This paper investigates the optimality of the risk probability for finite horizon partially observable discrete-time Markov decision processes (POMDPs). The probability of the risk is optimized based on the criterion of total rewards not exceeding the preset goal value, which is different from the optimal problem of expected rewards. Based on the Bayes operator and the filter equations, the optimization problem of risk probability can be equivalently reformulated as filtered Markov decision processes. As an advantage of developing the value iteration technique, the optimality equation satisfied by the value function is established and the existence of the risk probability optimal policy is proven. Finally, an example is given to illustrate the effectiveness of using the value iteration algorithm to compute the value function and optimal policy.
Citation: Xian Wen, Haifeng Huo, Jinhua Cui. The optimal probability of the risk for finite horizon partially observable Markov decision processes[J]. AIMS Mathematics, 2023, 8(12): 28435-28449. doi: 10.3934/math.20231455
This paper investigates the optimality of the risk probability for finite horizon partially observable discrete-time Markov decision processes (POMDPs). The probability of the risk is optimized based on the criterion of total rewards not exceeding the preset goal value, which is different from the optimal problem of expected rewards. Based on the Bayes operator and the filter equations, the optimization problem of risk probability can be equivalently reformulated as filtered Markov decision processes. As an advantage of developing the value iteration technique, the optimality equation satisfied by the value function is established and the existence of the risk probability optimal policy is proven. Finally, an example is given to illustrate the effectiveness of using the value iteration algorithm to compute the value function and optimal policy.

| [1] | N. Bauerle, U. Rieder, Markov decision processes with applications to finance, Heidelberg: Springer, 2011. https://doi.org/10.1007/978-3-642-18324-9 |
| [2] | J. Janssen, R. Manca, Semi-Markov risk models for finance, insurance and reliability, New York: Springer, 2006. https://doi.org/10.1007/0-387-70730-1 |
| [3] | X. P. Guo, O. Hernández-Lerma, Continuous-time Markov decision processes: Theorey and applications, Berlin: Springer-Verlag, 2009. https://doi.org/10.1007/978-3-642-02547-1 |
| [4] |
M. J. Sobel, The variance of discounted Markov decision processes, J. Appl. Probab., 19 (1982), 794–802. https://doi.org/10.1017/s0021900200023123 doi: 10.1017/s0021900200023123

|
| [5] |
Y. Ohtsubo, K. Toyonaga, Optimal policy for minimizing risk models in Markov decision processes, J. Math. Anal. Appl., 271 (2002), 66–81. https://doi.org/10.1016/s0022-247x(02)00097-5 doi: 10.1016/s0022-247x(02)00097-5
|
| [6] |
D. J. White, Minimizing a threshold probability in discounted Markov decision processes, J. Math. Anal. Appl., 173 (1993), 634–646. https://doi.org/10.1006/jmaa.1993.1093 doi: 10.1006/jmaa.1993.1093
|
| [7] |
C. B. Wu, Y. L. Lin, Minimizing risk models in Markov decision processes with policies depending on target values, J. Math. Anal. Appl., 231 (1999), 47–67. https://doi.org/10.1006/jmaa.1998.6203 doi: 10.1006/jmaa.1998.6203
|
| [8] |
X. Wu, X. P. Guo, First passage optimality and variance minimization of Markov decision processes with varying discount factors, J. Appl. Probab., 52 (2015), 441–456. https://doi.org/10.1017/S0021900200012560 doi: 10.1017/S0021900200012560
|
| [9] |
Y. H. Huang, X. P. Guo, Optimal risk probability for first passage models in Semi-Markov processes, J. Math. Anal. Appl., 359 (2009), 404–420. https://doi.org/10.1016/j.jmaa.2009.05.058 doi: 10.1016/j.jmaa.2009.05.058
|
| [10] |
Y. H. Huang, X. P. Guo, Z. F. Li, Minimum risk probability for finite horizon semi-Markov decision processes, J. Math. Anal. Appl., 402 (2013), 378–391. https://doi.org/10.1016/j.jmaa.2013.01.021 doi: 10.1016/j.jmaa.2013.01.021
|
| [11] |
X. X. Huang, X. L. Zou, X. P. Guo, A minimization problem of the risk probability in first passage semi-Markov decision processes with loss rates, Sci. China Math., 58 (2015), 1923–1938. https://doi.org/10.1007/s11425-015-5029-x doi: 10.1007/s11425-015-5029-x
|
| [12] |
H. F. Huo, X. L. Zou, X. P. Guo, The risk probability criterion for discounted continuous-time Markov decision processes, Discrete Event Dyn. syst., 27 (2017), 675–699. https://doi.org/10.1007/s10626-017-0257-6 doi: 10.1007/s10626-017-0257-6
|
| [13] |
H. F. Huo, X. Wen, First passage risk probability optimality for continuous time Markov decision processes, Kybernetika, 55 (2019), 114–133. https://doi.org/10.14736/kyb-2019-1-0114 doi: 10.14736/kyb-2019-1-0114
|
| [14] |
H. F. Huo, X. P. Guo, Risk probability minimization problems for continuous time Markov decision processes on finite horizon, IEEE T. Automat. Contr., 65 (2020), 3199–3206. https://doi.org/10.1109/tac.2019.2947654 doi: 10.1109/tac.2019.2947654
|
| [15] |
X. Wen, H. F. Huo, X. P. Guo, First passage risk probability minimization for piecewise deterministic Markov decision processes, Acta Math. Appl. Sin. Engl. Ser., 38 (2022), 549–567. https://doi.org/10.1007/s10255-022-1098-0 doi: 10.1007/s10255-022-1098-0
|
| [16] | A. Drake, Observation of a Markov process through a noisy channel, Massachusetts Institute of Technology, 1962. |
| [17] | K. Hinderer, Foundations of non-stationary dynamic programming with discrete time parameter, Berlin: Springer-Verlag, 1970. |
| [18] |
D. Rhenius, Incomplete information in Markovian decision models, Ann. Statist., 26 (1974), 1327–1334. https://doi.org/10.1214/aos/1176342886 doi: 10.1214/aos/1176342886
|
| [19] | O. Hernández-Lerma, Adaptive Markov control processes, New York: Springer-Verlag, 1989. https://doi.org/10.1007/978-1-4419-8714-3 |
| [20] |
R. D. Smallwood, E. J. Sondik, The optimal control of partially observable Markov processes over a finite horizon, Oper. Res., 21 (1973), 1071–1088. https://doi.org/10.1287/opre.21.5.1071 doi: 10.1287/opre.21.5.1071
|
| [21] |
K. Sawaki, A. Ichikawa, Optimal control for partially observable Markov decision processes over an infinite horizon, J. Oper. Res. Soc. JPN, 21 (1978), 1–16. https://doi.org/10.15807/jorsj.21.1 doi: 10.15807/jorsj.21.1
|
| [22] |
C. C.White, W. T. Scherer, Finite memory suboptimal design for partially observed Markov decision processes, Oper. Res., 42 (1994), 439–455. https://doi.org/10.1287/opre.42.3.439 doi: 10.1287/opre.42.3.439
|
| [23] |
E. A. Feinberg, P. O. Kasyanov, M. Z. Zgurovsky, Partially observable total cost Markov decision processes with weakly continuous transition probabilities, Math. Oper. Res., 41 (2016), 656–681. https://doi.org/10.1287/moor.2015.0746 doi: 10.1287/moor.2015.0746
|
| [24] |
M. Haklidir, H. Temeltas, Guided soft actor critic: A guided deep reinforcement learning approach for partially observable Markov decision processes, IEEE Access, 9 (2021), 159672–159683. https://doi.org/10.1109/access.2021.3131772 doi: 10.1109/access.2021.3131772
|
| [25] | D. Bertsekas, S. Shreve, Stochastic optimal control: The discrete-time case, Athena Scientific, 1996. |
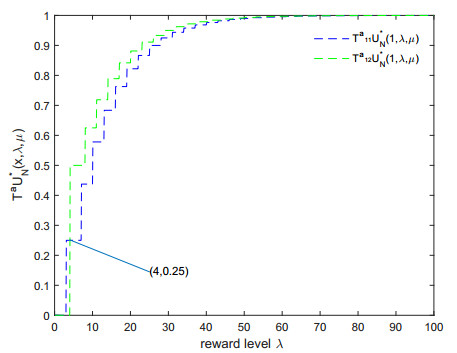

Figures(2)

Xian Wen, Haifeng Huo, Jinhua Cui. The optimal probability of the risk for finite horizon partially observable Markov decision processes[J]. AIMS Mathematics, 2023, 8(12): 28435-28449. doi: 10.3934/math.20231455







 DownLoad:
DownLoad: