598994 |
| [24] |
L. Breiman, Random forests, Mach. Learn., 45 (2001), 5–32. https://doi.org/10.1023/A:1010933404324 doi: 10.1023/A:1010933404324
|
| [25] |
M. C. Cheng, M. Bonopera, L. J. Leu, Applying random forest algorithm for highway bridge-type prediction in areas with a high seismic risk, J. Chin. Inst. Eng., 47 (2024), 597–610. https://doi.org/10.1080/02533839.2024.2368464 doi: 10.1080/02533839.2024.2368464
|
| [26] | T. Hastie, R. Tibshirani, J. Friedman, The elements of statistical learning: data mining, inference and prediction, 2 Eds., Springer-Verlag, 2009. https://doi.org/10.1007/978-0-387-84858-7 |
Figures(15)

A. Presno Vélez, M. Z. Fernández Muñiz, J. L. Fernández Martínez. Enhancing structural health monitoring with machine learning for accurate prediction of retrofitting effects[J]. AIMS Mathematics, 2024, 9(11): 30493-30514. doi: 10.3934/math.20241472







 DownLoad:
DownLoad: