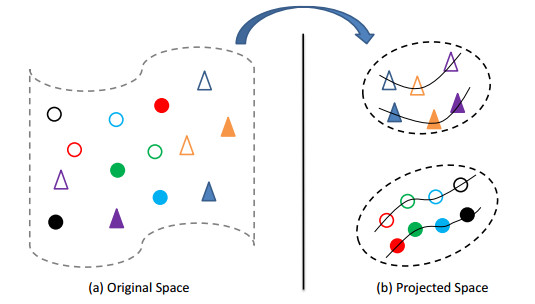
Cross-view data correlation analysis is a typical learning paradigm in machine learning and pattern recognition. To associate data from different views, many approaches to correlation learning have been proposed, among which canonical correlation analysis (CCA) is a representative. When data is associated with label information, CCA can be extended to a supervised version by embedding the supervision information. Although most variants of CCA have achieved good performance, nearly all of their objective functions are nonconvex, implying that their optimal solutions are difficult to obtain. More seriously, the discriminative scatters and manifold structures are not exploited simultaneously. To overcome these shortcomings, in this paper we construct a Discriminative Correlation Learning with Manifold Preservation, DCLMP for short, in which, in addition to the within-view supervision information, discriminative knowledge as well as spatial structural information are exploited to benefit subsequent decision making. To pursue a closed-form solution, we remodel the objective of DCLMP from the Euclidean space to a geodesic space and obtain a convex formulation of DCLMP (C-DCLMP). Finally, we have comprehensively evaluated the proposed methods and demonstrated their superiority on both toy and real datasets.
Citation: Qing Tian, Heng Zhang, Shiyu Xia, Heng Xu, Chuang Ma. Cross-view learning with scatters and manifold exploitation in geodesic space[J]. Electronic Research Archive, 2023, 31(9): 5425-5441. doi: 10.3934/era.2023275
Cross-view data correlation analysis is a typical learning paradigm in machine learning and pattern recognition. To associate data from different views, many approaches to correlation learning have been proposed, among which canonical correlation analysis (CCA) is a representative. When data is associated with label information, CCA can be extended to a supervised version by embedding the supervision information. Although most variants of CCA have achieved good performance, nearly all of their objective functions are nonconvex, implying that their optimal solutions are difficult to obtain. More seriously, the discriminative scatters and manifold structures are not exploited simultaneously. To overcome these shortcomings, in this paper we construct a Discriminative Correlation Learning with Manifold Preservation, DCLMP for short, in which, in addition to the within-view supervision information, discriminative knowledge as well as spatial structural information are exploited to benefit subsequent decision making. To pursue a closed-form solution, we remodel the objective of DCLMP from the Euclidean space to a geodesic space and obtain a convex formulation of DCLMP (C-DCLMP). Finally, we have comprehensively evaluated the proposed methods and demonstrated their superiority on both toy and real datasets.

| [1] |
P. L. Lai, C. Fyfe, Kernel and nonlinear canonical correlation analysis, International Journal of Neural Systems, Int. J. Neural Syst., 10 (2000), 365–377. https://doi.org/10.1142/S012906570000034X doi: 10.1142/S012906570000034X

|
| [2] |
D. R. Hardoon, S. Szedmak, J. Shawe-Taylor, Canonical correlation analysis: an overview with application to learning methods, Neural Comput., 16 (2004). https://doi.org/10.1162/0899766042321814 doi: 10.1162/0899766042321814
|
| [3] |
Q. Tian, C. Ma, M. Cao, S. Chen, H. Yin, A Convex Discriminant Semantic Correlation Analysis for Cross-View Recognition, IEEE Trans. Cybernetics, 52 (2020), 1–13. https://doi.org/10.1109/TCYB.2020.2988721 doi: 10.1109/TCYB.2020.2988721
|
| [4] |
Q. Tian, S. Xia, M. Cao, K. Chen, Reliable sensing data fusion through robust multiview prototype learning, IEEE Trans. Ind. Inform., 18 (2022), 2665–2673. https://doi.org/10.1109/TII.2021.3064358 doi: 10.1109/TII.2021.3064358
|
| [5] |
P. Zhuang, J. Wu, F. Porikli, C. Li, Underwater image enhancement with hyper-laplacian reflectance priors, IEEE Trans. Image Process., 31 (2022), 5442–5455. https://doi.org/10.1109/TIP.2022.3196546 doi: 10.1109/TIP.2022.3196546
|
| [6] |
V. Sindhwani, D. S. Rosenberg, An RKHS for multi-view learning and manifold co-regularization, IEEE Trans. Cybernetics, 99 (2020), 1–33. https://doi.org/10.1145/1390156.1390279 doi: 10.1145/1390156.1390279
|
| [7] | M. H. Quang, L. Bazzani, V. Murino, A unifying framework for vector-valued manifold regularization and multi-view learning, in Proceedings of the 30th International Conference on Machine Learning, (2013), 100–108. |
| [8] |
J. Zhao, X. Xie, X. Xu, S. Sun, Multi-view learning overview: Recent progress and new challenges, Inform. Fusion, 38 (2017), 43–54. https://doi.org/10.1016/j.inffus.2017.02.007 doi: 10.1016/j.inffus.2017.02.007
|
| [9] |
D. Zhang, T. He, F. Zhang, Real-time human mobility modeling with multi-view learning, ACM Trans. Intell. Syst. Technol., 9 (2017), 1–25. https://doi.org/10.1145/3092692 doi: 10.1145/3092692
|
| [10] |
D. Zhai, H. Chang, S. Shan, X. Chen, W. Gao, Multiview metric learning with global consistency and local smoothness, ACM Trans. Intell. Syst. Technol., 3 (2012), 1–22. https://doi.org/10.1145/2168752.2168767 doi: 10.1145/2168752.2168767
|
| [11] |
P. Zhuang, X. Ding, Underwater image enhancement using an edge-preserving filtering retinex algorithm, Multimed. Tools Appl., 79 (2020), 17257–17277. https://doi.org/10.1007/s11042-019-08404-4 doi: 10.1007/s11042-019-08404-4
|
| [12] | T. Sun, S. Chen, J. Yang, P. Shi, A novel method of combined feature extraction for recognition, in 2008 Eighth IEEE International Conference on Data Mining, (2008), 1043–1048. https://doi.org/10.1109/ICDM.2008.28 |
| [13] |
Y. Peng, D. Zhang, J. Zhang, A new canonical correlation analysis algorithm with local discrimination, Neural Process. Lett., 31 (2010), 1–15. https://doi.org/10.1007/s11063-009-9123-3 doi: 10.1007/s11063-009-9123-3
|
| [14] |
S. Su, H. Ge, Y. H. Yuan, Multi-patch embedding canonical correlation analysis for multi-view feature learning, J. Vis. Commun. Image R., 41 (2016), 47–57. https://doi.org/10.1016/j.jvcir.2016.09.004 doi: 10.1016/j.jvcir.2016.09.004
|
| [15] |
Q. S. Sun, Z. D. Liu, P. A. Heng, D. S. Xia, Rapid and brief communication: A theorem on the generalized canonical projective vectors, Pattern Recogn., 38 (2005), 449–452. https://doi.org/10.1016/j.patcog.2004.08.009 doi: 10.1016/j.patcog.2004.08.009
|
| [16] |
H. K. Ji, Q. S. Sun, Y. H. Yuan, Z. X. Ji, Fractional-order embedding supervised canonical correlations analysis with applications to feature extraction and recognition, Neural Process. Lett., 45 (2017), 279–297. https://doi.org/10.1007/s11063-016-9524-z doi: 10.1007/s11063-016-9524-z
|
| [17] | X. D. Zhou, X. H. Chen, S. C. Chen, Combined-feature-discriminability enhanced canonical correlation analysis, Pattern Recogn. Artif. Intell., 25 (2012), 285–291. |
| [18] |
P. N. Belhumeur, J. P. Hespanha, D. J. Kriegman, Eigenfaces vs. fisherfaces: Recognition using class specific linear projection, IEEE Trans. Pattern Anal. Mach. Intell., 19 (1997), 711–720. https://doi.org/10.1109/34.598228 doi: 10.1109/34.598228
|
| [19] |
F. Zhao, L. Qiao, F. Shi, P. Yap, D. Shen, Feature fusion via hierarchical supervised local CCA for diagnosis of autism spectrum disorder, Brain Imaging Behav., 11 (2017), 1050–1060. https://doi.org/10.1007/s11682-016-9587-5 doi: 10.1007/s11682-016-9587-5
|
| [20] |
M. Haghighat, M. Abdel-Mottaleb, W. Alhalabi, Discriminant correlation analysis: Real-time feature level fusion for multimodal biometric recognition, IEEE Trans. Inform. Foren. Sec., 11 (2016), 1984–1996. https://doi.org/10.1109/TIFS.2016.2569061 doi: 10.1109/TIFS.2016.2569061
|
| [21] | A. Sharma, A. Kumar, H. Daume, D. W. Jacobs, Generalized multiview analysis: A discriminative latent space, in 2012 IEEE Conference on Computer Vision and Pattern Recognition, (2012), 2160–2167. https://doi.org/10.1109/CVPR.2012.6247923 |
| [22] |
S. Sun, X. Xie, M. Yang, Multiview uncorrelated discriminant analysis, IEEE Trans. Cybernetics, 46 (2016), 3272–3284. https://doi.org/10.1109/TCYB.2015.2502248 doi: 10.1109/TCYB.2015.2502248
|
| [23] |
P. Hu, D. Peng, J. Guo, L. Zhen, Local feature based multi-view discriminant analysis, Knowl.-Based Syst., 149 (2018), 34–46. https://doi.org/10.1016/j.knosys.2018.02.008 doi: 10.1016/j.knosys.2018.02.008
|
| [24] |
X. Fu, K. Huang, M. Hong, N. D. Sidiropoulos, A. M. C. So, Scalable and flexible multiview MAX-VAR canonical correlation analysis, IEEE Trans. Signal Process., 65 (2017), 4150–4165. https://doi.org/10.1109/TSP.2017.2698365 doi: 10.1109/TSP.2017.2698365
|
| [25] |
D. Y. Gao, Canonical duality theory and solutions to constrained nonconvex quadratic programming, J. Global Optim., 29 (2004), 377–399. https://doi.org/10.1023/B:JOGO.0000048034.94449.e3 doi: 10.1023/B:JOGO.0000048034.94449.e3
|
| [26] |
J. Fan, S. Chen, Convex discriminant canonical correlation analysis, Pattern Recogn. Artif. Intell., 30 (2017), 740–746. https://doi.org/10.16451/j.cnki.issn1003-6059.201708008 doi: 10.16451/j.cnki.issn1003-6059.201708008
|
| [27] |
C. Tang, X. Zheng, X. Liu, W. Zhang, J. Zhang, J. Xiong, et al., Cross-view locality preserved diversity and consensus learning for multi-view unsupervised feature selection, IEEE Trans. Knowl. Data Eng., 34 (2022), 4705–4716. https://doi.org/10.1109/TKDE.2020.3048678 doi: 10.1109/TKDE.2020.3048678
|
| [28] |
C. Tang, Z. Li, J. Wang, X. Liu, W. Zhang, E. Zhu, Unified one-step multi-view spectral clustering, IEEE Trans. Knowl. Data Eng., 35 (2023), 6449–6460. https://doi.org/10.1109/TKDE.2022.3172687 doi: 10.1109/TKDE.2022.3172687
|
| [29] |
J. Wang, C. Tang, Z. Wan, W. Zhang, K. Sun, A. Y. Zomaya, Efficient and Effective One-Step Multiview Clustering, IEEE Trans. Neur. Net. Learn. Syst., (2023), 1–12. https://doi.org/10.1109/TNNLS.2023.3253246 doi: 10.1109/TNNLS.2023.3253246
|
| [30] | P. L. Lai, C. FyFe, KERNEL AND NONLINEAR CANONICAL CORRELATION ANALYSIS, International Journal of Neural Systems, 10 (2000), 365–377. |
| [31] | K Fukumizu, FR Bach, A Gretton, Statistical consistency of kernel canonical correlation analysis, J. Mach. Learn. Res., 8 (2007), 361–383. |
| [32] |
T. Liu, T. K. Pong, Further properties of the forward Cbackward envelope with applications to difference-of-convex programming, Comput. Optim. Appl., 67 (2017), 480–520. https://doi.org/10.1007/s10589-017-9900-2 doi: 10.1007/s10589-017-9900-2
|
| [33] |
T. P. Dinh, H. M. Le, H. A. Le Thi, F. Lauer, A difference of convex functions algorithm for switched linear regression, IEEE Trans. Automat. Contr., 59 (2014), 2277–2282. https://doi.org/10.1109/TAC.2014.2301575 doi: 10.1109/TAC.2014.2301575
|
| [34] | P. Zadeh, R. Hosseini, S. Sra, Geometric mean metric learning, in Proceedings of The 33rd International Conference on Machine Learning, (2016), 2464–2471. |
| [35] | B. Stephen, V. Lieven, Convex optimization, Cambridge University Press, Cambridge, 2004. |
| [36] |
V. Arsigny, P. Fillard, X. Pennec, N. Ayache, Geometric means in a novel vector space structure on symmetric positive-definite matrices, SIAM J. Matrix Anal. Appl., 29 (2007), 328–347. https://doi.org/10.1137/050637996 doi: 10.1137/050637996
|
| [37] | A. Papadopoulos, Metric Spaces, Convexity and Nonpositive Curvature, European Mathematical Society, Zurich, 2005. |
| [38] |
T. Rapcsák, Geodesic convexity in nonlinear optimization, J. Optim. Theory Appl., 69 (1991), 169–183. https://doi.org/10.1007/BF00940467 doi: 10.1007/BF00940467
|
| [39] |
C. L. Liu, K. Nakashima, H. Sako, H. Fujisawa, Handwritten digit recognition: investigation of normalization and feature extraction techniques, Pattern Recogn., 37 (2004), 265–279. https://doi.org/10.1016/S0031-3203(03)00224-3 doi: 10.1016/S0031-3203(03)00224-3
|
| [40] | Pawlicki, D. S. Lee, Hull, Srihari, Neural network models and their application to handwritten digit recognition, in IEEE 1988 International Conference on Neural Networks, 2 (1988), 63–70. https://doi.org/10.1109/ICNN.1988.23913 |
| [41] | C. H. Lampert, H. Nickisch, S. Harmeling, Learning to detect unseen object classes by between-class attribute transfer, in 2009 IEEE Conference on Computer Vision and Pattern Recognition, (2009), 951–958. https://doi.org/10.1109/CVPR.2009.5206594 |
| [42] |
C. R. Jack, M. A. Bernstein, N. C. Fox, P. Thompson, G. Alexander, D. Harvey, et al., The Alzheimer's disease neuroimaging initiative (ADNI): MRI methods, J. Magn. Reson. Imaging, 27 (2008), 685–691. https://doi.org/10.1002/jmri.21049 doi: 10.1002/jmri.21049
|
| [43] | S. Moschoglou, A. Papaioannou, C. Sagonas, J. Deng, I. Kotsia, S. Zafeiriou, Agedb: the first manually collected, in-the-wild age database, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, (2017), 51–59. |
| [44] | B. C. Chen, C. S. Chen, W. H. Hsu, Cross-age reference coding for age-invariant face recognition and retrieval, in Computer Vision – ECCV 2014., Springer, (2014), 768–783. https://doi.org/10.1007/978-3-319-10599-4_49 |
| [45] |
R. Rothe, R. Timofte, L. Van Gool, Deep expectation of real and apparent age from a single image without facial landmarks, Int. J. Comput. Vis., 126 (2018), 144–157. https://doi.org/10.1007/s11263-016-0940-3 doi: 10.1007/s11263-016-0940-3
|
| [46] | G. Guo, G. Mu, Y. Fu, T. S. Huang, Human age estimation using bio-inspired features, in 2009 IEEE Conference on Computer Vision and Pattern Recognition, (2009), 112–119. https://doi.org/10.1109/CVPR.2009.5206681 |
| [47] | Q. Zhu, M. C. Yeh, K. T. Cheng, S. Avidan, Fast human detection using a cascade of histograms of oriented gradients, in 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'06), (2006), 1491–1498. https://doi.org/10.1109/CVPR.2006.119 |
| [48] | K. Simonyan, A. Zisserma, Very deep convolutional networks for large-scale image recognition, preprint, arXiv: 1409.1556. |




Figures(5) / Tables(8)
Qing Tian, Heng Zhang, Shiyu Xia, Heng Xu, Chuang Ma. Cross-view learning with scatters and manifold exploitation in geodesic space[J]. Electronic Research Archive, 2023, 31(9): 5425-5441. doi: 10.3934/era.2023275







 DownLoad:
DownLoad: