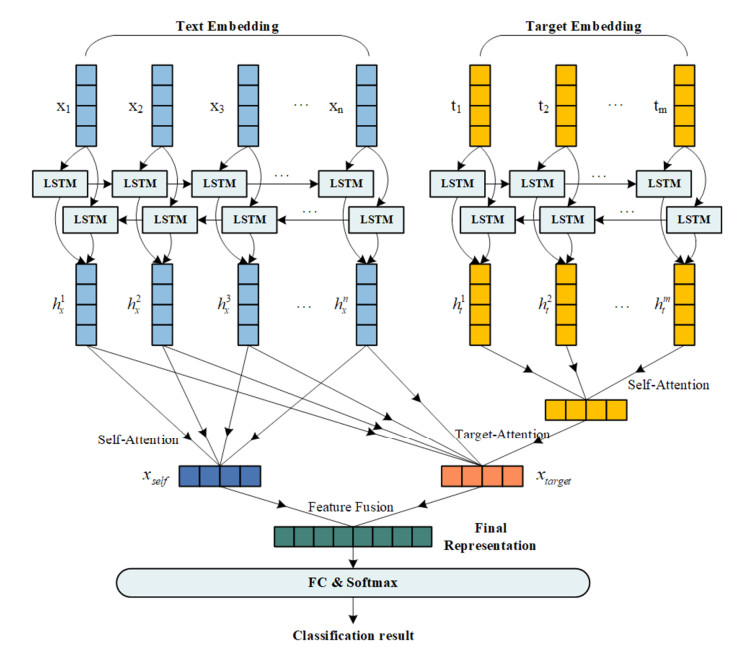
When drafting official government documents, it is necessary to firmly grasp the main idea and ensure that any positions stated within the text are consistent with those in previous documents. In combination with the field's demands, By taking advantage of suitable text-mining techniques to harvest opinions from sentences in official government documents, the efficiency of official government document writers can be significantly increased. Most existing opinion mining approaches employ text classification methods to directly mine the sentential text of official government documents while disregarding the influence of the objects described within the documents (i.e., the target entities) on the sentence opinion categories. To address these issues, this study proposes a sentence opinion mining model that fuses the target entities within documents. Based on the Bi-directional long short-term (BiLSTM) and attention mechanisms, the model fully considers the attention given by a official government document's target entity to different words within the corresponding sentence text, as well as the dependency between words of the sentence. The model subsequently fuses two by using feature vector fusion to obtain the final semantic representation of the text, which is then classified using a fully connected network and softmax function. Experimental results based on a dataset of official government documents show that the model significantly outperforms baseline models such as Text-convolutional neural network (TextCNN), recurrent neural network (RNN), and BiLSTM.
Citation: Xiao Ma, Teng Yang, Feng Bai, Yunmei Shi. Sentence opinion mining model for fusing target entities in official government documents[J]. Electronic Research Archive, 2023, 31(6): 3495-3509. doi: 10.3934/era.2023177
When drafting official government documents, it is necessary to firmly grasp the main idea and ensure that any positions stated within the text are consistent with those in previous documents. In combination with the field's demands, By taking advantage of suitable text-mining techniques to harvest opinions from sentences in official government documents, the efficiency of official government document writers can be significantly increased. Most existing opinion mining approaches employ text classification methods to directly mine the sentential text of official government documents while disregarding the influence of the objects described within the documents (i.e., the target entities) on the sentence opinion categories. To address these issues, this study proposes a sentence opinion mining model that fuses the target entities within documents. Based on the Bi-directional long short-term (BiLSTM) and attention mechanisms, the model fully considers the attention given by a official government document's target entity to different words within the corresponding sentence text, as well as the dependency between words of the sentence. The model subsequently fuses two by using feature vector fusion to obtain the final semantic representation of the text, which is then classified using a fully connected network and softmax function. Experimental results based on a dataset of official government documents show that the model significantly outperforms baseline models such as Text-convolutional neural network (TextCNN), recurrent neural network (RNN), and BiLSTM.

| [1] |
W. Zhang, F. Wang, H. Zhao. J. Zhang, Topic extraction and analysis of S&T policies based on structural decomposition of government documents in Chinese, Stud. Sci. Sci., 38 (2020), 1185–1196. https://doi.org/10.16192/j.cnki.1003-2053.2020.07.005 doi: 10.16192/j.cnki.1003-2053.2020.07.005

|
| [2] |
Y. Zhai, The theoretical evolution and practical exploration of China's e-government development in the past 40 years of reform and opening up: from business online to service online in Chinese, E-Gov., 12 (2018), 80–89. https://doi.org/10.16582/j.cnki.dzzw.2018.12.008 doi: 10.16582/j.cnki.dzzw.2018.12.008
|
| [3] |
Q. Qin, X. Zhang, On the institutional attribute of documents jointly issued by the party and government in Chinese, J. Party School Cent. Comm. CPC. (Chin. Acad. Governance), 25 (2021), 120–128. https://doi.org/10.14119/j.cnki.zgxb.2021.04.014 doi: 10.14119/j.cnki.zgxb.2021.04.014
|
| [4] |
Y. Yang, F. Wang, Whether deleveraging task conflicts with industrial policy: an empirical study based on enterprises' debt structure in Chinese, J. Zhongnan Univ. Econ. Law, 2 (2020), 3–13. https://doi.org/10.19639/j.cnki.issn1003-5230.20200427.003 doi: 10.19639/j.cnki.issn1003-5230.20200427.003
|
| [5] |
S. Sun, C. Luo, J. Chen, A review of natural language processing techniques for opinion mining systems, Inf. Fusion, 36 (2017), 10–25. https://doi.org/10.1016/j.inffus.2016.10.004 doi: 10.1016/j.inffus.2016.10.004
|
| [6] |
J. Gong, X. Huang, Text categorization framework based on improved TF-IDF and k-nearest neighbor in Chinese, Comput. Eng. Des., 39 (2018), 1340–1344+1349. https://doi.org/10.16208/j.issn1000-7024.2018.05.024 doi: 10.16208/j.issn1000-7024.2018.05.024
|
| [7] |
M. T. Zulfikar, Suharjito, Detection traffic congestion based on Twitter data using machine learning, Procedia Comput. Sci., 2019 (2019), 118–124. https://doi.org/10.1016/j.procs.2019.08.148 doi: 10.1016/j.procs.2019.08.148
|
| [8] |
B. Zhao, L. Wang, H. Guo, Weighted naive bayes text classification algorithm based on poisson distribution in Chinese, Comput. Eng., 46 (2020), 91–96. https://doi.org/10.19678/j.issn.1000-3428.0054056 doi: 10.19678/j.issn.1000-3428.0054056
|
| [9] |
X. Huang, G. Liu, X. Liu, A. Yang, Sentiment classification depth model based on word2vec and bi-directional LSTM in Chinese, Appl. Res. Comput., 36 (2019), 3583–3587+3596. https://doi.org/10.19734/j.issn.1001-3695.2018.08.0599 doi: 10.19734/j.issn.1001-3695.2018.08.0599
|
| [10] |
K. Cheng, Y. Yue, Z. Song, Sentiment classification based on part-of-speech and self-attention mechanism, IEEE Access, 2020 (2020), 16387–16396. https://doi.org/10.1109/ACCESS.2020.2967103 doi: 10.1109/ACCESS.2020.2967103
|
| [11] |
X. Wu, L. Chen, T. Wei, T. T. Fan, Sentiment analysis of chinese short text based on self-attention and Bi-LSTM in Chinese, J. Chin. Inf. Process., 33 (2019), 100–107. https://doi.org/10.3969/j.issn.1003-0077.2019.06.015 doi: 10.3969/j.issn.1003-0077.2019.06.015
|
| [12] |
T. Li, D. Ji, Sentiment analysis of micro-blog based on SVM and CRF using various combinations of features in Chinese, Appl. Res. Comput., 32 (2015), 978–981. https://doi.org/10.3969/j.issn.1001-3695.2015.04.004 doi: 10.3969/j.issn.1001-3695.2015.04.004
|
| [13] | A. Goel, J. Gautam, S. Kumar, Real time sentiment analysis of tweets using naive bayes, in 2016 2nd International Conference on Next Generation Computing Technologies (NGCT), (2016), 257–261. https://doi.org/10.1109/NGCT.2016.7877424 |
| [14] |
J. Ababneh, Application of naive bayes, decision tree, and k-nearest neighbors for automated text classification, Mod. Appl. Sci., 13 (2019), 31–36. https://doi.org/10.5539/mas.v13n11p31 doi: 10.5539/mas.v13n11p31
|
| [15] |
R. Ahuja, S. C. Sharma, Sentiment analysis on different domains using machine learning algorithms, Adv. Data Inf. Sci., 2022 (2022), 143–153. https://doi.org/10.1007/978-981-16-5689-7_13 doi: 10.1007/978-981-16-5689-7_13
|
| [16] | Y. Kim, Convolutional neural networks for sentence classification, arXiv preprint, (2014), arXiv: 1408.5882. https://doi.org/10.48550/arXiv.1408.5882 |
| [17] | R. Johnson, Z. Tong, Deep pyramid convolutional neural networks for text categorization, in Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, (2017), 562–570. https://doi.org/10.18653/v1/p17-1052 |
| [18] |
S. Yu, D. Liu, Y. Zhang, S. Zhao, W. Wang, DPTCN: A novel deep CNN model for short text classification, J. Intell. Fuzzy Syst., 6 (2021), 7093–7100. https://doi.org/10.3233/JIFS-210970 doi: 10.3233/JIFS-210970
|
| [19] | Y. Wang, A. Sun, J. Han, Y. Liu, X. Zhu, Sentiment analysis by capsules, in the Web Conference, (2018), 1165–1174. https://doi.org/10.1145/3178876.3186015 |
| [20] | R. Wang, Z. Li, J. Cao, C. Tong, W. Lei, Convolutional recurrent neural networks for text classification, in 2019 International Joint Conference on Neural Networks, (2019), 1–6. https://doi.org/10.1109/IJCNN.2019.8852406 |
| [21] |
A. Singh, S. K. Dargar, A. Gupta, A. Kumar, A. K. Srivastava, M. Srivastava, et al., Evolving long short-term memory network-based text classification, Comput. Intell. Neurosci., 2022 (2022), 1687–5265. https://doi.org/10.1155/2022/4725639 doi: 10.1155/2022/4725639
|
| [22] | D. Bahdanau, K. Cho, Y. Bengio, Neural machine translation by jointly learning to align and translate, arXiv preprint, (2014), arXiv: 1409.0473. https://doi.org/10.48550/arXiv.1409.0473 |
| [23] | Y. Wang, M. Huang, X. Zhu, L. Zhao, Attention-based LSTM for aspect-level sentiment classification, in Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, (2016), 606–615. https://doi.org/0.18653/v1/D16-1058 |
| [24] |
Y. Liu, P. Li, X. Hu, Combining context-relevant features with multi-stage attention network for short text classification, Comput. Speech Lang., 71 (2021), 1–14. https://doi.org/10.1016/j.csl.2021.101268 doi: 10.1016/j.csl.2021.101268
|
| [25] |
C. Hu, N. Liang, Deeper attention-based LSTM for aspect sentiment analysis in Chinese, Appl. Res. Comput., 36 (2019), 1075–1079, https://doi.org/10.19734/j.issn.1001-3695.2017.11.0736 doi: 10.19734/j.issn.1001-3695.2017.11.0736
|
| [26] | T. Mikolov, K. Chen, G. Corrado, J. Dean, Efficient estimation of word representations in vector space, arXiv preprint, (2013), arXiv: 1301.3781. https://doi.org/10.48550/arXiv.1301.3781 |
| [27] | J. Bu, L. Ren, S. Zheng, Y. Yang, J. Wang, F. Zhang, et al., ASAP: A chinese review dataset towards aspect category sentiment analysis and rating prediction, arXiv preprint, (2021), arXiv: 2103.06605. https://doi.org/10.48550/arXiv.2103.06605 |
| [28] |
F. Song, L. Gao, Performance evaluation metric for text classifiers in Chinese, Comput. Eng., 30 (2004), 107–127. https://doi.org/10.3969/j.issn.1000-3428.2004.13.044 doi: 10.3969/j.issn.1000-3428.2004.13.044
|
| [29] | D. Ma, S. Li, X. Zhang, H. Wang, Interactive attention networks for aspect-level sentiment classification, in Twenty-Sixth International Joint Conference on Artificial Intelligence, (2017), 1–7. https://doi.org/10.24963/ijcai.2017/568 |
| [30] | A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. Gomez, et al., Attention is all you need, arXiv preprint, (2017), arXiv: 1706.03762. https://doi.org/10.48550/arXiv.1706.03762 |
| [31] | P. Zhou, W. Shi, J. Tian, Z. Qi, B. Li, H. Hao, et al., Attention-based bidirectional long short-term memory networks for relation classification, in Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, (2016), 207–212. https://doi.org/10.18653/v1/P16-2034 |
| [32] | S. Sabour, N. Frosst, G. E. Hinton, Dynamic routing between capsules, in Proceedings of the 31st International Conference on Neural Information Processing Systems, (2017), 3859–3869. |
Figures(1) / Tables(6)
Xiao Ma, Teng Yang, Feng Bai, Yunmei Shi. Sentence opinion mining model for fusing target entities in official government documents[J]. Electronic Research Archive, 2023, 31(6): 3495-3509. doi: 10.3934/era.2023177







 DownLoad:
DownLoad: