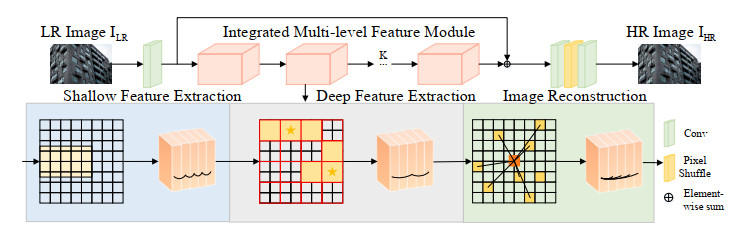
In recent years, significant progress has been made in single-image super-resolution with the advancements of deep convolutional neural networks (CNNs) and transformer-based architectures. These two techniques have led the way in the field of super-resolution technology research. However, performance improvements often come at the cost of a substantial increase in the number of parameters, thereby limiting the practical applications of super-resolution methods. Existing lightweight super-resolution methods, which primarily focus on single-scale feature extraction, lead to the issue of missing multi-scale features. This results in incomplete feature acquisition and poor reconstruction of the image. In response to these challenges, this paper proposed a lightweight multi-scale feature cooperative enhancement network (MFCEN). The network consists of three parts: shallow feature extraction, deep feature extraction, and image reconstruction. In the deep feature extraction part, a novel integrated multi-level feature module was introduced. Compared to existing CNN and transformer hybrid super-resolution networks, MFCEN significantly reduced the number of parameters while maintaining performance. This improvement was particularly evident at a scale factor of 3. The network introduced a novel comprehensive integrated multi-level feature module, leveraging the strong local perceptual capabilities of CNNs and the superior global information processing of transformers. It was designed with depthwise separable convolutions for extracting local information and a block-scale and global feature extraction module based on vision transformers (ViTs). While extracting the three scales of features, a satisfiability attention mechanism with a feed-forward network that can control the information was used to keep the network lightweight. Experiments demonstrated that the proposed model surpasses the reconstruction performance of the 498K-parameter SPAN model with a mere 488K parameters. Extensive experiments on commonly used image super-resolution datasets further validated the effectiveness of the network.
Citation: Jiange Liu, Yu Chen, Xin Dai, Li Cao, Qingwu Li. MFCEN: A lightweight multi-scale feature cooperative enhancement network for single-image super-resolution[J]. Electronic Research Archive, 2024, 32(10): 5783-5803. doi: 10.3934/era.2024267
In recent years, significant progress has been made in single-image super-resolution with the advancements of deep convolutional neural networks (CNNs) and transformer-based architectures. These two techniques have led the way in the field of super-resolution technology research. However, performance improvements often come at the cost of a substantial increase in the number of parameters, thereby limiting the practical applications of super-resolution methods. Existing lightweight super-resolution methods, which primarily focus on single-scale feature extraction, lead to the issue of missing multi-scale features. This results in incomplete feature acquisition and poor reconstruction of the image. In response to these challenges, this paper proposed a lightweight multi-scale feature cooperative enhancement network (MFCEN). The network consists of three parts: shallow feature extraction, deep feature extraction, and image reconstruction. In the deep feature extraction part, a novel integrated multi-level feature module was introduced. Compared to existing CNN and transformer hybrid super-resolution networks, MFCEN significantly reduced the number of parameters while maintaining performance. This improvement was particularly evident at a scale factor of 3. The network introduced a novel comprehensive integrated multi-level feature module, leveraging the strong local perceptual capabilities of CNNs and the superior global information processing of transformers. It was designed with depthwise separable convolutions for extracting local information and a block-scale and global feature extraction module based on vision transformers (ViTs). While extracting the three scales of features, a satisfiability attention mechanism with a feed-forward network that can control the information was used to keep the network lightweight. Experiments demonstrated that the proposed model surpasses the reconstruction performance of the 498K-parameter SPAN model with a mere 488K parameters. Extensive experiments on commonly used image super-resolution datasets further validated the effectiveness of the network.

| [1] | H. Guan, Y. Hu, J. Zeng, C. Zuo, Q. Chen, Super-resolution imaging by synthetic aperture with incoherent illumination, Comput. Imaging VII, 12523 (2023), 100–104. |
| [2] |
H. M. Patel, V. M. Chudasama, K. Prajapati, K. P. Upla, K. Raja, R. Ramachandra, et al., ThermISRnet: An efficient thermal image super-resolution network, Opt. Eng., 60 (2021), 073101. https://doi.org/10.1117/1.OE.60.7.073101 doi: 10.1117/1.OE.60.7.073101

|
| [3] |
D. Qiu, Y. Cheng, X. Wang, Medical image super-resolution reconstruction algorithms based on deep learning: A survey, Comput. Methods Programs Biomed., 238 (2023), 107590. https://doi.org/10.1016/j.cmpb.2023.107590 doi: 10.1016/j.cmpb.2023.107590
|
| [4] |
H. Yang, Z. Wang, X. Liu, C. Li, J. Xin, Z. Wang, Deep learning in medical image super resolution: A review, Appl. Intell., 53 (2023), 20891–20916. https://doi.org/10.1007/s10489-023-04566-9 doi: 10.1007/s10489-023-04566-9
|
| [5] |
C. Wang, J. Jiang, K. Jiang, X. Liu, SPADNet: Structure prior-aware dynamic network for face super-resolution, IEEE Trans. Biom. Behav. Identity Sci., 6 (2024), 326–340. https://doi.org/10.1109/TBIOM.2024.3382870 doi: 10.1109/TBIOM.2024.3382870
|
| [6] |
C. Saharia, J. Ho, W. Chan, T. Salimans, D. J. Fleet, M. Norouzi, Image super-resolution via iterative refinement, IEEE Trans. Pattern Anal. Mach. Intell., 45 (2022), 4713–4726. https://doi.org/10.1109/TPAMI.2022.3204461 doi: 10.1109/TPAMI.2022.3204461
|
| [7] | G. Bhat, M. Danelljan, L. Van Gool, R. Timofte, Deep burst super-resolution, in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2021), 9205–9214. https://doi.org/10.1109/CVPR46437.2021.00909 |
| [8] | A. Lugmayr, M. Danelljan, L. Van Gool, R. Timofte, Srflow: Learning the super-resolution space with normalizing flow, in Computer Vision – ECCV 2020, Springer, (2020), 715–732. https://doi.org/10.1007/978-3-030-58558-7_42 |
| [9] | K. Zhang, L. Van Gool, R. Timofte, Deep unfolding network for image super-resolution, in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2020), 3214–3223. https://doi.org/10.1109/CVPR42600.2020.00328 |
| [10] | X. Kong, H. Zhao, Y. Qiao, C. Dong, Classsr: A general framework to accelerate super-resolution networks by data characteristic, in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2021), 12011–12020. https://doi.org/10.1109/CVPR46437.2021.01184 |
| [11] | X. Wang, L. Xie, C. Dong, Y. Shan, Real-ESRGAN: Training real-world blind super-resolution with pure synthetic data, in 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), IEEE, (2021), 1905–1914. https://doi.org/10.1109/ICCVW54120.2021.00217 |
| [12] | Y. Guo, J. Chen, J. Wang, Q. Chen, J. Cao, Z. Deng, et al., Closed-loop matters: Dual regression networks for single image super-resolution, in 020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2020), 5406–5415. https://doi.org/10.1109/CVPR42600.2020.00545 |
| [13] | Z. Yue, J. Wang, C. C. Loy, Resshift: Efficient diffusion model for image super-resolution by residual shifting, in Advances in Neural Information Processing Systems, Curran Associates, Inc., 36 (2024), 13294–13307. |
| [14] | L. Sun, J. Dong, J. Tang, J. Pan, Spatially-adaptive feature modulation for efficient image super-resolution, in 2023 IEEE/CVF International Conference on Computer Vision (ICCV), IEEE, (2023), 13144–13153. https://doi.org/10.1109/ICCV51070.2023.01213 |
| [15] | Z. Du, D. Liu, J. Liu, J. Tang, G. Wu, L. Fu, Fast and memory-efficient network towards efficient image super-resolution, in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), IEEE, (2022), 852–861. https://doi.org/10.1109/CVPRW56347.2022.00101 |
| [16] |
J. L. Harris, Diffraction and resolving power, J. Opt. Soc. Am., 54 (1964), 931–936. https://doi.org/10.1364/JOSA.54.000931 doi: 10.1364/JOSA.54.000931
|
| [17] |
D. C. Lepcha, B. Goyal, A. Dogra, V. Goyal, Image super-resolution: A comprehensive review, recent trends, challenges and applications, Inf. Fusion, 91 (2023), 230–260. https://doi.org/10.1016/j.inffus.2022.10.007 doi: 10.1016/j.inffus.2022.10.007
|
| [18] |
C. Dong, C. C. Loy, K He, X. Tang, Image super-resolution using deep convolutional networks, IEEE Trans. Pattern Anal. Mach. Intell., 38 (2015), 295–307. https://doi.org/10.1109/TPAMI.2015.2439281 doi: 10.1109/TPAMI.2015.2439281
|
| [19] | C. Dong, C. C. Loy, X. Tang, Accelerating the super-resolution convolutional neural network, in Computer Vision – ECCV 2016, Springer, (2016), 391–407. https://doi.org/10.1007/978-3-319-46475-6_25 |
| [20] | W. Shi, J. Caballero, F. Huszár, J. Totz, A. P. Aitken, R. Bishop, et al., Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network, in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2016), 1874–1883. https://doi.org/10.1109/CVPR.2016.207 |
| [21] | J. Kim, J. K. Lee, K. M. Lee, Accurate image super-resolution using very deep convolutional networks, in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2016), 1646–1654. https://doi.org/10.1109/CVPR.2016.182 |
| [22] | L. Zhang, X. Li, D. He, F. Li, Y. Wang, Z. Zhang, RRSR: Reciprocal reference-based image super-resolution with progressive feature alignment and selection, in Computer Vision – ECCV 2022, Springer, (2022), 648–664. https://doi.org/10.1007/978-3-031-19800-7_38 |
| [23] | Y. Yang, W. Ran, H. Lu, Rddan: A residual dense dilated aggregated network for single image deraining, in 2020 IEEE International Conference on Multimedia and Expo (ICME), IEEE, (2020), 1–6. https://doi.org/10.1109/ICME46284.2020.9102945 |
| [24] | Y. Mei, Y. Fan, Y. Zhou, Image Super-Resolution with Non-Local Sparse Attention, in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2021), 3516–3525. https://doi.org/10.1109/CVPR46437.2021.00352 |
| [25] | Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, et al., Swin transformer: Hierarchical vision transformer using shifted windows, in 2021 IEEE/CVF International Conference on Computer Vision (ICCV), IEEE, (2021), 9992–10002. https://doi.org/10.1109/ICCV48922.2021.00986 |
| [26] | X. Zhu, W. Su, L. Lu, B. Li, X. Wang, J. Dai, Deformable DETR: Deformable transformers for end-to-end object detection, preprint, arXiv: 2010.04159. |
| [27] | X. Zhu, H. Hu, S. Lin, J. Dai, Deformable ConvNets V2: More deformable, better results, in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2019), 9300–9308. https://doi.org/10.1109/CVPR.2019.00953 |
| [28] | S. Zheng, J. Lu, H. Zhao, X. Zhu, Z. Luo, Y. Wang, et al., Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers, in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2021), 6877–6886. https://doi.org/10.1109/CVPR46437.2021.00681 |
| [29] | M. Zheng, P. Gao, R. Zhang, K. Li, X. Wang, H. Li, et al., End-to-end object detection with adaptive clustering transformer, preprint, arXiv: 2011.09315. |
| [30] | H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles, H. Jegou, Training data-efficient image transformers & distillation through attention, in Proceedings of the 38th International Conference on Machine Learning, PMLR, (2021), 10347–10357. |
| [31] | P. Zhang, X. Dai, J. Yang, B. Xiao, L. Yuan, L. Zhang, et al., Multi-scale vision longformer: A new vision transformer for high-resolution image encoding, in 2021 IEEE/CVF International Conference on Computer Vision (ICCV), IEEE, (2021), 2978–2988. https://doi.org/10.1109/ICCV48922.2021.00299 |
| [32] | J. Fang, H. Lin, X. Chen, K. Zeng, A hybrid network of cnn and transformer for lightweight image super-resolution, in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), IEEE, (2022), 1102–1111. https://doi.org/10.1109/CVPRW56347.2022.00119 |
| [33] | G. Gao, Z. Wang, J. Li, W. Li, Y. Yu, T. Zeng, Lightweight bimodal network for single-image super-resolution via symmetric CNN and recursive transformer, preprint, arXiv: 2204.13286. |
| [34] | W. S. Lai, J. B. Huang, N. Ahuja, M. H. Yang, Deep laplacian pyramid networks for fast and accurate super-resolution, in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2017), 5835–5843. https://doi.org/10.1109/CVPR.2017.618 |
| [35] | B. Lim, S. Son, H. Kim, S. Nah, K. M. Lee, Enhanced deep residual networks for single image super-resolution, in 2017 IEEE Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), IEEE, (2017), 1132–1140. https://doi.org/10.1109/CVPRW.2017.151 |
| [36] | Y. Zhang, K. Li, K. Li, L. Wang, B. Zhong, Y. Fu, Image super-resolution using very deep residual channel attention networks, in Computer Vision – ECCV 2018, Springer, (2018), 294–310. https://doi.org/10.1007/978-3-030-01234-2_18 |
| [37] | J. Kim, J. K. Lee, K. M. Lee, Deeply-recursive convolutional network for image super-resolution, in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2016), 1637–1645. https://doi.org/10.1109/CVPR.2016.181 |
| [38] | J. Li, F. Fang, K. Mei, G. Zhang, Multi-scale residual network for image super-resolution, in Computer Vision – ECCV 2018, Springer, (2018), 527–542. https://doi.org/10.1007/978-3-030-01237-3_32 |
| [39] | F. Zhu, Q. Zhao, Efficient single image super-resolution via hybrid residual feature learning with compact back-projection network, in 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), IEEE, (2019), 2453–2460. https://doi.org/10.1109/ICCVW.2019.00300 |
| [40] | F. Kong, M. Li, S. Liu, D. Liu, J. He, Y. Bai, et al., Residual local feature network for efficient super-resolution, in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), IEEE, (2022), 765–775. https://doi.org/10.1109/CVPRW56347.2022.00092 |
| [41] | J. Yang, S. Shen, H. Yue, K. Li, Implicit transformer network for screen content image continuous super-resolution, in Advances in Neural Information Processing Systems, Curran Associates, Inc., 34 (2021), 13304–13315. |
| [42] | J. Li, S. Zhu, Channel-spatial transformer for efficient image super-resolution, in ICASSP 2024 - 2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, (2024), 2685–2689. https://doi.org/10.1109/ICASSP48485.2024.10446047 |
| [43] | J. Liang, J. Cao, G. Sun, K. Zhang, L. Van Gool, R. Timofte, SwinIR: Image restoration using swin transformer in 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), IEEE, (2021), 1833–1844. https://doi.org/10.1109/ICCVW54120.2021.00210 |
| [44] | Z. Lu, J. Li, H. Liu, C. Huang, L. Zhang, T. Zeng, Transformer for single image super-resolution, in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), IEEE, (2022), 456–465. https://doi.org/10.1109/CVPRW56347.2022.00061 |
| [45] |
X. Deng, Y. Zhang, M. Xu, S. Gu, Y. Duan, Deep coupled feedback network for joint exposure fusion and image super-resolution, IEEE Trans. Image Process., 30 (2021), 3098–3112. https://doi.org/10.1109/TIP.2021.3058764 doi: 10.1109/TIP.2021.3058764
|
| [46] |
J. Wang, K. Sun, T. Cheng, B. Jiang, C. Deng, Y. Zhao, et al., Deep high-resolution representation learning for visual recognition, IEEE Trans. Pattern Anal. Mach. Intell., 43 (2021), 3349–3364. https://doi.org/10.1109/TPAMI.2020.2983686 doi: 10.1109/TPAMI.2020.2983686
|
| [47] | L. Wang, X. Dong, Y. Wang, X. Ying, Z. Lin, W. An, et al., Exploring sparsity in image super-resolution for efficient inference, in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2021), 4915–4924. https://doi.org/10.1109/CVPR46437.2021.00488 |
| [48] | X. Li, J. Dong, J. Tang, J. Pan, DLGSANet: Lightweight dynamic local and global self-attention networks for image super-resolution, in 2023 IEEE/CVF International Conference on Computer Vision (ICCV), IEEE, (2023), 12746–12755. https://doi.org/10.1109/ICCV51070.2023.01175 |
| [49] | W. Deng, H. Yuan, L. Deng, Z. Lu, Reparameterized residual feature network for lightweight image super-resolution, in 2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), IEEE, (2023), 1712–1721. https://doi.org/10.1109/CVPRW59228.2023.00172 |
| [50] | X. Zhang, H. Zeng, S. Guo, L. Zhang, Efficient long-range attention network for image super-resolution, in Computer Vision – ECCV 2022, Springer, (2022), 649–667. https://doi.org/10.1007/978-3-031-19790-1_39 |
| [51] | A. G. Howard, M. Zhu, B. Chen, D. Kalenichenko, W. Wang, T. Weyand, et al., Mobilenets: Efficient convolutional neural networks for mobile vision applications, preprint, arXiv: 1704.04861. |
| [52] | R. Timofte, S. Gu, J. Wu, L. Van Gool, L. Zhang, M. H. Yang, et al., Ntire 2018 challenge on single image super-resolution: Methods and results, in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), (2018), 965–96511. https://doi.org/10.1109/CVPRW.2018.00130 |
| [53] | M. Bevilacqua, A. Roumy, C. Guillemot, M. L. Alberi-Morel, Low-complexity single-image super-resolution based on nonnegative neighbor embedding, in Proceedings of the 23rd British Machine Vision Conference (BMVC), BMVA Press, (2012), 1–10. |
| [54] | R. Zeyde, M. Elad, M. Protter, On single image scale-up using sparse-representations, in Curves and Surfaces. Curves and Surfaces 2010, Springer, (2012), 711–730. https://doi.org/10.1007/978-3-642-27413-8_47 |
| [55] | D. Martin, C. Fowlkes, D. Tal, J. Malik, A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics, in Proceedings Eighth IEEE International Conference on Computer Vision (ICCV), IEEE, (2001), 416–423. http://doi.org/10.1109/ICCV.2001.937655 |
| [56] | J. B. Huang, A. Singh, N. Ahuja, Single image super-resolution from transformed self-exemplars, in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, (2015), 5197–5206. http://doi.org/10.1109/CVPR.2015.7299156 |
| [57] |
Y. Matsui, K. Ito, Y. Aramaki, A. Fujimoto, T. Ogawa, T. Yamasaki, et al., Sketch-based manga retrieval using manga109 dataset, Multimedia Tools Appl., 76 (2017), 21811–21838. https://doi.org/10.1007/s11042-016-4020-z doi: 10.1007/s11042-016-4020-z
|
| [58] | Y. Zhang, Y. Tian, Y. Kong, B. Zhong, Y. Fu, Residual dense network for image super-resolution, in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), (2018), 2472–2481. |
| [59] | Y. Zhang, D. Wei, C. Qin, H. Wang, H. Pfister, Y. Fu, Context reasoning attention network for image super-resolution, in 2021 IEEE/CVF International Conference on Computer Vision (ICCV), IEEE, (2021), 4278–4287. https://doi.org/10.1109/ICCV48922.2021.00424 |
| [60] | K. Zhang, W. Zuo, L. Zhang, Learning a single convolutional super-resolution network for multiple degradations, in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, IEEE, (2018), 3262–3271. https://doi.org/10.1109/CVPR.2018.00344 |
| [61] | Z. Hui, X. Gao, Y. Yang, X. Wang, Lightweight image super-resolution with information multi-distillation network, in Proceedings of the 27th ACM International Conference on Multimedia, Association for Computing Machinery, (2019), 2024–2032. https://doi.org/10.1145/3343031.3351084 |
| [62] | H. Zhao, X. Kong, J. He, Y. Qiao, C. Dong, Efficient image super-resolution using pixel attention, in Computer Vision – ECCV 2020 Workshops, Springer, (2020), 56–72. https://doi.org/10.1007/978-3-030-67070-2_3 |
| [63] | J. Liu, J. Tang, G. Wu, Residual feature distillation network for lightweight image super-resolution, in Computer Vision – ECCV 2020 Workshops, Springer, (2020), 41–55. https://doi.org/10.1007/978-3-030-67070-2_2 |
| [64] |
J. H. Kim, J. H. Choi, M. Cheon, J. S. Lee, MAMNet: Multi-path adaptive modulation network for image super-resolution, Neurocomputing, 402 (2020), 38–49. https://doi.org/10.1016/j.neucom.2020.03.069 doi: 10.1016/j.neucom.2020.03.069
|
| [65] | L. Sun, J. Pan, J. Tang, Shufflemixer: An efficient convnet for image super-resolution, in Advances in Neural Information Processing Systems, Curran Associates, Inc., 35 (2022), 17314–17326. |
| [66] | J. Hu, L. Shen, G. Sun, Squeeze-and-excitation networks, in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (CVPR), (2018), 7132–7141. |
| [67] | C. Wan, H. Yu, Z. Li, Y. Chen, Y. Zou, Y. Liu, et al., Swift parameter-free attention network for efficient super-resolution, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2024), 6246–6256. |
| [68] | X. Zhang, Y. Zhang, F. Yu, HiT-SR: Hierarchical transformer for efficient image super-resolution, preprint, arXiv: 2407.05878. |




Figures(5) / Tables(2)
Jiange Liu, Yu Chen, Xin Dai, Li Cao, Qingwu Li. MFCEN: A lightweight multi-scale feature cooperative enhancement network for single-image super-resolution[J]. Electronic Research Archive, 2024, 32(10): 5783-5803. doi: 10.3934/era.2024267







 DownLoad:
DownLoad: