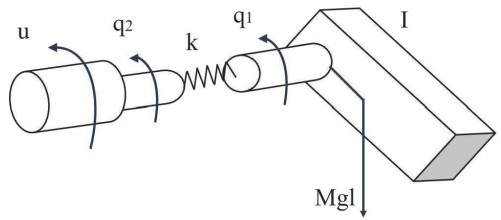
In this paper, we investigated the optimal tracking control problem of flexible-joint robotic manipulators in order to achieve trajectory tracking, and at the same time reduced the energy consumption of the feedback controller. Technically, optimization strategies were well-integrated into backstepping recursive design so that a series of optimized controllers for each subsystem could be constructed to improve the closed-loop system performance, and, additionally, a reinforcement learning method strategy based on neural network actor-critic architecture was adopted to approximate unknown terms in control design, making that the Hamilton-Jacobi-Bellman equation solvable in the sense of optimal control. With our scheme, the closed-loop stability, the convergence of output tracking error can be proved rigorously. Besides theoretical analysis, the effectiveness of our scheme was also illustrated by simulation results.
Citation: Huihui Zhong, Weijian Wen, Jianjun Fan, Weijun Yang. Reinforcement learning-based adaptive tracking control for flexible-joint robotic manipulators[J]. AIMS Mathematics, 2024, 9(10): 27330-27360. doi: 10.3934/math.20241328
In this paper, we investigated the optimal tracking control problem of flexible-joint robotic manipulators in order to achieve trajectory tracking, and at the same time reduced the energy consumption of the feedback controller. Technically, optimization strategies were well-integrated into backstepping recursive design so that a series of optimized controllers for each subsystem could be constructed to improve the closed-loop system performance, and, additionally, a reinforcement learning method strategy based on neural network actor-critic architecture was adopted to approximate unknown terms in control design, making that the Hamilton-Jacobi-Bellman equation solvable in the sense of optimal control. With our scheme, the closed-loop stability, the convergence of output tracking error can be proved rigorously. Besides theoretical analysis, the effectiveness of our scheme was also illustrated by simulation results.

| [1] |
Z. Li, S. Li, X. Luo, An overview of calibration technology of industrial robots, IEEE-CAA J. Automatica Sin., 8 (2021), 23–36. https://doi.org/10.1109/JAS.2020.1003381 doi: 10.1109/JAS.2020.1003381

|
| [2] |
M. Kyrarini, F. Lygerakis, A. Rajavenkatanarayanan, C. Sevastopoulos, H. R. Nambiappan, K. K. Chaitanya, et al., A survey of robots in healthcare, Technologies, 9 (2021), 8. https://doi.org/10.3390/technologies9010008 doi: 10.3390/technologies9010008
|
| [3] | M. Payal, P. Dixit, T. V. M. Sairam, N. Goyal, Robotics, AI, and the IoT in defense systems, In: AI and IoT-based intelligent automation in robotics, Wiley, 2021. https://doi.org/10.1002/9781119711230.ch7 |
| [4] | Q. Qi, G. Qin, Z. Yang, G. Chen, J. Xu, Z. Lv, et al., Design and motion control of a tendon-driven continuum robot for aerospace applications, P. I. Mech. Eng. G J. Aer., 2024. https://doi.org/10.1177/09544100241263004 |
| [5] | M. Sostero, Automation and robots in services: Review of data and taxonomy, In: JRC working papers series on labour, education and technology, Joint Research Centre, 2020. |
| [6] |
Q. Yang, X. Du, Z. Wang, Z. Meng, Z. Ma, Q. Zhang, A review of core agricultural robot technologies for crop productions, Comput. Electron. Agr., 206 (2023), 107701. https://doi.org/10.1016/j.compag.2023.107701 doi: 10.1016/j.compag.2023.107701
|
| [7] |
I. Arocena, A. Huegun-Burgos, I. Rekalde-Rodriguez, Robotics and education: A systematic review, TEM J., 11 (2022), 379–387. https://doi.org/10.18421/TEM111-48 doi: 10.18421/TEM111-48
|
| [8] |
C. E. Boudjedir, M. Bouri, D. Boukhetala, An enhanced adaptive time delay control-based integral sliding mode for trajectory tracking of robot manipulators, IEEE Trans. Control Syst. Technol., 31 (2023), 1042–1050. http://dx.doi.org/10.1109/TCST.2022.3208491 doi: 10.1109/TCST.2022.3208491
|
| [9] |
P. Li, D. Liu, S. Baldi, Adaptive integral sliding mode control in the presence of state-dependent uncertainty, IEEE-ASME Trans. Mechatron., 27 (2022), 3885–3895. http://dx.doi.org/10.1109/TMECH.2022.3145910 doi: 10.1109/TMECH.2022.3145910
|
| [10] |
J. Park, W. Kwon, P. Park, An improved adaptive sliding mode control based on time-delay control for robot manipulators, IEEE Trans. Ind. Electron., 70 (2023), 10363–10373. http://dx.doi.org/10.1109/TIE.2022.3222616 doi: 10.1109/TIE.2022.3222616
|
| [11] |
H. Ma, H. Ren, Q. Zhou, H. Li, Z. Wang, Observer-based neural control of N-link flexible-joint robots, IEEE Trans. Neural Netw. Learn. Syst., 35 (2024), 5295–5305. https://doi.org/10.1109/TNNLS.2022.3203074 doi: 10.1109/TNNLS.2022.3203074
|
| [12] |
Y. Xie, Q. Ma, J. Gu, G. Zhou, Event-triggered fixed-time practical tracking control for flexible-joint robot, IEEE Trans. Fuzzy Syst., 31 (2023), 67–76. https://doi.org/10.1109/TFUZZ.2022.3181463 doi: 10.1109/TFUZZ.2022.3181463
|
| [13] |
M. M. Arefi, N. Vafamand, B. Homayoun, M. Davoodi, Command filtered backstepping control of constrained flexible joint robotic manipulator, IET Control Theory Appl., 17 (2023), 2506–2518. https://doi.org/10.1049/cth2.12528 doi: 10.1049/cth2.12528
|
| [14] |
X. Cheng, Y. J. Zhang, H. S. Liu, D. Wollherr, M. Buss, Adaptive neural backstepping control for flexible-joint robot manipulator with bounded torque inputs, Neurocomputing, 458 (2021), 70–86. https://doi.org/10.1016/j.neucom.2021.06.013 doi: 10.1016/j.neucom.2021.06.013
|
| [15] |
Y. Zhang, M. Zhang, F. Du, Robust finite-time command-filtered backstepping control for flexible-joint robots with only position measurements, IEEE Trans. Syst. Man Cybern. Syst., 54 (2024), 1263–1275. https://doi.org/10.1109/TSMC.2023.3324761 doi: 10.1109/TSMC.2023.3324761
|
| [16] |
R. Datouo, J. J. B. M. Ahanda, A. Melingui, F. Biya-Motto, B. E. Zobo, Adaptive fuzzy finite-time command-filtered backstepping control of flexible-joint robots, Robotica, 39 (2021), 1081–1100. https://doi.org/10.1017/S0263574720000910 doi: 10.1017/S0263574720000910
|
| [17] |
U. K. Sahu, B. Subudhi, D. Patra, Sampled-data extended state observer-based backstepping control of two-link flexible manipulator, Trans. Inst. Meas. Control, 41 (2019), 3581–3599. https://doi.org/10.1177/0142331219832954 doi: 10.1177/0142331219832954
|
| [18] |
J. Li, L. Zhu, Practical tracking control under actuator saturation for a class of flexible-joint robotic manipulators driven by DC motors, Nonlinear Dyn., 109 (2022), 2745–2758. https://doi.org/10.1007/s11071-022-07602-4 doi: 10.1007/s11071-022-07602-4
|
| [19] |
G. Lai, S. Zou, H. Xiao, L. Wang, Z. Liu, K. Chen, Fixed-time adaptive fuzzy control with prescribed tracking performances for flexible-joint manipulators, J. Franklin Inst., 361 (2024), 106809. https://doi.org/10.1016/j.jfranklin.2024.106809 doi: 10.1016/j.jfranklin.2024.106809
|
| [20] | R. Bellman, Dynamic programming, Science, 153 (1966), 34–37. https://doi.org/10.1126/science.153.3731.34 |
| [21] | L. S. Pontryagin, Mathematical theory of optimal processes, London: Routledge, 2017. https://doi.org/10.1201/9780203749319 |
| [22] |
Y. Yang, H. Modares, K. G. Vamvoudakis, W. He, C. Z. Xu, D. C. Wunsch, Hamiltonian-driven adaptive dynamic programming with approximation errors, IEEE Trans. Cybern., 52 (2022), 13762–13773. https://doi.org/10.1109/TCYB.2021.3108034 doi: 10.1109/TCYB.2021.3108034
|
| [23] | P. J. Werbos, Neural networks for control and system identification, In: Proceedings of the 28th IEEE conference on decision and control, 1 (1989), 260–265. https://doi.org/10.1109/CDC.1989.70114 |
| [24] | W. T. Miller, R. S. Sutton, P. J. Webros, A menu of designs for reinforcement learning over time, In: Neural networks for control, MIT Press, 1995, 67–95. |
| [25] | P. J. Webros, Approximate dynamic programming for real-time control and neural modeling, In: Handbook of intelligent control: Neural fuzzy and adaptive approaches, New York: Van Nostrand Reinhold, 1992. |
| [26] |
G. Lai, Y. Zhang, Z. Liu, J. Wang, K. Chen, C. L. P. Chen, Direct adaptive fuzzy control scheme with guaranteed tracking performances for uncertain canonical nonlinear systems, IEEE Trans. Fuzzy Syst., 30 (2022), 818–829. https://doi.org/10.1109/TFUZZ.2021.3049902 doi: 10.1109/TFUZZ.2021.3049902
|
| [27] |
Y. Wang, Y. Chang, A. F. Alkhateeb, N. D. Alotaibi, Adaptive fuzzy output-feedback tracking control for switched nonstrict-feedback nonlinear systems with prescribed performance, Circuits Syst. Signal Process., 40 (2021), 88–113. https://doi.org/10.1007/s00034-020-01466-y doi: 10.1007/s00034-020-01466-y
|
| [28] |
D. Wang, M. Ha, M. Zhao, The intelligent critic framework for advanced optimal control, Artif. Intell. Rev., 55 (2022), 1–22. https://doi.org/10.1007/s10462-021-10118-9 doi: 10.1007/s10462-021-10118-9
|
| [29] | D. Li, J. Dong, Fractional-order systems optimal control via actor-critic reinforcement learning and its validation for chaotic MFET, IEEE Trans. Autom. Sci. Eng., 2024, 1–10. https://doi.org/10.1109/TASE.2024.3361213 |
| [30] |
D. Cui, C. K. Ahn, Y. Sun, Z. Xiang, Mode-dependent state observer-based prescribed performance control of switched systems, IEEE Trans. Circuits Syst. Ⅱ-Express Briefs, 71 (2024), 3810–3814. https://doi.org/10.1109/TCSII.2024.3370865 doi: 10.1109/TCSII.2024.3370865
|
| [31] |
H. Jiang, W. Su, B. Niu, H. Wang, J. Zhang, Adaptive neural consensus tracking control of distributed nonlinear multiagent systems with unmodeled dynamics, Int. J. Robust Nonlinear Control, 32 (2022), 8999–9016. https://doi.org/10.1002/rnc.6313 doi: 10.1002/rnc.6313
|
| [32] |
G. Lai, Y. Zhang, Z. Liu, C. L. P. Chen, Indirect adaptive fuzzy control design with guaranteed tracking error performance for uncertain canonical nonlinear systems, IEEE Trans. Fuzzy Syst., 27 (2019), 1139–1150. https://doi.org/10.1109/TFUZZ.2018.2870574 doi: 10.1109/TFUZZ.2018.2870574
|










Figures(11) / Tables(1)

Huihui Zhong, Weijian Wen, Jianjun Fan, Weijun Yang. Reinforcement learning-based adaptive tracking control for flexible-joint robotic manipulators[J]. AIMS Mathematics, 2024, 9(10): 27330-27360. doi: 10.3934/math.20241328







 DownLoad:
DownLoad: