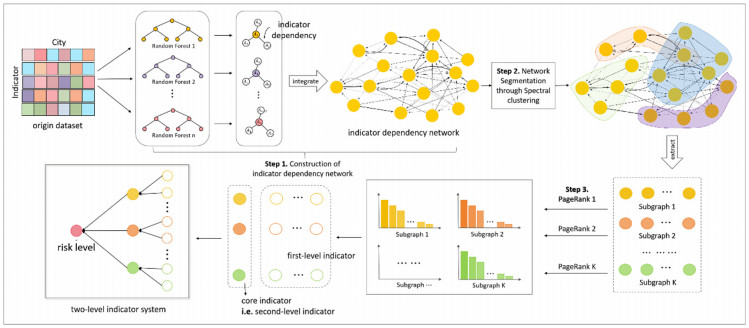
The rapid development of urban informatization has led to a deep integration of advanced information technology into urban life. Many decision-makers are starting to alleviate the adverse effects of this informatization process through risk assessment. However, existing methods cannot effectively analyze internal and hierarchical relationships because of the excessive number of indicators. Thus, it is necessary to construct an indicator's dependency graph and conduct a comprehensive hierarchical analysis to solve this problem. In this study, we proposed a graph-based two-level indicator system construction method. First, a random forest was used to extract the indicators' dependency graph from missing data. Then, spectral clustering was used to separate the graph and form a functional subgraph. Finally, PageRank was used to calculate the prioritization for each subgraph's indicator, and the two-level indicator system was established. To verify the performance, we took China's 25 smart cities as examples. For the simulation of risk level prediction, we compared our method with some machine learning algorithms, such as ridge regression, Lasso regression, support vector regression, decision trees, and multi-layer perceptron. Results showed that the two-level indicator system is superior to the general indicator system for risk assessment.
Citation: Li Yang, Kai Zou, Yuxuan Zou. Graph-based two-level indicator system construction method for smart city information security risk assessment[J]. Electronic Research Archive, 2024, 32(8): 5139-5156. doi: 10.3934/era.2024237
The rapid development of urban informatization has led to a deep integration of advanced information technology into urban life. Many decision-makers are starting to alleviate the adverse effects of this informatization process through risk assessment. However, existing methods cannot effectively analyze internal and hierarchical relationships because of the excessive number of indicators. Thus, it is necessary to construct an indicator's dependency graph and conduct a comprehensive hierarchical analysis to solve this problem. In this study, we proposed a graph-based two-level indicator system construction method. First, a random forest was used to extract the indicators' dependency graph from missing data. Then, spectral clustering was used to separate the graph and form a functional subgraph. Finally, PageRank was used to calculate the prioritization for each subgraph's indicator, and the two-level indicator system was established. To verify the performance, we took China's 25 smart cities as examples. For the simulation of risk level prediction, we compared our method with some machine learning algorithms, such as ridge regression, Lasso regression, support vector regression, decision trees, and multi-layer perceptron. Results showed that the two-level indicator system is superior to the general indicator system for risk assessment.

| [1] |
A. J. Bokolo, Data driven approaches for smart city planning and design: a case scenario on urban data management, Digital Policy Regul. Governance, 25 (2023), 351–367. https://doi.org/10.1108/dprg-03-2022-0023 doi: 10.1108/dprg-03-2022-0023

|
| [2] |
A. A. Semlambo, D. M. Mfoi, Y. Sangula, Information systems security threats and vulnerabilities: A case of the Institute of Accountancy Arusha (IAA), J. Comput. Commun., 10 (2022), 29–43. https://doi.org/10.4236/jcc.2022.1011003. doi: 10.4236/jcc.2022.1011003
|
| [3] | J. Andress, Foundations of Information Security: A Straightforward Introduction, No Starch Press, San Francisco, 2019. |
| [4] |
A. Chiniah, F. Ghannoo, A multi-theory model to evaluate new factors influencing information security compliance, Int. J. Secur. Networks, 18 (2023), 19–29. https://doi.org/10.1504/IJSN.2023.129949 doi: 10.1504/IJSN.2023.129949
|
| [5] | T. Finne, A conceptual framework for information security management, Comput. Secur., 17 (1998), 303–307. |
| [6] | A. Herzog, N. Shahmehri, Towards secure e-services: Risk analysis of a home automation service, in 6th Nordic Workshop on Secure IT-Systems, (2001), 18–26. |
| [7] | H. Zhu, S. Liu, Y. Qu, X. Han, W. He, Y. Cao, A new risk assessment method based on belief rule base and fault tree analysis, in Proceedings of the Institution of Mechanical Engineers, 236 (2022), 420–438. https://doi.org/10.1177/1748006X211011457 |
| [8] |
X. Xu, F. Yu, W. Pedrycz, X. Du, Multi-source fuzzy comprehensive evaluation, Appl. Soft Comput., 135 (2023), 110042. https://doi.org/https://doi.org/10.1016/j.asoc.2023.110042 doi: 10.1016/j.asoc.2023.110042
|
| [9] |
H. Liu, Z. Zhang, Z. Sun, A fuzzy comprehensive evaluation model for smart city application, Int. J. Innovative Comput. Appl., 11 (2020), 96–102. https://doi.org/10.1504/ijica.2020.107120 doi: 10.1504/ijica.2020.107120
|
| [10] |
O. T. Arogundade, A. Abayomi-Alli, S. Misra, An ontology-based security risk management model for information systems, Arab. J. Sci. Eng., 45 (2020), 6183–6198. https://doi.org/10.1007/s13369-020-04524-4 doi: 10.1007/s13369-020-04524-4
|
| [11] | H. Taherdoost, A review on risk management in information systems: Risk policy, control and fraud detection, Electronics, 10 (2021), 3065. https://doi.org/10.3390/electronics10243065 |
| [12] |
A. Tantawy, S. Abdelwahed, A. Erradi, K. Shaban, Model-based risk assessment for cyber physical systems security, Comput. Secur., 96 (2020), 101864. https://doi.org/10.1016/j.cose.2020.101864 doi: 10.1016/j.cose.2020.101864
|
| [13] |
K. Tam, K. Jones, MaCRA: A model-based framework for maritime cyber-risk assessment, WMU J. Marit. Aff., 18 (2019), 129–163. https://doi.org/10.1007/s13437-019-00162-2 doi: 10.1007/s13437-019-00162-2
|
| [14] |
Y. Tang, M. Elhoseny, Computer network security evaluation simulation model based on neural network, J. Intell. Fuzzy Syst., 37 (2019), 3197–3204. https://doi.org/10.3233/jifs-179121 doi: 10.3233/jifs-179121
|
| [15] |
W. Cai, H. Yao, Research on information security risk assessment method based on fuzzy rule set, Wireless Commun. Mobile Comput., 2021 (2021). https://doi.org/10.1155/2021/9663520 doi: 10.1155/2021/9663520
|
| [16] | K. Dixit, U. Singh, B. Pandya, Comparative framework for information security risk assessment model, in Proceedings of the International Conference on Innovative Computing & Communication (ICICC) 2022, (2022). http://doi.org/10.2139/ssrn.4121814 |
| [17] | R. Wirtz, M. Heisel, Model-based risk analysis and evaluation using CORAS and CVSS, in International Conference on Evaluation of Novel Approaches to Software Engineering, 1172 (2020), 108–134. https://doi.org/10.1007/978-3-030-40223-5_6 |
| [18] |
A. S. Alfakeeh, A. Almalawi, F. J. Alsolami, Y. B. Abushark, A. I. Khan, A. A. S. Bahaddad, et al., Hesitant fuzzy-sets based decision-making model for security risk assessment, Comput. Mater. Continua, 70 (2022), 2297–2317. https://doi.org/10.32604/cmc.2022.020146 doi: 10.32604/cmc.2022.020146
|
| [19] |
R. Kaur, D. Gabrijelčič, T. Klobučar, Artificial intelligence for cybersecurity: Literature review and future research directions, Inform. Fusion, 97 (2023), 101804. https://doi.org/10.1016/j.inffus.2023.101804 doi: 10.1016/j.inffus.2023.101804
|
| [20] |
J. Song, H. Xu, Safety risk evaluation of tourism management system based on PSO-BP neural network, Wireless Commun. Mobile Comput., 2023 (2023). https://doi.org/10.1155/2023/2968129 doi: 10.1155/2023/2968129
|
| [21] |
Z. Sun, G. Wang, P. Li, H. Wang, M. Zhang, X. Liang, An improved random forest based on the classification accuracy and correlation measurement of decision trees, Expert Syst. Appl., 237 (2024), 121549. https://doi.org/10.1016/j.eswa.2023.121549 doi: 10.1016/j.eswa.2023.121549
|
| [22] |
G. Zhong, C. Pun, Self-taught multi-view spectral clustering, Pattern Recognit., 138 (2023), 109349. https://doi.org/10.1016/j.patcog.2023.109349 doi: 10.1016/j.patcog.2023.109349
|
| [23] |
T. Chapuis-Chkaiban, Z. Toffano, B. Valiron, On new PageRank computation methods using quantum computing, Quantum Inf. Process., 22 (2023), 138. https://doi.org/10.1007/s11128-023-03856-y doi: 10.1007/s11128-023-03856-y
|






Figures(7) / Tables(2)
Li Yang, Kai Zou, Yuxuan Zou. Graph-based two-level indicator system construction method for smart city information security risk assessment[J]. Electronic Research Archive, 2024, 32(8): 5139-5156. doi: 10.3934/era.2024237







 DownLoad:
DownLoad: