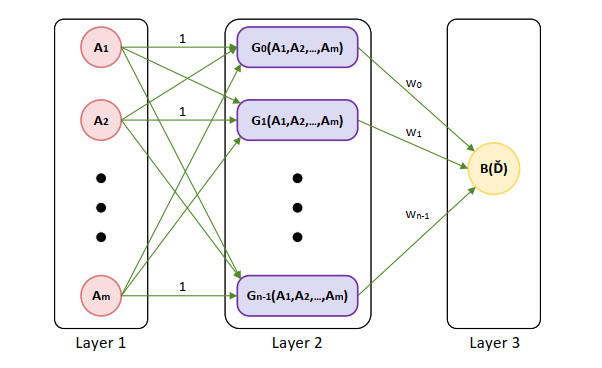
Undoubtedly, one of the most common machine learning challenges is multiclass classification. In light of this, a novel bio-inspired neural network (NN) has been developed to address multiclass classification-related issues. Given that weights and structure determination (WASD) NNs have been acknowledged to alleviate the disadvantages of conventional back-propagation NNs, such as slow training pace and trapping in a local minimum, we developed a bio-inspired WASD algorithm for multiclass classification problems (BWASDC) by using the metaheuristic beetle antennae search (BAS) algorithm to enhance the WASD algorithm's learning process. The BWASDC's effectiveness is then evaluated through applications in occupational classification systems. It is important to mention that systems of occupational classification serve as a fundamental indicator of occupational exposure. For this reason, they are highly significant in social science research. According to the findings of four occupational classification experiments, the BWASDC model outperformed some of the most modern classification models obtainable through MATLAB's classification learner app on all fronts.
Citation: Yu He, Xiaofan Dong, Theodore E. Simos, Spyridon D. Mourtas, Vasilios N. Katsikis, Dimitris Lagios, Panagiotis Zervas, Giannis Tzimas. A bio-inspired weights and structure determination neural network for multiclass classification: Applications in occupational classification systems[J]. AIMS Mathematics, 2024, 9(1): 2411-2434. doi: 10.3934/math.2024119
Undoubtedly, one of the most common machine learning challenges is multiclass classification. In light of this, a novel bio-inspired neural network (NN) has been developed to address multiclass classification-related issues. Given that weights and structure determination (WASD) NNs have been acknowledged to alleviate the disadvantages of conventional back-propagation NNs, such as slow training pace and trapping in a local minimum, we developed a bio-inspired WASD algorithm for multiclass classification problems (BWASDC) by using the metaheuristic beetle antennae search (BAS) algorithm to enhance the WASD algorithm's learning process. The BWASDC's effectiveness is then evaluated through applications in occupational classification systems. It is important to mention that systems of occupational classification serve as a fundamental indicator of occupational exposure. For this reason, they are highly significant in social science research. According to the findings of four occupational classification experiments, the BWASDC model outperformed some of the most modern classification models obtainable through MATLAB's classification learner app on all fronts.

| [1] |
E. Felten, M. Raj, R. Seamans, Occupational, industry, and geographic exposure to artificial intelligence: A novel dataset and its potential uses, Strategic. Manage. J., 42 (2021), 2195–2217. https://doi.org/10.1002/smj.3286 doi: 10.1002/smj.3286

|
| [2] | E. W. Felten, M. Raj, R. Seamans, The occupational impact of artificial intelligence: Labor, skills, and polarization, NYU Stern School of Business, 2019. https://doi.org/10.2139/ssrn.3368605 |
| [3] |
B. Bigdeli, P. Pahlavani, H. A. Amirkolaee, An ensemble deep learning method as data fusion system for remote sensing multisensor classification, Appl. Soft Comput., 110 (2021), 107563. https://doi.org/10.1016/j.asoc.2021.107563 doi: 10.1016/j.asoc.2021.107563
|
| [4] |
R. J. S. Raj, S. J. Shobana, I. V. Pustokhina, D. A. Pustokhin, D. Gupta, K. Shankar, Optimal feature selection-based medical image classification using deep learning model in internet of medical things, IEEE Access, 8 (2020), 58006–58017. https://doi.org/10.1109/ACCESS.2020.2981337 doi: 10.1109/ACCESS.2020.2981337
|
| [5] |
T. E. Simos, V. N. Katsikis, S. D. Mourtas, A multi-input with multi-function activated weights and structure determination neuronet for classification problems and applications in firm fraud and loan approval, Appl. Soft Comput., 127 (2022), 109351. https://doi.org/10.1016/j.asoc.2022.109351 doi: 10.1016/j.asoc.2022.109351
|
| [6] | G. Varelas, D. Lagios, S. Ntouroukis, P. Zervas, K. Parsons, G. Tzimas, Employing natural language processing techniques for online job vacancies classification, in Artificial Intelligence Applications and Innovations. AIAI 2022 IFIP WG 12.5 International Workshops. AIAI 2022 (eds. I. Maglogiannis, L. Iliadis, J. Macintyre and P. Cortez), vol. 652 of IFIP Advances in Information and Communication Technology, Springer, Cham, 2022,333–344. |
| [7] |
A. Rácz, D. Bajusz, K. Héberger, Effect of dataset size and train/test split ratios in QSAR/QSPR multiclass classification, Molecules, 26 (2021), 1111. https://doi.org/10.3390/molecules26041111 doi: 10.3390/molecules26041111
|
| [8] |
R. Venkatesan, M. J. Er, A novel progressive learning technique for multi-class classification, Neurocomputing, 207 (2016), 310–321. https://doi.org/10.1016/j.neucom.2016.05.006 doi: 10.1016/j.neucom.2016.05.006
|
| [9] | T. E. Simos, V. N. Katsikis, S. D. Mourtas, P. S. Stanimirović, Unique non-negative definite solution of the time-varying algebraic {R}iccati equations with applications to stabilization of LTV systems, Math. Comput. Simul., 202 (2022), 164–180. |
| [10] | S. D. Mourtas, V. N. Katsikis, C. Kasimis, Feedback control systems stabilization using a bio-inspired neural network, EAI Endorsed Trans. AI Robot, 1 (2022), 1–13. |
| [11] |
N. Premalatha, A. V. Arasu, Prediction of solar radiation for solar systems by using ANN models with different back propagation algorithms, J. Appl. Res. Technol., 14 (2016), 206–214. https://doi.org/10.1016/j.jart.2016.05.001 doi: 10.1016/j.jart.2016.05.001
|
| [12] | C. Huang, X. Jia, Z. Zhang, A modified back propagation artificial neural network model based on genetic algorithm to predict the flow behavior of 5754 aluminum alloy, Materials, 11 (2018), 855. |
| [13] |
L. Chen, Z. Huang, Y. Li, N. Zeng, M. Liu, A. Peng, et al., Weight and structure determination neural network aided with double pseudoinversion for diagnosis of flat foot, IEEE Access, 7 (2019), 33001–33008. https://doi.org/10.1109/ACCESS.2019.2903634 doi: 10.1109/ACCESS.2019.2903634
|
| [14] |
T. E. Simos, V. N. Katsikis, S. D. Mourtas, A fuzzy WASD neuronet with application in breast cancer prediction, Neural Comput. Appl., 34 (2021), 3019–3031. https://doi.org/10.1007/s00521-021-06572-9 doi: 10.1007/s00521-021-06572-9
|
| [15] |
M. R. Daliri, A hybrid automatic system for the diagnosis of lung cancer based on genetic algorithm and fuzzy extreme learning machines, J. Medical Syst., 36 (2012), 1001–1005. https://doi.org/10.1007/s10916-011-9806-y doi: 10.1007/s10916-011-9806-y
|
| [16] | S. Gayathri, A. K. Krishna, V. P. Gopi, P. Palanisamy, Automated binary and multiclass classification of diabetic retinopathy using Haralick and multiresolution features, IEEE Access, 8 (2020), 57497–57504. https://doi.org/10.1109/ACCESS.2020.2979753 |
| [17] |
S. D. Mourtas, V. N. Katsikis, Exploiting the Black-Litterman framework through error-correction neural networks, Neurocomputing, 498 (2022), 43–58. https://doi.org/10.1016/j.neucom.2022.05.036 doi: 10.1016/j.neucom.2022.05.036
|
| [18] |
S. D. Mourtas, V. N. Katsikis, E. Drakonakis, S. Kotsios, Stabilization of stochastic exchange rate dynamics under central bank intervention using neuronets, Int. J. Inf. Technol. Decis., 22 (2023), 855–883. https://doi.org/10.1142/s0219622022500560 doi: 10.1142/s0219622022500560
|
| [19] |
S. D. Mourtas, A weights direct determination neuronet for time-series with applications in the industrial indices of the federal reserve bank of St. Louis, J. Forecast., 14 (2022), 1512–1524. https://doi.org/10.1002/for.2874 doi: 10.1002/for.2874
|
| [20] |
T. E. Simos, V. N. Katsikis, S. D. Mourtas, Multi-input bio-inspired weights and structure determination neuronet with applications in European Central Bank publications, Math. Comput. Simul., 193 (2022), 451–465. https://doi.org/10.1016/j.matcom.2021.11.007 doi: 10.1016/j.matcom.2021.11.007
|
| [21] |
R. Boselli, M. Cesarini, S. Marrara, F. Mercorio, M. Mezzanzanica, G. Pasi, et al., WoLMIS: A labor market intelligence system for classifying web job vacancies, J. Intell. Inf. Syst., 51 (2018), 477–502. https://doi.org/10.1007/s10844-017-0488-x doi: 10.1007/s10844-017-0488-x
|
| [22] |
P. G. Lovaglio, M. Cesarini, F. Mercorio, M. Mezzanzanica, Skills in demand for ICT and statistical occupations: Evidence from web-based job vacancies, Stat. Anal. Data Min., 11 (2018), 78–91. https://doi.org/10.1002/sam.11372 doi: 10.1002/sam.11372
|
| [23] |
E. Heinesen, S. Imai, S. Maruyama, Employment, job skills and occupational mobility of cancer survivors, J. Health Econ., 58 (2018), 151–175. https://doi.org/10.1016/j.jhealeco.2018.01.006 doi: 10.1016/j.jhealeco.2018.01.006
|
| [24] |
F. Groes, P. Kircher, I. Manovskii, The U-shapes of occupational mobility, Rev. Econ. Stud., 82 (2015), 659–692. https://doi.org/10.1093/restud/rdu037 doi: 10.1093/restud/rdu037
|
| [25] |
M. Khalis, B. Charbotel, E. Fort, V. Chajes, H. Charaka, K. E. Rhazi, Occupation and female breast cancer: A case-control study in Morocco, Rev. Epidemiol. Sante Publique, 66 (2018), S302. https://doi.org/10.1016/j.respe.2018.05.172 doi: 10.1016/j.respe.2018.05.172
|
| [26] |
I. N. Generalao, Measuring the telework potential of jobs: Evidence from the international standard classification of occupations, Philipp. Rev. Econ., 58 (2021), 92–127. https://doi.org/10.37907/5erp1202jd doi: 10.37907/5erp1202jd
|
| [27] | C. Züll, The coding of occupations, GESIS Survey Guidelines, Mannheim, Germany: GESIS – Leibniz Institute for the Social Sciences. |
| [28] |
S. B. Choi, J. H. Yoon, W. Lee, The modified international standard classification of occupations defined by the clustering of occupational characteristics in the Korean working conditions survey, Ind. Health, 58 (2020), 132–141. https://doi.org/10.2486/indhealth.2018-0169 doi: 10.2486/indhealth.2018-0169
|
| [29] | D. T. Marc, P. Dua, S. H. Fenton, K. Lalani, K. Butler-Henderson, The Health Information Workforce, chapter Occupational Classifications in the Health Information Disciplines, 71–78, Health Informatics. Springer, Cham., 2021. |
| [30] | J. Rounds, P. I. Armstrong, H. Y. Liao, D. Rivkin, P. Lewis, Second generation occupational value profiles for the O* NET system: Summary, Raleigh, NC: National Center for O* NET Development, 2008. |
| [31] |
M. P. Wilmot, D. S. Ones, Occupational characteristics moderate personality–performance relations in major occupational groups, J. Vocat. Behav., 131 (2021), 103655. https://doi.org/10.1016/j.jvb.2021.103655 doi: 10.1016/j.jvb.2021.103655
|
| [32] | M. Zhang, Estimation of differential occupational risk of COVID-19 by comparing risk factors with case data by occupational group, Am. J. Ind. Med., 64 (2021), 39–47. |
| [33] | W. Uter, Kanerva's Occupational Dermatology, chapter Classification of occupations, Springer, Berlin, Heidelberg, 2012. |
| [34] | E. Faia, S. Laffitte, M. Mayer, G. Ottaviano, On the employment consequences of automation and offshoring: A labor market sorting view, in Robots and AI, Routledge, 2021, 82–122. |
| [35] |
A. S. Ioshisaqui, R. Attux, I. Luna, Analysis of occupational profiles in the Brazilian workforce based on non-negative matrix factorization, Big Data Res., 29 (2022), 100333. https://doi.org/10.1016/j.bdr.2022.100333 doi: 10.1016/j.bdr.2022.100333
|
| [36] |
P. Egana-delSol, G. Cruz, A. Micco, COVID-19 and automation in a developing economy: Evidence from Chile, Technol. Forecast. Soc. Change, 176 (2022), 121373. https://doi.org/10.1016/j.techfore.2021.121373 doi: 10.1016/j.techfore.2021.121373
|
| [37] |
R. Sebastian, Explaining job polarisation in Spain from a task perspective, SERIEs, 9 (2018), 215–248. https://doi.org/10.1007/s13209-018-0177-1 doi: 10.1007/s13209-018-0177-1
|
| [38] | Y. Zhang, D. Chen, C. Ye, Deep Neural Networks: WASD Neuronet Models, Algorithms, and Applications, CRC Press: Boca Raton, FL, USA, 2019. |
| [39] | X. Jiang, S. Li, BAS: Beetle antennae search algorithm for optimization problems, arXiv preprint, abs/1710.10724, 2017. Available from: http://arXiv.org/abs/1710.10724 |
| [40] |
T. E. Simos, S. D. Mourtas, V. N. Katsikis, Time-varying Black-Litterman portfolio optimization using a bio-inspired approach and neuronets, Appl. Soft Comput., 112 (2021), 107767. https://doi.org/10.1016/j.asoc.2021.107767 doi: 10.1016/j.asoc.2021.107767
|
| [41] |
Y. Cheng, C. Li, S. Li, Z. Li, Motion planning of redundant manipulator with variable joint velocity limit based on beetle antennae search algorithm, IEEE Access, 8 (2020), 138788–138799. https://doi.org/10.1109/ACCESS.2020.3012564 doi: 10.1109/ACCESS.2020.3012564
|
| [42] | X. Li, H. Jiang, M. Niu, R. Wang, An enhanced selective ensemble deep learning method for rolling bearing fault diagnosis with beetle antennae search algorithm, Mech. Syst. Signal Process., 142 (2020), 106752. |
| [43] | X. Li, Z. Zang, F. Shen, Y. Sun, Task offloading scheme based on improved contract net protocol and beetle antennae search algorithm in fog computing networks, Mobile Netw. Appl. 25 (2020), 2517–2526. https://doi.org/10.1109/ACCESS.2020.3012564 |
| [44] |
Y. Fan, J. Shao, G. Sun, Optimized PID controller based on beetle antennae search algorithm for electro-hydraulic position servo control system, Sensors, 19 (2019), 2727. https://doi.org/10.3390/s19122727 doi: 10.3390/s19122727
|
| [45] |
S. D. Mourtas, V. N. Katsikis, V-shaped BAS: Applications on large portfolios selection problem, Comput. Econ., 60 (2022), 1353–1373. https://doi.org/10.1007/s10614-021-10184-9 doi: 10.1007/s10614-021-10184-9
|
| [46] |
V. N. Katsikis, S. D. Mourtas, Diversification of time-varying tangency portfolio under nonlinear constraints through semi-integer beetle antennae search algorithm, Appl. Math., 1 (2021), 63–73. https://doi.org/10.3390/appliedmath1010005 doi: 10.3390/appliedmath1010005
|
| [47] | P. Kim, MATLAB Deep Learning: With Machine Learning, Neural Networks and Artificial Intelligence, Apress: Berkeley, CA, USA, 2017. |
| [48] | Transformer models for MATLAB, 2023. Available from: https://github.com/matlab-deep-learning/transformer-models |
| [49] | Y. Zhang, X. Yu, L. Xiao, W. Li, Z. Fan, W. Zhang, Weights and structure determination of articial neuronets, in Self-Organization: Theories and Methods, New York, NY, USA: Nova Science, 2013. |
| [50] | Z. Zhu, Z. Zhang, W. Man, X. Tong, J. Qiu, F. Li, A new beetle antennae search algorithm for multi-objective energy management in microgrid, in Proc. 13th IEEE Conf. Industrial Electronics and Applications (ICIEA), 2018, 1599–1603. |
| [51] |
Q. Wu, X. Shen, Y. Jin, Z. Chen, S. Li, A. H. Khan, et al., Intelligent beetle antennae search for UAV sensing and avoidance of obstacles, Sensors, 19 (2019), 1758. https://doi.org/10.3390/s19081758 doi: 10.3390/s19081758
|
| [52] |
X. Xu, K. Deng, B. Shen, A beetle antennae search algorithm based on Lévy flights and adaptive strategy, Syst. Sci. Control. Eng., 8 (2020), 35–47. https://doi.org/10.1080/21642583.2019.1708829 doi: 10.1080/21642583.2019.1708829
|
| [53] | M. Davis, L. Iancu, Unicode text segmentation, Unicode Standard Annex, 29 (2018), 65. https://doi.org/10.4324/9780429955600-9 |
| [54] | A. K. Gupta, Numerical methods using MATLAB, MATLAB solutions series, Apress: Berkeley, CA, USA, New York, NY, 2014. |
| [55] |
A. Tharwat, Classification assessment methods, Appl. Comput. Inform., 17 (2020), 168–192. https://doi.org/10.1016/j.aci.2018.08.003 doi: 10.1016/j.aci.2018.08.003
|
| [56] |
M. L. McHugh, Interrater reliability: the kappa statistic, Biochem. Med., 22 (2012), 276–282. https://doi.org/10.11613/bm.2012.031 doi: 10.11613/bm.2012.031
|







Figures(8) / Tables(4)

Yu He, Xiaofan Dong, Theodore E. Simos, Spyridon D. Mourtas, Vasilios N. Katsikis, Dimitris Lagios, Panagiotis Zervas, Giannis Tzimas. A bio-inspired weights and structure determination neural network for multiclass classification: Applications in occupational classification systems[J]. AIMS Mathematics, 2024, 9(1): 2411-2434. doi: 10.3934/math.2024119







 DownLoad:
DownLoad: