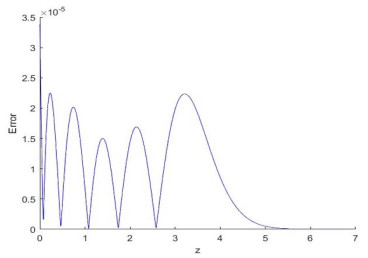
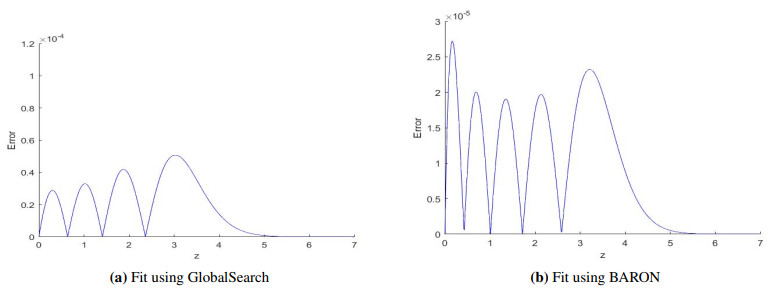
This paper proposes a new very simply explicitly invertible function to approximate the standard normal cumulative distribution function (CDF). The new function was fit to the standard normal CDF using both MATLAB's Global Optimization Toolbox and the BARON software package. The results of three separate fits are presented in this paper. Each fit was performed across the range $ 0 \leq z \leq 7 $ and achieved a maximum absolute error (MAE) superior to the best MAE reported for previously published very simply explicitly invertible approximations of the standard normal CDF. The best MAE reported from this study is 2.73e–05, which is nearly a factor of five better than the best MAE reported for other published very simply explicitly invertible approximations.
Citation: Jessica Lipoth, Yoseph Tereda, Simon Michael Papalexiou, Raymond J. Spiteri. A new very simply explicitly invertible approximation for the standard normal cumulative distribution function[J]. AIMS Mathematics, 2022, 7(7): 11635-11646. doi: 10.3934/math.2022648
This paper proposes a new very simply explicitly invertible function to approximate the standard normal cumulative distribution function (CDF). The new function was fit to the standard normal CDF using both MATLAB's Global Optimization Toolbox and the BARON software package. The results of three separate fits are presented in this paper. Each fit was performed across the range $ 0 \leq z \leq 7 $ and achieved a maximum absolute error (MAE) superior to the best MAE reported for previously published very simply explicitly invertible approximations of the standard normal CDF. The best MAE reported from this study is 2.73e–05, which is nearly a factor of five better than the best MAE reported for other published very simply explicitly invertible approximations.

| [1] |
S. K. Tanamas, R. L. Hanson, R. G. Nelson, W. C. Knowler, Effect of different methods of accounting for antihypertensive treatment when assessing the relationship between diabetes or obesity and systolic blood pressure, J. Diabetes Complicat., 31 (2017), 693–699. https://doi.org/10.1016/j.jdiacomp.2016.12.013 doi: 10.1016/j.jdiacomp.2016.12.013

|
| [2] |
I. G. Gachev, M. Y. Glyavin, V. N. Manuilov, M. V. Morozkin, N. A. Zavolsky, The Influence of Initial Electron Velocities Distribution on the Energy Spectra of the Spent Electron Beam in Gyrotron, J. Infrared Millim. Te., 31 (2010), 1109–1114. https://doi.org/10.1007/s10762-010-9690-4 doi: 10.1007/s10762-010-9690-4
|
| [3] | C. Conrick, S. Hanson, Normal distribution, probability, and modern financial theory. In: Vertical Option Spreads, USA: John Wiley and Sons, 2013. |
| [4] | MathWorks Inc, MATLAB's Global Optimization Toolbox (Software), 2020. Available from: https://www.mathworks.com/products/global-optimization.html. |
| [5] |
A. Soranzo, E. Epure, Very simply explicitly invertible approximations of normal cumulative and normal quantile function, Applied Mathematical Sciences, 8 (2014), 4323–4341. https://doi.org/10.12988/ams.2014.45338 doi: 10.12988/ams.2014.45338
|
| [6] |
S. M. Papalexiou, Unified theory for stochastic modelling of hydroclimatic processes: Preserving marginal distributions, correlation structures, and intermittency. Adv. Water Resour., 115 (2018), 234–252. https://doi.org/10.1016/j.advwatres.2018.02.013 doi: 10.1016/j.advwatres.2018.02.013
|
| [7] | The Optimization Firm, BARON v20.4.14 (Software), 2020. Available from: https://minlp.com/baron. |
| [8] | G. Pólya, Remarks on computing the probability integral in one and two dimensions, Proceedings of the First Berkeley Symposium on Mathematical Statistics and Probability, (1949), 63–78. |
| [9] |
J. H. Cadwell, The bivariate normal integral, Biometrika, 38 (1951), 475–479. https://doi.org/10.1093/biomet/38.3-4.475 doi: 10.1093/biomet/38.3-4.475
|
| [10] |
R. G. Hart, A formula for the approximation of definite integrals of the normal distribution function, Mathematical Tables and Other Aids to Computation, 11 (1957), 265–265. https://doi.org/10.1090/S0025-5718-57-99288-8 doi: 10.1090/S0025-5718-57-99288-8
|
| [11] | K. D. Tocher, The art of simulation, London: English University Press LTD., 1963. |
| [12] | M. Abramowitz, I. A. Stegun, Handbook of mathematical functions with formulas, graphs, and mathematical tables, New York: Dover, 1964. |
| [13] |
E. Page, Approximations to the cumulative normal function and its inverse for use on a pocket calculator, J. R. Stat. Soc. C-Appl., 26 (1977), 75–76. https://doi.org/10.2307/2346872 doi: 10.2307/2346872
|
| [14] |
S. E. Derenzo, Approximations for hand calculators using small integer coefficients, Math Comp., 31 (1977), 214–222. https://doi.org/10.1090/S0025-5718-1977-0423761-X doi: 10.1090/S0025-5718-1977-0423761-X
|
| [15] |
H. C. Hamaker, Approximating the cumulative normal distribution and its inverse, J. R. Stat. Soc. C-Appl., 27 (1978), 76–77. https://doi.org/10.2307/2346231 doi: 10.2307/2346231
|
| [16] |
A. G. Hawkes, Approximating the normal tail, J. Roy. Stat. Soc. D-Sta., 33 (1982), 231–236. https://doi.org/10.2307/2987989 doi: 10.2307/2987989
|
| [17] |
J. T. Lin, Approximating the normal tail probability and its inverse for use on a pocket calculator, J. R. Stat. Soc. C-Appl., 28 (1989), 69–70. https://doi.org/10.2307/2347681 doi: 10.2307/2347681
|
| [18] |
J. D. Vedder, An invertible approximation to the normal distribution function, Comput. Stat. Data An., 16 (1993), 119–123. https://doi.org/10.1016/0167-9473(93)90248-R doi: 10.1016/0167-9473(93)90248-R
|
| [19] |
R. J. Bagby, Calculating normal probabilities, The American Mathematical Monthly, 102 (1995), 46–49. https://doi.org/10.1080/00029890.1995.11990532 doi: 10.1080/00029890.1995.11990532
|
| [20] |
G. R. Waissi, D. F. Rossin, A sigmoid approximation of the standard normal integral, Appl. Math. Comput., 77 (1996), 91–95. https://doi.org/10.1016/0096-3003(95)00190-5 doi: 10.1016/0096-3003(95)00190-5
|
| [21] |
W. Bryc, A uniform approximation to the right normal tail integral, Appl. Math. Comput., 127 (2002), 365–374. https://doi.org/10.1016/S0096-3003(01)00015-7 doi: 10.1016/S0096-3003(01)00015-7
|
| [22] |
H. Shore, Accurate RMM-based approximations for the CDF of the normal distribution, Commun. Stat.—Theor. M., 34 (2005), 507–513. https://doi.org/10.1081/STA-200052102 doi: 10.1081/STA-200052102
|
| [23] |
D. Kundu, A. Manglick, A convenient way Of generating normal random variables using generalized exponential distribution, J. Mod. Appl. Stat. Meth., 5 (2006), 22. https://doi.org/10.22237/jmasm/1146457260 doi: 10.22237/jmasm/1146457260
|
| [24] | K. M. Aludaat, M. T. Alodat, A note on approximating the normal distribution function, Applied Mathematical Sciences, 2 (2008), 425–429. |
| [25] |
S. R. Bowling, M. T. Khasawneh, S. Kaewkuekool, B. R. Cho, A logistic approximation to the cumulative normal distribution, J. Ind. Eng. Manag., 2 (2009), 114–127. https://doi.org/10.3926/jiem.2009.v2n1.p114-127 doi: 10.3926/jiem.2009.v2n1.p114-127
|
| [26] |
H. Vazquez-Leal, R. Castaneda-Sheissa, U. Filobello-Nino, A. Sarmiento-Reyes, J. Sanchez Orea, High accurate simple approximation of normal distribution integral, Math. Probl. Eng., (2012). https://doi.org/10.1155/2012/124029 doi: 10.1155/2012/124029
|
| [27] |
M. Abderrahmane, B. Kamel, Two news approximations to standard normal distribution function, Journal of Applied & Computational Mathematics, 5 (2016), 328. https://doi.org/10.4172/2168-9679.1000328 doi: 10.4172/2168-9679.1000328
|
| [28] |
O. Eidous, S. Al-Salman, One-term approximation for normal distribution function, Mathematics and Statistics, 4 (2016), 15–18. https://doi.org/10.13189/ms.2016.040102 doi: 10.13189/ms.2016.040102
|
| [29] |
I. Matic, R. Radoicic, D. Stefanica, A sharp Pólya-based approximation to the normal CDF, Appl. Math. Comput., 322 (2018), 111–122. https://doi.org/10.1016/j.amc.2017.10.019 doi: 10.1016/j.amc.2017.10.019
|
| [30] |
O. M. Eidous, R. Abu-Shareefa, New approximations for standard normal distribution function, Commun. Stat.—Theor. M., 49 (2020), 1357–1374. https://doi.org/10.1080/03610926.2018.1563166 doi: 10.1080/03610926.2018.1563166
|
| [31] |
V. K. Shchigolev, On HPM approximations for the cumulative normal distribution function, Universal Journal of Computational Mathematics, 7 (2019), 8–13. https://doi.org/10.13189/ujcmj.2019.070102 doi: 10.13189/ujcmj.2019.070102
|
| [32] |
Z. Ugray, L. Lasdon, J. Plummer, F. Glover, J. Kelly, R. Martí, Scatter Search and Local NLP Solvers: A Multistart Framework for Global Optimization, INFORMS J. Comput., 19 (2007), 328–340. https://doi.org/10.1287/ijoc.1060.0175 doi: 10.1287/ijoc.1060.0175
|
| [33] |
H. S. Ryoo, N. V. Sahinidis, A branch-and-reduce approach to global optimization, J. Global Optim., 8 (1996), 107–138. https://doi.org/10.1007/BF00138689 doi: 10.1007/BF00138689
|
| [34] | S. Razavi, VARS v2.1 (Software), 2020. Available from: https://vars-tool.com/. |
| [35] |
S. M. Papalexiou, F. Serinaldi, E. Porcu, Advancing Space-Time Simulation of Random Fields: From Storms to Cyclones and Beyond, Water Resour. Res., 57 (2021), e2020WR029466. https://doi.org/10.1029/2020WR029466 doi: 10.1029/2020WR029466
|
| [36] |
H. O. Lancaster, The Structure of Bivariate Distribution, The Annals of Mathematical Statistics, 29 (1958), 719–736. https://doi.org/10.1214/aoms/1177706532 doi: 10.1214/aoms/1177706532
|
Figures(2) / Tables(4)

Jessica Lipoth, Yoseph Tereda, Simon Michael Papalexiou, Raymond J. Spiteri. A new very simply explicitly invertible approximation for the standard normal cumulative distribution function[J]. AIMS Mathematics, 2022, 7(7): 11635-11646. doi: 10.3934/math.2022648







 DownLoad:
DownLoad: