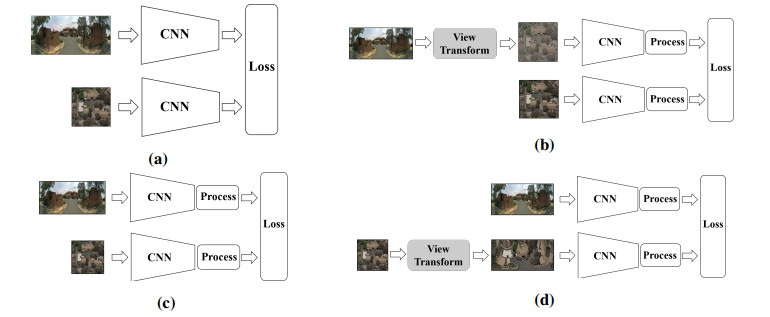
To address the problem that task-irrelevant objects such as cars, pedestrians and sky, will interfere with the extracted feature descriptors in cross-view image geo-localization, this paper proposes a novel method for cross-view image geo-localization, named as AENet. The method includes two main parts: an attention efficient network fusing channel and spatial attention mechanisms and a triplet loss function based on a multiple hard samples weighting strategy. In the first part, the EfficientNetV2 network is used to extract features from the images and preliminarily filter irrelevant features from the channel dimension, then the Triplet Attention layer is applied to further filter irrelevant features from the spatial dimension. In the second part, a multiple hard samples weighting strategy is proposed to enhance the learning of hard samples. Experimental results show that our proposed method significantly outperforms the state-of-the-art method on two existing benchmark datasets.
Citation: Jingqian Xu, Ma Zhu, Baojun Qi, Jiangshan Li, Chunfang Yang. AENet: attention efficient network for cross-view image geo-localization[J]. Electronic Research Archive, 2023, 31(7): 4119-4138. doi: 10.3934/era.2023210
To address the problem that task-irrelevant objects such as cars, pedestrians and sky, will interfere with the extracted feature descriptors in cross-view image geo-localization, this paper proposes a novel method for cross-view image geo-localization, named as AENet. The method includes two main parts: an attention efficient network fusing channel and spatial attention mechanisms and a triplet loss function based on a multiple hard samples weighting strategy. In the first part, the EfficientNetV2 network is used to extract features from the images and preliminarily filter irrelevant features from the channel dimension, then the Triplet Attention layer is applied to further filter irrelevant features from the spatial dimension. In the second part, a multiple hard samples weighting strategy is proposed to enhance the learning of hard samples. Experimental results show that our proposed method significantly outperforms the state-of-the-art method on two existing benchmark datasets.

| [1] |
J. Brejcha, M. Čadík, State-of-the-art in visual geo-localization, Pattern Anal. Appl., 20 (2017), 613–637. https://doi.org/10.1007/s10044-017-0611-1 doi: 10.1007/s10044-017-0611-1

|
| [2] | C. McManus, W. Churchill, W. Maddern, A. D. Stewart, P. Newman, Shady dealings: robust, long-term visual localisation using illumination invariance, in IEEE International Conference on Robotics and Automation (ICRA), (2014), 901–906. https://doi.org/10.1109/icra.2014.6906961 |
| [3] | S. Middelberg, T. Sattler, O. Untzelmann, L. Kobbelt, Scalable 6-dof localization on mobile devices, in European Conference on Computer Vision (ECCV), 8690 (2014), 268–283. https://doi.org/10.1007/978-3-319-10605-2_18 |
| [4] |
N. Suenderhauf, S. Shirazi, A. Jacobson, F. Dayoub, E. Pepperell, B. Upcroft, et al., Place recognition with ConvNet landmarks: viewpoint-robust, condition-robust, training-free, Rob. Sci. Syst., 2015 (2015), 1–10. https://doi.org/10.15607/RSS.2015.XI.022 doi: 10.15607/RSS.2015.XI.022
|
| [5] | J. Hays, A. A. Efros, Im2gps: estimating geographic information from a single image, in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2008), 1–8. https://doi.org/10.1109/CVPR.2008.4587784 |
| [6] |
A. R. Zamir, M. Shah, Image geo-localization based on multiplenearest neighbor feature matching usinggeneralized graphs, IEEE Trans. Pattern Anal. Mach. Intell., 36 (2014), 1546–1558. https://doi.org/10.1109/TPAMI.2014.2299799 doi: 10.1109/TPAMI.2014.2299799
|
| [7] | T. Sattler, M. Havlena, K. Schindler, M. Pollefeys, Large-scale location recognition and the geometric burstiness problem, in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2016), 1582–1590. https://doi.org/10.1109/CVPR.2016.175 |
| [8] | N. N. Vo, N. Jacobs, J. Hays, Revisiting im2gps in the deep learning era, in IEEE International Conference on Computer Vision (ICCV), (2017), 2621–2630. https://doi.org/10.1109/ICCV.2017.286 |
| [9] | M. Noda, T. Takahashi, D. Deguchi, I. Ide, H. Murase, Y. Kojima, et al., Vehicle ego-localization by matching in-vehicle camera images to an aerial image, in Asian Conference on Computer Vision Workshops, 6469 (2010), 163–173. https://doi.org/10.1007/978-3-642-22819-3_17 |
| [10] | T. Senlet, A. Elgammal, A framework for global vehicle localization using stereo images and satellite and road maps, in 2011 IEEE International Conference on Computer Vision Workshops (ICCV Workshops), (2011), 2034–2041. https://doi.org/10.1109/ICCVW.2011.6130498 |
| [11] | M. Bansal, H. S. Sawhney, H. Cheng, K. Daniilidis, Geo-localization of street views with aerial image databases, in 19th ACM international conference on Multimedia, (2011), 1125–1128. https://doi.org/10.1145/2072298.2071954 |
| [12] | T. Y. Lin, S. Belongie, J. Hays, Cross-view image geolocalization, in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2013), 891–898. https://doi.org/10.1109/CVPR.2013.120 |
| [13] |
D. G. Lowe, Distinctive image features from scale-invariant keypoints, Int. J. Comput. Vision, 60 (2004), 91–110. https://doi.org/10.1023/B:VISI.0000029664.99615.94 doi: 10.1023/B:VISI.0000029664.99615.94
|
| [14] | H. Bay, T. Tuytelaars, L. van Gool, Surf: speeded up robust features, in European Conference on Computer Vision, 3951 (2006), 404–417. https://doi.org/10.1007/11744023_32 |
| [15] | N. Dalal, B. Triggs, Histograms of oriented gradients for human detection, in IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'05), (2005), 886–893. https://doi.org/10.1109/CVPR.2005.177 |
| [16] | E. Shechtman, M. Irani, Matching local selfsimilarities across images and videos, in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2007), 1–8. https://doi.org/10.1109/CVPR.2007.383198 |
| [17] |
A. Oliva, A. Torralba, Modeling the shape of the scene: a holistic representation of the spatial envelope, Int. J. Comput. Vision, 42 (2017), 145–175. https://doi.org/10.1023/A:1011139631724 doi: 10.1023/A:1011139631724
|
| [18] | S. Workman, N. Jacobs, Wide-area image geolocalization with aerial reference imagery, in IEEE International Conference on Computer Vision (ICCV), (2015), 3961–3969. https://doi.org/10.1109/ICCV.2015.451 |
| [19] |
A. Krizhevsky, I. Sutskever, G. E. Hinton, Imagenet classification with deep convolutional neural networks, Commun. ACM, 60 (2017), 84–90. https://doi.org/10.1145/3065386 doi: 10.1145/3065386
|
| [20] | S. Hu, M. Feng, R. M. H. Nguyen, G. H. Lee, CVM-Net: cross-view matching network for image-based ground-to-aerial geo-localization, in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2018), 7258–7267. https://doi.org/10.1109/CVPR.2018.00758 |
| [21] | B. Sun, C. Chen, Y. Zhu, J. Jiang, GEOCAPSNET: ground to aerial view image geo-localization using capsule network, in IEEE International Conference on Multimedia and Expo (ICME), (2019), 742–747. https://doi.org/10.1109/ICME.2019.00133 |
| [22] | S. Cai, Y. Guo, S. Khan, J. Hu, G. Wen, Ground-to-aerial image geo-localization with a hard exemplar reweighting triplet loss, in IEEE International Conference on Computer Vision (ICCV), (2019), 8391–8400. https://doi.org/10.1109/ICCV.2019.00848 |
| [23] | Y. Shi, X. Yu, L. Liu, T. Zhang, H. Li, Optimal feature transport for cross-view image geo-localization, in AAAI Conference on Artificial Intelligence, 34 (2019), 11990–11997. https://doi.org/10.1609/aaai.v34i07.6875 |
| [24] | S. Karen, A. Zisserman, Very deep convolutional networks for large-scale image recognition, preprint, arXiv: 1409.1556. |
| [25] | S. Xie, R. Girshick, P. Dollar, Z. Tu, K. He, Aggregated residual transformations for deep neural networks, in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2017), 1492–1500. https://doi.org/10.1109/CVPR.2017.634 |
| [26] | K. Regmi, M. Shah, Bridging the domain gap for ground-to-aerial image matching, in IEEE International Conference on Computer Vision (ICCV), (2019), 470–479. https://doi.org/10.1109/ICCV.2019.00056 |
| [27] | M. Mehdi, S. Osindero, Conditional generative adversarial nets, preprint, arXiv: 1411.1784. |
| [28] | Y. Shi, L. Liu, X. Yu, H. Li, Spatial-aware feature aggregation for image based cross-view geo-localization, in 33rd Conference on Neural Information and Processing Systems (NIPS), (2019), 10090–10100. Available from: https://proceedings.neurips.cc/paper/2019/file/ba2f0015122a5955f8b3a50240fb91b2-Paper.pdf. |
| [29] | Y. Shi, X. Yu, D. Campbell, H. Li, Where am i looking at? Joint location and orientation estimation by cross-view matching, in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2020), 4064–4072. https://doi.org/10.1109/CVPR42600.2020.00412 |
| [30] | H. Yang, X. Lu, Y. Zhu, Cross-view geo-localization with layer-to-layer transformer, in 35th Conference on Neural Information and Processing Systems (NIPS), (2021), 29009–29020. Available from: https://papers.nips.cc/paper_files/paper/2021/file/f31b20466ae89669f9741e047487eb37-Paper.pdf. |
| [31] |
T. Wang, Z. Zheng, C. Yan, J. Zhang, Y. Sun, B. Zheng, et al., Each part matters: local patterns facilitate cross-view geo-localization, IEEE Trans. Circuits Syst. Video Technol., 32 (2022), 867–879. https://doi.org/10.1109/TCSVT.2021.3061265 doi: 10.1109/TCSVT.2021.3061265
|
| [32] | A. Toker, Q. Zhou, M. Maximov, L. Leal-Taixé, Coming down to earth: satellite-to-street view synthesis for geo-localization, in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2021), 6484–6493. https://doi.org/10.1109/CVPR46437.2021.00642 |
| [33] | M. Tan, Q. Le, Efficientnetv2: smaller models and faster training, in 38th International Conference on Machine Learning (ICML), preprint, arXiv: 2104.00298. |
| [34] | D. Misra, T. Nalamada, A. U. Arasanipalai, Q. Hou, Rotate to attend: convolutional triplet attention module, in IEEE/CVF Winter Conference on Applications of Computer Vision, (2021), 3139–3148. https://doi.org/10.1109/WACV48630.2021.00318 |
| [35] | N. N. Vo, J. Hays, Localizing and orienting street views using overhead imagery, in European Conference on Computer Vision (ECCV), 9905 (2016), 494–509. https://doi.org/10.1007/978-3-319-46448-0_30 |
| [36] | L. Liu, H. Li, Lending orientation to neural networks for cross-view geo-localization, in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 5624–5633. Available from: https://openaccess.thecvf.com/content_CVPR_2019/papers/Liu_Lending_Orientation_to_Neural_Networks_for_Cross-View_Geo-Localization_CVPR_2019_paper.pdf. |
| [37] | R. Rodrigues, M. Tani, Are these from the same place? Seeing the unseen in cross-view image geo-localization, in IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), (2021), 3753–3761. https://doi.org/10.1109/WACV48630.2021.00380 |
| [38] | A. Hermans, L. Beyer, B. Leibe, In defense of the triplet loss for person re-identification, preprint, arXiv: 1703.07737. |
| [39] | M. Tan, Q. Le, Efficientnet: rethinking model scaling for convolutional neural networks, International conference on machine learning, preprint, arXiv: 1905.11946. |
| [40] | B. Zoph, Q. V. Le, Neural architecture search with reinforcement learning, preprint, arXiv: 1611.01578. |
| [41] | M. Tan, B. Chen, R. Pang, V. Vasudevan, M. Sandler, A. Howard, et al., MnasNet: platform-aware neural architecture search for mobile, in IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2019), 2820–2828. https://doi.org/10.1109/CVPR.2019.00293 |
| [42] | S. Gupta, M. Tan, Efficientnet-edgetpu: creating accelerator-optimized neural networks with automl, Google AI Blog, 2019. Available from: https://torontoai.org/2019/08/05/efficientnet-edgetpu-creating-accelerator-optimized-neural-networks-with-automl/. |
| [43] | M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, L. Chen, Mobilenetv2: inverted residuals and linear bottlenecks, in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2018), 4510–4520. https://doi.org/10.1109/CVPR.2018.00474 |
| [44] |
J. Hu, L. Shen, S. Albanie, G. Sun, E. Wu, Squeeze-and excitation networks, IEEE Trans. Pattern Anal. Mach. Intell., 42 (2020), 2011–2023. https://doi.org/10.1109/TPAMI.2019.2913372 doi: 10.1109/TPAMI.2019.2913372
|
| [45] | J. Park, S. Woo, J. Y. Lee, I. S. Kweon, BAM: bottleneck attention module, preprint, arXiv: 1807.06514. |
| [46] | S. Woo, J. Park, J. Y. Lee, I. S. Kweon, CBAM: convolutional block attention module, in European Conference on Computer Vision (ECCV), 11211 (2018), 3–19. https://doi.org/10.1007/978-3-030-01234-2_1 |
| [47] | M. Zhai, Z. Bessinger, S. Workman, N. Jacobs, Predicting ground-level scene layout from aerial imagery, in IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2017), 867–875. https://doi.org/10.1109/CVPR.2017.440 |










Figures(11) / Tables(7)
Jingqian Xu, Ma Zhu, Baojun Qi, Jiangshan Li, Chunfang Yang. AENet: attention efficient network for cross-view image geo-localization[J]. Electronic Research Archive, 2023, 31(7): 4119-4138. doi: 10.3934/era.2023210







 DownLoad:
DownLoad: