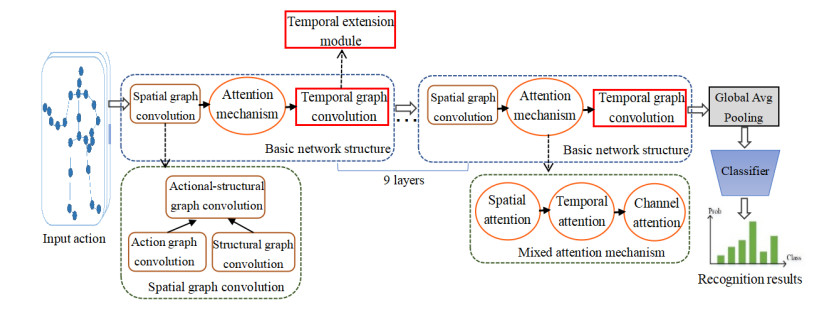
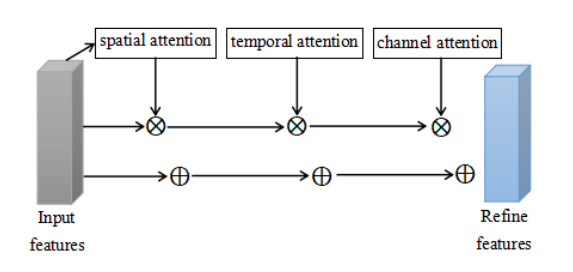
Human behavior recognition has always been a hot spot for research in computer vision. In this paper, we propose a novel video behavior recognition method based on Actional-Structural Graph Convolution and a Temporal Extension Module under the framework of a Spatio-Temporal Graph Convolution Neural Network, which can optimize the spatial and temporal features simultaneously. The basic network framework of our method consists of three parts: spatial graph convolution module, temporal extension module and attention mechanism module. In the spatial dimension, the action graph convolution is utilized to obtain abundant spatial features by capturing the correlations of distant joint features, and the structural graph convolution expands the existing skeleton graph to acquire the spatial features of adjacent joints. In the time dimension, the sampling range of the temporal graph is expanded for extracting the same and adjacent joints of adjacent frames. Furthermore, attention mechanisms are introduced to improve the performance of our method. In order to verify the effectiveness and accuracy of our method, a large number of experiments were carried out on two standard behavior recognition datasets: NTU-RGB+D and Kinetics. Comparative experiment results show that our proposed method can achieve better performance.
Citation: Hui Xu, Jun Kong, Mengyao Liang, Hui Sun, Miao Qi. Video behavior recognition based on actional-structural graph convolution and temporal extension module[J]. Electronic Research Archive, 2022, 30(11): 4157-4177. doi: 10.3934/era.2022210
Human behavior recognition has always been a hot spot for research in computer vision. In this paper, we propose a novel video behavior recognition method based on Actional-Structural Graph Convolution and a Temporal Extension Module under the framework of a Spatio-Temporal Graph Convolution Neural Network, which can optimize the spatial and temporal features simultaneously. The basic network framework of our method consists of three parts: spatial graph convolution module, temporal extension module and attention mechanism module. In the spatial dimension, the action graph convolution is utilized to obtain abundant spatial features by capturing the correlations of distant joint features, and the structural graph convolution expands the existing skeleton graph to acquire the spatial features of adjacent joints. In the time dimension, the sampling range of the temporal graph is expanded for extracting the same and adjacent joints of adjacent frames. Furthermore, attention mechanisms are introduced to improve the performance of our method. In order to verify the effectiveness and accuracy of our method, a large number of experiments were carried out on two standard behavior recognition datasets: NTU-RGB+D and Kinetics. Comparative experiment results show that our proposed method can achieve better performance.

| [1] |
J. K. Aggarwal, M. S. Ryoo, Human activity analysis: A review, ACM Comput. Surv., 43 (2011), 1–43. https://doi.org/10.1145/1922649.1922653 doi: 10.1145/1922649.1922653

|
| [2] | H. Wang, C. Schmid, Action recognition with improved trajectories action recognition with improved trajectories, in 2013 IEEE International Conference on Computer Vision, IEEE, Sydney, NSW, Australia, (2013), 3551–3558. https://doi.org/10.1109/ICCV.2013.441 |
| [3] | Y. H. Ng, M. Hausknecht, S. Vijayanarasimhan, O. Vinyals, R. Monga, G. Toderici, Beyond short snippets: Deep networks for video classification, in 2015 IEEE Conference on Computer Vision and Pattern Recognition, IEEE, (2015), 4694–4702. https://doi.org/10.1109/CVPR.2015.7299101 |
| [4] | Z. Qin, Y. Liu, M. Perera, S. Anwar, T. Gedeon, P. Ji, et al., ANUBIS: Review and benchmark skeleton-based action recognition methods with a new dataset, preprint, arXiv: 2205.02071. |
| [5] | Z. Zhang, Y. Hu, S. Chan, L. T. Chia, Motion context: A new representation for human action recognition, in European Conference on Computer Vision, Academic press, (2008), 817–829. https://doi.org/10.1007/978-3-540-88693-8_60 |
| [6] |
J. C. Niebles, H. Wang, F. F. Li, Unsupervised learning of human action categories using spatial-temporal words, Int. J. Comput. Vision, 79 (2008), 299–318. https://doi.org/10.1007/s11263-007-0122-4 doi: 10.1007/s11263-007-0122-4
|
| [7] |
H. Wang, A. Klser, C. Schmid, C. L. Liu, Dense trajectories and motion boundary descriptors for action recognition, Int. J. Comput. Vision, 103 (2013), 60–79. https://doi.org/10.1007/s11263-012-0594-8 doi: 10.1007/s11263-012-0594-8
|
| [8] | R. Vemulapalli, F. Arrate, R. Chellappa, Human action recognition by representing 3D skeletons as points in a lie group, in 2014 IEEE Conference on Computer Vision and Pattern Recognition, IEEE, Columbus, USA, (2014), 588–595. https://doi.org/10.1109/CVPR.2014.82 |
| [9] | M. E. Hussein, M. Torki, M. A. Gowayyed, M. A. El-Saban, Human action recognition using a temporal hierarchy of covariance descriptors on 3D joint locations, in Twenty-third International Joint Conference on Artificial Intelligence, AAAI, Beijing, China, (2013), 2466–2472. |
| [10] |
F. Ofli, R. Chaudhry, G. Kurillo, R. Vidal, R. Bajcsy, Sequence of the most informative joints (smij): A new representation for human skeletal action recognition, J. Visual Commun. Image Represent., 25 (2014), 24–38. https://doi.org/10.1016/j.jvcir.2013.04.007 doi: 10.1016/j.jvcir.2013.04.007
|
| [11] | L. Xia, C. C. Chen, J. K. Aggarwal, View invariant human action recognition using histograms of 3D joints, in 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, IEEE, Providence, USA, (2012), 20–27. https://doi.org/10.1109/CVPRW.2012.6239233 |
| [12] | C. Li, Q. Zhong, D. Xie, S. Pu, Skeleton-based action recognition with convolutional neural networks, in 2017 IEEE International Conference on Multimedia & Expo Workshops, IEEE, Hong Kong, (2017), 597–600. https://doi.org/10.1109/ICMEW.2017.8026285 |
| [13] | C. Li, Q. Zhong, D. Xie, S. Pu, Co-occurrence feature learning from skeleton data for action recognition and detection with hierarchical aggregation, in Proceedings of the 27th International Joint Conference on Artificial Intelligence, AAAI, Stockholm, Sweden, (2018), 786–792. https://doi.org/10.24963/ijcai.2018/109 |
| [14] | C. Caetano, J. Sena, F. Bremond, J. A. Dos Santos, W. R. Schwartz, Skelemotion: A new representation of skeleton joint sequences based on motion information for 3D action recognition, in 2019 16th IEEE International Conference on Advanced Video and Signal Based Surveillance, IEEE, Taipei, Taiwan, (2019), 1–8. https://doi.org/10.1109/AVSS.2019.8909840 |
| [15] | Y. Li, R. Xia, X. Liu, Q. Huang, Learning shape-motion representations from geometric algebra spatio-temporal model for skeleton-based action recognition, in 2019 IEEE International Conference on Multimedia and Expo (ICME), IEEE, Shanghai, China, (2019), 1066–1071. https://doi.org/10.1109/ICME.2019.00187 |
| [16] | M. Li, S. Chen, X. Chen, Y. Zhang, Y. Wang, Q. Tian, Actional-structural graph convolutional networks for skeleton-based action recognition, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, IEEE, Long Beach, USA, (2019), 3595–3603. https://doi.org/10.1109/CVPR.2019.00371 |
| [17] | S. Song, C. Lan, J. Xing, W. Zeng, J. Liu, An end-to-end spatio-temporal attention model for human action recognition from skeleton data, in Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, AAAI, San Francisco, USA, (2016), 4263–4270. https://doi.org/10.1609/aaai.v31i1.11212 |
| [18] | L. Shi, Y. Zhang, J. Cheng, H. Lu, Skeleton-based action recognition with multi-stream adaptive graph convolutional networks, in IEEE Transactions on Image Processing, IEEE, (2020), 9532–9545. https://doi.org/10.1109/TIP.2020.3028207 |
| [19] | T. S. Kim, A. Reiter, Interpretable 3D human action analysis with temporal convolutional networks, in 2017 IEEE Conference on Computer Vision and Pattern Recognition, IEEE, Honolulu, USA, (2017), 1623–1631. https://doi.org/10.1109/CVPRW.2017.207 |
| [20] | Q. Ke, M. Bennamoun, S. An, F. Sohel, F. Boussaid, A new representation of skeleton sequences for 3D action recognition, in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Honolulu, USA, (2017), 4570–4579. https://doi.org/10.1109/CVPR.2017.486 |
| [21] |
M. Liu, L. Hong, C. Chen, Enhanced skeleton visualization for view invariant human action recognition, Pattern Recognit., 68 (2017), 346–362. https://doi.org/10.1016/j.patcog.2017.02.030 doi: 10.1016/j.patcog.2017.02.030
|
| [22] |
B. Li, M. He, Y. Dai, X. Cheng, Y. Chen, 3D skeleton based action recognition by video-domain translation-scale invariant mapping and multi-scale dilated CNN, Multimed. Tools Appl., 77 (2018), 22901–22921. https://doi.org/10.1007/s11042-018-5642-0 doi: 10.1007/s11042-018-5642-0
|
| [23] |
K. Hu, J. Jin, F. Zheng, L. Weng, Y. Ding, Overview of behavior recognition based on deep learning, Artif. Intell. Rev., 2022 (2022), 1–33. https://doi.org/10.1007/s10462-022-10210-8 doi: 10.1007/s10462-022-10210-8
|
| [24] | J. Liu, A. Shahroudy, D. Xu, A. C. Kot, G. Wang, Skeleton-based action recognition using spatio-temporal LSTM network with trust gates, in IEEE Transactions on Pattern Analysis and Machine Intelligence, IEEE, (2017), 3007–3021. https://doi.org/10.1109/TPAMI.2017.2771306 |
| [25] | J. Liu, G. Wang, L. Y. Duan K. Abdiyeva, A. C. Kot, Skeleton-based human action recognition with global context-aware attention LSTM networks, in IEEE Transactions on Image Processing, IEEE, (2018), 1586–1599. https://doi.org/10.1109/TIP.2017.2785279 |
| [26] | L. Wang, Z. Tong, B. Ji, G. Wu, TDN: Temporal difference networks for efficient action recognition, in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Nashville, USA, (2021), 1895–1904. https://doi.org/10.1109/CVPR46437.2021.00193 |
| [27] |
C. Liu, J. Ying, H. Yang, X. Hu, J. Liu, Improved human action recognition approach based on two-stream convolutional neural network model, Vis. Comput., 37 (2021), 1327–1341. https://doi.org/10.1007/s00371-020-01868-8 doi: 10.1007/s00371-020-01868-8
|
| [28] | C. Si, Y. Jing, W. Wang, L. Wang, T. Tan, Skeleton-based action recognition with spatial reasoning and temporal stack learning, in Proceedings of the European Conference on Computer Vision, ECCV, (2018), 103–118. https://doi.org/10.1007/978-3-030-01246-5_7 |
| [29] |
W. Yang, J. Zhang, J. Cai, Z. Xu, Shallow graph convolutional network for skeleton-based action recognition, Sensors, 21 (2021), 452. https://doi.org/10.3390/s21020452 doi: 10.3390/s21020452
|
| [30] | Z. Chen, S. Li, B. Yang, Q. Li, H. Liu, Multi-scale spatial temporal graph convolutional network for skeleton-based action recognition, in Proceedings of the AAAI Conference on Artificial Intelligence, AAAI, (2021), 1113–1122. https://doi.org/10.1609/aaai.v35i2.16197 |
| [31] |
C. Ding, S. Wen, W. Ding, K. Liu, E. Belyaev, Temporal segment graph convolutional networks for skeleton-based action recognition, Eng. Appl. Artif. Intell., 110 (2022), 104675. https://doi.org/10.1016/j.engappai.2022.104675 doi: 10.1016/j.engappai.2022.104675
|
| [32] | L. Shi, Y. Zhang, J. Cheng, H. Lu, Two-stream adaptive graph convolutional networks for skeleton-based action recognition, in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Long Beach, USA (2019), 12018–12027. https://doi.org/10.1109/CVPR.2019.01230 |
| [33] | P. Zhang, C. Lan, W. Zeng, J. Xing, J. Xue, N. Zheng, Semantics-guided neural networks for efficient skeleton-based human action recognition, in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Seattle, USA, (2020), 1112–1121. https://doi.org/10.1109/CVPR42600.2020.00119 |
| [34] | C. Si, W. Chen, W. Wang, L. Wang, T. Tan, An attention enhanced graph convolutional LSTM network for skeleton-based action recognition, in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Long Beach, USA, (2019), 1227–1236. https://doi.org/10.1109/CVPR.2019.00132 |
| [35] | S. Miao, Y. Hou, Z. Gao, M. Xu, W. Li, A central difference graph convolutional operator for skeleton-based action recognition, in IEEE Transactions on Circuits and Systems for Video Technology, IEEE, (2021), 4893–4899. https://doi.org/10.1109/TCSVT.2021.3124562 |
| [36] | Y. Chen, Z. Zhang, C. Yuan, B. Li, Y. Deng, W. Hu, Channel-wise topology refinement graph convolution for skeleton-based action recognition, in 2021 IEEE/CVF International Conference on Computer Vision (ICCV), IEEE, Montreal, Canada, (2021), 13359–13368. https://doi.org/10.1109/ICCV48922.2021.01311 |
| [37] | T. Kipf, E. Fetaya, K. C. Wang, M. Welling, R. Zemel, Neural relational inference for interacting systems, in International Conference on Machine Learning, PMLR, (2018), 2688–2697. |
| [38] | A. Shahroudy, J. Liu, T. T. Ng, G. Wang, NTU RGB+D: A large scale dataset for 3D human activity analysis, in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Las Vegas, USA, (2016), 1010–1019. https://doi.org/10.1109/CVPR.2016.115 |
| [39] | W. Kay, J. Carreira, K. Simonyan, B. Zhang, C. Hillier, S. Vijayanarasimhan, et al., The kinetics human action video dataset, preprint, arXiv: 1705.06950. |
| [40] | Y. Du, W. Wang, L. Wang, Hierarchical recurrent neural network for skeleton based action recognition, in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Boston, USA, (2015), 1110–1118. https://doi.org/10.1109/CVPR.2015.7298714 |
| [41] | H. Liu, J. Tu, M. Liu, Two-stream 3D convolutional neural network for skeleton-based action recognition, preprint, arXiv: 1705.08106. |
| [42] |
H. H. Pham, H. Salmane, L. Khoudour, A. Crouzil, P. Zegers, S. A. Velastin, Spatio temporal image representation of 3D skeletal movements for view-invariant action recognition with deep convolutional neural networks, Sensors, 19 (2019), 1932. https://doi.org/10.3390/s19081932 doi: 10.3390/s19081932
|
| [43] | Z. W. Huang, C. D. Wan, T. Probst, L. Van Gool, Deep learning on lie groups for skeleton-based ation recognition, in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Honolulu, USA, (2017), 1243–1252. https://doi.org/10.1109/CVPR.2017.137 |
| [44] | L. Bo, Y. Dai, X. Cheng, H. Chen, Y. Lin, M. He, Skeleton based action recognition using translation-scale invariant image mapping and multi-scale deep CNN, in 2017 IEEE International Conference on Multimedia & Expo Workshops (ICMEW), IEEE, Hong Kong, (2017), 601–604. https://doi.org/10.1109/ICMEW.2017.8026282. |
| [45] | S. Yan, Y. Xiong, D. Lin, Spatial temporal graph convolutional networks for skeleton-based action recognition, in Thirty-second AAAI Conference on Artificial Intelligence, AAAI, Palo Alto, USA, (2018), 7444–7452. https://doi.org/10.1609/aaai.v32i1.12328 |
| [46] | C. Wu, X. J. Wu, J. Kittler, Spatial residual layer and dense connection block enhanced spatial temporal graph convolutional network for skeleton-based action recognition, in 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), IEEE, Seoul, Korea (South), (2019), 1740–1748. https://doi.org/10.1109/ICCVW.2019.00216 |
| [47] | Y. F. Song, Z. Zhang, C. Shan, L. Wang, Richly activated graph convolutional network for robust skeleton-based action recognition, in IEEE Transactions on Circuits and Systems for Video Technology, IEEE, (2021), 1915–1925. https://doi.org/10.1109/TCSVT.2020.3015051 |
| [48] |
H. Zhang, Y. Hou, P. Wang, Z. Guo, W. Li, Sar-nas: Skeleton-based action recognition via neural architecture searching, J. Visual Commun. Image Represent., 73 (2020), 102942. https://doi.org/10.1016/j.jvcir.2020.102942 doi: 10.1016/j.jvcir.2020.102942
|
| [49] | S. Cho, M. Maqbool, F. Liu, H. Foroosh, Self-attention network for skeletonbased human action recognition, in 2020 IEEE Winter Conference on Applications of Computer Vision (WACV), IEEE, Snowmass, USA, (2020), 624–633. https://doi.org/10.1109/WACV45572.2020.9093639 |
| [50] | C. Li, C. Xie, B. Zhang, J. Han, X. Zhen, J. Chen, Memory attention networks for skeleton-based action recognition, in IEEE Transactions on Neural Networks and Learning Systems, IEEE, (2021), 4800–4814. https://doi.org/10.1109/TNNLS.2021.3061115 |
| [51] | B. Fernando, E Gavves, J Oramas, et al., Modeling video evolution for action recognition, in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), IEEE, Boston, USA, (2015), 5378–5387. https://doi.org/10.1109/CVPR.2015.7299176 |


Figures(9) / Tables(8)
Hui Xu, Jun Kong, Mengyao Liang, Hui Sun, Miao Qi. Video behavior recognition based on actional-structural graph convolution and temporal extension module[J]. Electronic Research Archive, 2022, 30(11): 4157-4177. doi: 10.3934/era.2022210







 DownLoad:
DownLoad: