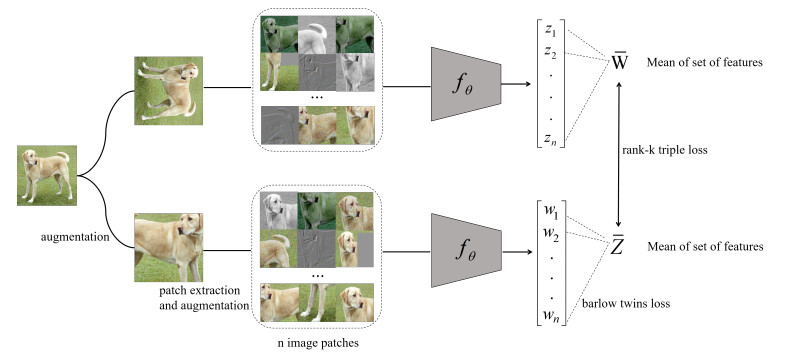
In this paper, we introduced a novel group self-supervised learning approach designed to improve visual representation learning. This new method aimed to rectify the limitations observed in conventional self-supervised learning. Traditional methods tended to focus on embedding distortion-invariant in single-view features. However, our belief was that a better representation can be achieved by creating a group of features derived from multiple views. To expand the siamese self-supervised architecture, we increased the number of image instances in each crop, enabling us to obtain an average feature from a group of views to use as a distortion, invariant embedding. The training efficiency has greatly increased with rapid convergence. When combined with a robust linear protocol, this group self-supervised learning model achieved competitive results in CIFAR-10, CIFAR-100, Tiny ImageNet, and ImageNet-100 classification tasks. Most importantly, our model demonstrated significant convergence gains within just 30 epochs as opposed to the typical 1000 epochs required by most other self-supervised techniques.
Citation: Zhongnian Li, Jiayu Wang, Qingcong Geng, Xinzheng Xu. Group-based siamese self-supervised learning[J]. Electronic Research Archive, 2024, 32(8): 4913-4925. doi: 10.3934/era.2024226
In this paper, we introduced a novel group self-supervised learning approach designed to improve visual representation learning. This new method aimed to rectify the limitations observed in conventional self-supervised learning. Traditional methods tended to focus on embedding distortion-invariant in single-view features. However, our belief was that a better representation can be achieved by creating a group of features derived from multiple views. To expand the siamese self-supervised architecture, we increased the number of image instances in each crop, enabling us to obtain an average feature from a group of views to use as a distortion, invariant embedding. The training efficiency has greatly increased with rapid convergence. When combined with a robust linear protocol, this group self-supervised learning model achieved competitive results in CIFAR-10, CIFAR-100, Tiny ImageNet, and ImageNet-100 classification tasks. Most importantly, our model demonstrated significant convergence gains within just 30 epochs as opposed to the typical 1000 epochs required by most other self-supervised techniques.

| [1] |
Y. Liu, M. Jin, S. Pan, C. Zhou, Y. Zheng, F. Xia, et al., Graph self-supervised learning: A survey, IEEE Trans. Knowl. Data Eng., 35 (2022), 5879–5900. https://doi.org/10.1109/TKDE.2022.3172903 doi: 10.1109/TKDE.2022.3172903

|
| [2] |
S. Liu, A. Mallol-Ragolta, E. Parada-Cabeleiro, K. Qian, X. Jing, A. Kathan, et al., Audio self-supervised learning: A survey, Patterns, 3 (2022), 100616. https://doi.org/10.1016/j.patter.2022.100616 doi: 10.1016/j.patter.2022.100616
|
| [3] |
S. Albelwi, Survey on self-supervised learning: auxiliary pretext tasks and contrastive learning methods in imaging, Entropy, 24 (2022), 551. https://doi.org/10.3390/e24040551 doi: 10.3390/e24040551
|
| [4] |
L. Jing, Y. Tian, Self-supervised visual feature learning with deep neural networks: A survey, IEEE Trans. Pattern Anal. Mach. Intell., 43 (2021), 4037–4058. https://doi.org/10.1109/TPAMI.2020.2992393 doi: 10.1109/TPAMI.2020.2992393
|
| [5] |
P. Fang, X. Li, Y. Yan, S. Zhang, Q. Kang, X. Li, et al., Connecting the dots in self-supervised learning: A brief survey for beginners, J. Comput. Sci. Technol., 37 (2022), 507–526. https://doi.org/10.1007/s11390-022-2158-x doi: 10.1007/s11390-022-2158-x
|
| [6] | K. He, H. Fan, Y. Wu, S. Xie, R. Girshick, Momentum Contrast for unsupervised visual representation learning, in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2020), 9726–9735. https://doi.org/10.1109/CVPR42600.2020.00975 |
| [7] | T. Chen, S. Kornblith, M. Norouzi, G. Hinton, A simple framework for contrastive learning of visual representations, in Proceedings of the 37th International Conference on Machine Learning, (2020), 1597–1607. |
| [8] | J. Zbontar, L. Jing, I. Misra, Y. LeCun, S. Deny, Barlow Twins: Self-supervised learning via redundancy reduction, in Proceedings of the 38th International Conference on Machine Learning, (2021), 12310–12320. |
| [9] |
S. Huang, X. Jin, Q. Jiang, L. Liu, Deep learning for image colorization: Current and future prospects, Eng. Appl. Artif. Intell., 114 (2022), 105006. https://doi.org/10.1016/j.engappai.2022.105006 doi: 10.1016/j.engappai.2022.105006
|
| [10] |
M. Xu, S. Yoon, A. Fuentes, D. S. Park, A comprehensive survey of image augmentation techniques for deep learning, Pattern Recognit., 137 (2023), 109347. https://doi.org/10.1016/j.patcog.2023.109347 doi: 10.1016/j.patcog.2023.109347
|
| [11] | C. Shorten, T. M. Khoshgoftaar, A survey on image data augmentation for deep learning, J. Big Data, 6 (2019). https://doi.org/10.1186/s40537-019-0197-0 |
| [12] | M. Caron, I. Misra, J. Mairal, P. Goyal, P. Bojanowski, A. Joulin, Unsupervised learning of visual features by contrasting cluster assignments, in Proceedings of the 34th International Conference on Neural Information Processing Systems, (2020), 9912–9924. |
| [13] | J. B. Grill, F. Strub, F. Altché, C. Tallec, P. Richemond, E. Buchatskaya, et al., Bootstrap Your Own Latent-a new approach to self-supervised learning, in Proceedings of the 34th International Conference on Neural Information Processing Systems, (2020), 21271–21284. |
| [14] | X. Chen, K. He, Exploring simple siamese representation learning, in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2021), 15745–15753. https://doi.org/10.1109/CVPR46437.2021.01549 |
| [15] | S. Chopra, R. Hadsell, Y. LeCun, Learning a similarity metric discriminatively, with application to face verification, in 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'05), (2005), 539–546. https://doi.org/10.1109/CVPR.2005.202 |
| [16] |
J. Bromley, J. W. Bentz, L. Bottou, I. Guyon, Y. Lecun, C. Moore, et al., Signature verification using a "siamese" time delay neural network, Int. J. Pattern Recognit. Artif. Intell., 7 (1993), 669–688. https://doi.org/10.1142/S0218001493000339 doi: 10.1142/S0218001493000339
|
| [17] | S. Zagoruyko, N. Komodakis, Learning to compare image patches via convolutional neural networks, in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2015), 4353–4361. https://doi.org/10.1109/CVPR.2015.7299064 |
| [18] | X. Chen, K. He, Exploring simple siamese representation learning, in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2021), 15745–15753. https://doi.org/10.1109/CVPR46437.2021.01549 |
| [19] | R. Balestriero, M. Ibrahim, V. Sobal, A. Morcos, S. Shekhar, T. Goldstein, et al., A cookbook of self-supervised learning, preprint, arXiv: 2304.12210. |
| [20] | P. Zhou, Y. Zhou, C. Si, W. Yu, T. K. Ng, S. Yan, Mugs: A multi-granular self-supervised learning framework, preprint, arXiv: 2203.14415. |
| [21] | M. Caron, H. Touvron, I. Misra, H. Jegou, J. Mairal, P. Bojanowski, et al., Emerging properties in self-supervised vision transformers, in 2021 IEEE/CVF International Conference on Computer Vision (ICCV), (2021), 9630–9640. https://doi.org/10.1109/ICCV48922.2021.00951 |
| [22] | J. Zhou, C. Wei, H. Wang, W. Shen, C. Xie, A. Yuille, et al., iBOT: Image bert pre-training with online tokenizer, preprint, arXiv: 2111.07832. |
| [23] | A. Bardes, J. Ponce, Y. LeCun, VICReg: Variance-Invariance-Covariance Regularization for self-supervised learning, preprint, arXiv: 2105.04906. |
| [24] | G. Wang, K. Wang, G. Wang, P. H. S. Torr, L. Lin, Solving inefficiency of self-supervised representation learning, in 2021 IEEE/CVF International Conference on Computer Vision (ICCV), (2021), 9485–9495. https://doi.org/10.1109/ICCV48922.2021.00937 |
| [25] | D. Dwibedi, Y. Aytar, J. Tompson, P. Sermanet, A. Zisserman, With a little help from my friends: Nearest-Neighbor Contrastive Learning of visual Representations, in 2021 IEEE/CVF International Conference on Computer Vision (ICCV), (2021), 9568–9577. https://doi.org/10.1109/ICCV48922.2021.00945 |
| [26] | S. A. Koohpayegani, A. Tejankar, H. Pirsiavash, Mean Shift for self-supervised learning, in 2021 IEEE/CVF International Conference on Computer Vision (ICCV), (2021), 10306–10315. https://doi.org/10.1109/ICCV48922.2021.01016 |
| [27] | S. Tang, F. Zhu, L. Bai, R. Zhao, C. Wang, W. Ouyang, Unifying visual contrastive learning for object recognition from a graph perspective, in Computer Vision-ECCV 2022, (2022), 649–667. https://doi.org/10.1007/978-3-031-19809-0_37 |
| [28] | F. Schroff, D. Kalenichenko, J. Philbin, Facenet: A unified embedding for face recognition and clustering, in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2015), 815–823. https://doi.org/10.1109/CVPR.2015.7298682 |
| [29] |
R. Miao, Y. Yang, Y. Ma, X. Juan, H. Xue, J. Tang, et al., Negative samples selecting strategy for graph contrastive learning, Inf. Sci., 613 (2022), 667–681. https://doi.org/10.1016/j.ins.2022.09.024 doi: 10.1016/j.ins.2022.09.024
|
| [30] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (2016), 770–778. https://doi.org/10.1109/CVPR.2016.90 |
| [31] | H. B. Barlow, Unsupervised learning, Neural Comput., 1 (1989), 295–311. https://doi.org/10.1162/neco.1989.1.3.295 |
| [32] | W. G. C. Bandara, C. M. De Melo, V. M. Patel, Guarding Barlow Twins against overfitting with mixed samples, preprint, arXiv: 2312.02151. |
| [33] | Y. You, I. Gitman, B. Ginsburg, Large batch training of convolutional networks, preprint, arXiv: 1708.03888. |
Figures(1) / Tables(5)
Zhongnian Li, Jiayu Wang, Qingcong Geng, Xinzheng Xu. Group-based siamese self-supervised learning[J]. Electronic Research Archive, 2024, 32(8): 4913-4925. doi: 10.3934/era.2024226







 DownLoad:
DownLoad: