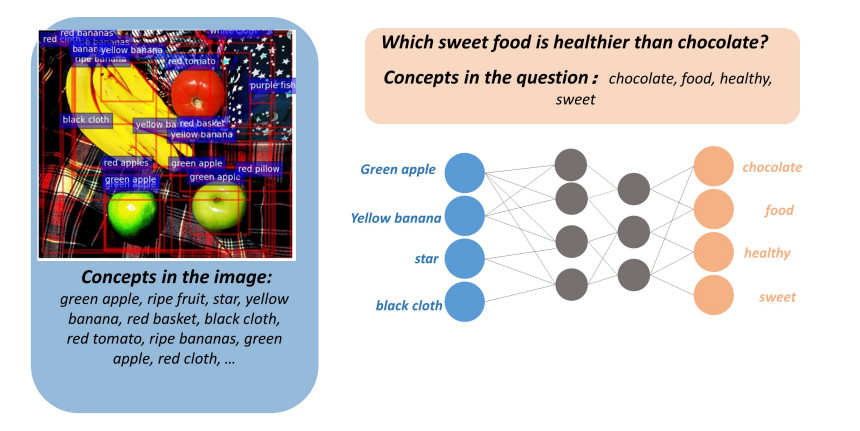
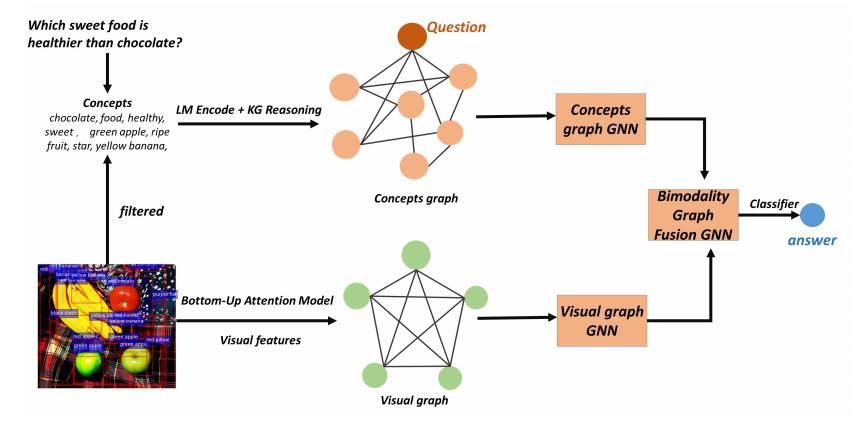
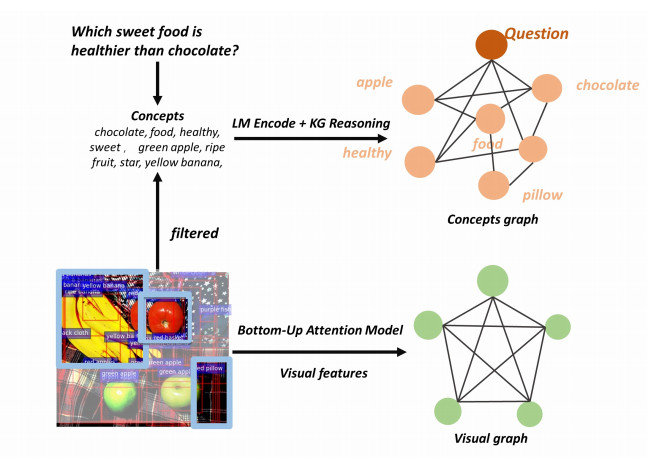
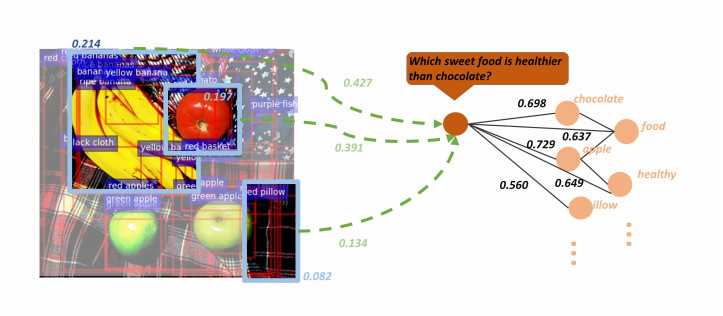
Visual Question Answering (VQA) with external knowledge requires external knowledge and visual content to answer questions about images. The defect of existing VQA solutions is that they need to identify task-related information in the obtained pictures, questions, and knowledge graphs. It is necessary to properly fuse and embed the information between different modes identified, to reduce the noise and difficulty in cross-modality reasoning of VQA models. However, this process of rationally integrating information between different modes and joint reasoning to find relevant evidence to correctly predict the answer to the question still deserves further study. This paper proposes a bimodal Graph Neural Network model combining pre-trained Language Models and Knowledge Graphs (BIGNN-LM-KG). Researchers built the concepts graph by the images and questions concepts separately. In constructing the concept graph, we used the combined reasoning advantages of LM+KG. Specifically, use KG to jointly infer the images and question entity concepts to build a concept graph. Use LM to calculate the correlation score to screen the nodes and paths of the concept graph. Then, we form a visual graph from the visual and spatial features of the filtered image entities. We use the improved GNN to learn the representation of the two graphs and to predict the most likely answer by fusing the information of two different modality graphs using a modality fusion GNN. On the common dataset of VQA, the model we proposed obtains good experiment results. It also verifies the validity of each component in the model and the interpretability of the model.
Citation: Zhenyu Yang, Lei Wu, Peian Wen, Peng Chen. Visual Question Answering reasoning with external knowledge based on bimodal graph neural network[J]. Electronic Research Archive, 2023, 31(4): 1948-1965. doi: 10.3934/era.2023100
Visual Question Answering (VQA) with external knowledge requires external knowledge and visual content to answer questions about images. The defect of existing VQA solutions is that they need to identify task-related information in the obtained pictures, questions, and knowledge graphs. It is necessary to properly fuse and embed the information between different modes identified, to reduce the noise and difficulty in cross-modality reasoning of VQA models. However, this process of rationally integrating information between different modes and joint reasoning to find relevant evidence to correctly predict the answer to the question still deserves further study. This paper proposes a bimodal Graph Neural Network model combining pre-trained Language Models and Knowledge Graphs (BIGNN-LM-KG). Researchers built the concepts graph by the images and questions concepts separately. In constructing the concept graph, we used the combined reasoning advantages of LM+KG. Specifically, use KG to jointly infer the images and question entity concepts to build a concept graph. Use LM to calculate the correlation score to screen the nodes and paths of the concept graph. Then, we form a visual graph from the visual and spatial features of the filtered image entities. We use the improved GNN to learn the representation of the two graphs and to predict the most likely answer by fusing the information of two different modality graphs using a modality fusion GNN. On the common dataset of VQA, the model we proposed obtains good experiment results. It also verifies the validity of each component in the model and the interpretability of the model.

| [1] | S. Antol, A. Agrawal, J. Lu, M. Mitchell, D. Batra, C. L. Zitnick, et al., Vqa: visual question answering, in Proceedings of the IEEE International Conference on Computer Vision (ICCV), (2015), 2425–2433. https://doi.org/10.1109/ICCV.2015.279 |
| [2] | R. Cadene, H. Ben-Younes, M. Cord, N. Thome, Murel: multimodal relational reasoning for visual question answering, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 1989–1998. https://doi.org/10.1109/CVPR.2019.00209 |
| [3] | L. Li, Z. Gan, Y. Cheng, J. Liu, Relation-aware graph attention network for visual question answering, in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), (2019), 10313–10322. https://doi.org/10.1109/ICCV.2019.01041 |
| [4] | H. Ben-Younes, R. Cadene, N. Thome, M. Cord, Block: bilinear superdiagonal fusion for visual question answering and visual relationship detection, in Proceedings of the AAAI Conference on Artificial Intelligence (AI), 33 (2019), 8102–8109. https://doi.org/10.1609/aaai.v33i01.33018102 |
| [5] |
C. Song, M. Liu, J. Cao, Y. Zheng, H. Gong, G. Chen, Maximizing network lifetime based on transmission range adjustment in wireless sensor networks, Comput. Commun., 32 (2009), 1316–1325. https://doi.org/10.1016/j.comcom.2009.02.002 doi: 10.1016/j.comcom.2009.02.002

|
| [6] | N. Liu, M. Liu, W. Lou, G. Chen, J. Cao, PVA in VANETs: stopped cars are not silent, in Proceedings of the 2011 IEEE International Conference on Computer Communications (INFOCOM), (2011), 431–435. https://doi.org/10.1109/INFCOM.2011.5935198 |
| [7] | M. Liu, H. Gong, Y. Wen, G. Chen, J. Cao, The last minute: efficient data evacuation strategy for sensor networks in post-disaster applications, in 2011 Proceedings IEEE INFOCOM, IEEE, Shanghai, China, (2011), 291–295. https://doi.org/10.1109/INFCOM.2011.5935131 |
| [8] | N. Liu, M. Liu, G. Chen, J. Cao, The sharing at roadside: vehicular content distribution using parked vehicles, in 2012 Proceedings IEEE INFOCOM, IEEE, Orlando, FL, USA, (2012), 2641–2645. https://doi.org/10.1109/INFCOM.2012.6195670 |
| [9] | P. Wang, Q. Wu, C. Shen, A. van den Hengel, A. Dick, Explicit knowledge-based reasoning for visual question answering, preprint, arXiv: 1511.02570. |
| [10] |
P. Wang, Q. Wu, C. Shen, A. Dick, A. van den Hengel, Fvqa: fact-based visual question answering, IEEE Trans. Pattern Anal. Mach. Intell., 40 (2017), 2413–2427. https://doi.org/10.1109/TPAMI.2017.2754246 doi: 10.1109/TPAMI.2017.2754246
|
| [11] | M. Narasimhan, S. Lazebnik, A. Schwing, Out of the box: reasoning with graph convolution nets for factual visual question answering, in Advances in Neural Information Processing Systems (NIPS), 31 (2018). Available from: https://papers.nips.cc/paper/2018/file/c26820b8a4c1b3c2aa868d6d57e14a79-Paper.pdf. |
| [12] | N. Kassner, H. Schütze, Negated and misprimed probes for pretrained language models: birds can talk, but cannot fly, preprint, arXiv: 1911.03343. |
| [13] | H. Ren, W. Hu, J. Leskovec, Query2box: reasoning over knowledge graphs in vector space using box embeddings, preprint, arXiv: 2002.05969. |
| [14] | H. Ren, J. Leskovec, Beta embeddings for multi-hop logical reasoning in knowledge graphs, in Advances in Neural Information Processing Systems (NIPS), 33 (2020), 19716–19726. |
| [15] | B. Y. Lin, X. Chen, J. Chen, X. Ren, Kagnet: knowledge-aware graph networks for commonsense reasoning, preprint, arXiv: 1909.02151. |
| [16] | A. Bordes, N. Usunier, A. Garcia-Duran, J. Weston, O. Yakhnenko, Translating embeddings for modeling multi-relational data, in Advances in Neural Information Processing Systems (NIPS), 26 (2013). Available from: https://papers.nips.cc/paper/2013/file/1cecc7a77928ca8133fa24680a88d2f9-Paper.pdf. |
| [17] | K. Guu, J. Miller, P. Liang, Traversing knowledge graphs in vector space, preprint, arXiv: 1506.01094. |
| [18] | Y. Feng, X. Chen, B. Y. Lin, P. Wang, J. Yan, X. Ren, Scalable multi-hop relational reasoning for knowledge-aware question answering, preprint, arXiv: 2005.00646. |
| [19] | M. Malinowski, M. Rohrbach, M. Fritz, Ask your neurons: a neural-based approach to answering questions about images, in Proceedings of the IEEE International Conference on Computer Vision (ICCV), (2015), 1–9. https://doi.org/10.1109/ICCV.2015.9 |
| [20] | Z. Yang, X. He, J. Gao, L. Deng, A. Smola, Stacked attention networks for image question answering, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2016), 21–29. https://doi.org/10.1109/CVPR.2016.10 |
| [21] | D. Yu, J. Fu, T. Mei, Y. Rui, Multi-level attention networks for visual question answering, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2017), 4709–4717. https://doi.org/10.1109/CVPR.2017.446 |
| [22] | R. Hu, A. Rohrbach, T. Darrell, K. Saenko, Language-conditioned graph networks for relational reasoning, in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), (2019), 10294–10303. https://doi.org/10.1109/ICCV.2019.01039 |
| [23] | P. Wang, Q. Wu, J. Cao, C. Shen, L. Gao, A. van den Hengel, Neighbourhood watch: referring expression comprehension via language-guided graph attention networks, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2019), 1960–1968. https://doi.org/10.1109/CVPR.2019.00206 |
| [24] | L. Peng, S. Yang, Y. Bin, G. Wang, Progressive graph attention network for video question answering, in Proceedings of the 29th ACM International Conference on Multimedia (ACM MM), (2021), 2871–2879. https://doi.org/10.1145/3474085.3475193 |
| [25] |
Y. Xi, Y. Zhang, S. Ding, S. Wan, Visual question answering model based on visual relationship detection, Signal Process. Image Commun., 80 (2020), 115648. https://doi.org/10.1016/j.image.2019.115648 doi: 10.1016/j.image.2019.115648
|
| [26] |
Y. Wu, Y. Ma, S. Wan, Multi-scale relation reasoning for multi-modal visual question answering, Signal Process. Image Commun., 96 (2021), 116319. https://doi.org/10.1016/j.image.2021.116319 doi: 10.1016/j.image.2021.116319
|
| [27] |
Z. Wu, S. Pan, F. Chen, G. Long, C. Zhang, S. Y. Philip, A comprehensive survey on graph neural networks, IEEE Trans. Neural Networks Learn. Syst., 32 (2020), 4–24. https://doi.org/10.1109/TNNLS.2020.2978386 doi: 10.1109/TNNLS.2020.2978386
|
| [28] | T. N. Kipf, M. Welling, Semi-supervised classification with graph convolutional networks, preprint, arXiv: 1609.02907. |
| [29] | M. Schlichtkrull, T. N. Kipf, P. Bloem, R. van den Berg, I. Titov, M. Welling, Modeling relational data with graph convolutional networks, in Proceedings of the European Semantic Web Conference (ESWC), Springer, (2018), 593–607. https://doi.org/10.1007/978-3-319-93417-4_38 |
| [30] | X. Wang, H. Ji, C. Shi, B. Wang, Y. Ye, P. Cui, et al., Heterogeneous graph attention network, in The World Wide Web Conference, (2019), 2022–2032. https://doi.org/10.1145/3308558.3313562 |
| [31] | L. Hu, T. Yang, C. Shi, H. Ji, X. Li, Heterogeneous graph attention networks for semi-supervised short text classification, in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), (2019), 4821–4830. https://doi.org/10.18653/v1/D19-1488 |
| [32] | K. Bollacker, C. Evans, P. Paritosh, T. Sturge, J. Taylor, Freebase: a collaboratively created graph database for structuring human knowledge, in Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data (SIGMOD), (2008), 1247–1250. https://doi.org/10.1145/1376616.1376746 |
| [33] | F. Petroni, T. Rocktäschel, P. Lewis, A. Bakhtin, Y. Wu, A. H. Miller, et al., Language models as knowledge bases, preprint, arXiv: 1909.01066. |
| [34] | A. Bosselut, H. Rashkin, M. Sap, C. Malaviya, A. Celikyilmaz, Y. Choi, Comet: commonsense transformers for knowledge graph construction, in Association for Computational Linguistics (ACL), (2019), 4762–4779. https://doi.org/10.18653/v1/P19-1470 |
| [35] | W. Liu, P. Zhou, Z. Zhao, Z. Wang, Q. Ju, H. Deng, et al., K-bert: enabling language representation with knowledge graph, in Proceedings of the AAAI Conference on Artificial Intelligence (AI), 34 (2020), 2901–2908. https://doi.org/10.1609/aaai.v34i03.5681 |
| [36] | J. Bao, N. Duan, Z. Yan, M. Zhou, T. Zhao, Constraint-based question answering with knowledge graph, in Proceedings of COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers (COLING), (2016), 2503–2514. Available from: https://aclanthology.org/C16-1236.pdf. |
| [37] | H. Sun, B. Dhingra, M. Zaheer, K. Mazaitis, R. Salakhutdinov, W. W. Cohen, Open domain question answering using early fusion of knowledge bases and text, preprint, arXiv: 1809.00782. |
| [38] | P. Anderson, X. He, C. Buehler, D. Teney, M. Johnson, S. Gould, et al., Bottom-up and top-down attention for image captioning and visual question answering, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2018), 6077–6086. Available from: https://openaccess.thecvf.com/content_cvpr_2018/papers/Anderson_Bottom-Up_and_Top-Down_CVPR_2018_paper.pdf. |
| [39] | M. Yasunaga, H. Ren, A. Bosselut, P. Liang, J. Leskovec, Qa-gnn: reasoning with language models and knowledge graphs for question answering, preprint, arXiv: 2104.06378. |
| [40] | R. Speer, J. Chin, C. Havasi, Conceptnet 5.5: an open multilingual graph of general knowledge, in Thirty-first AAAI Conference on Artificial Intelligence (AI), 31(2017). https://doi.org/10.1609/aaai.v31i1.11164 |
| [41] | P. Veličković, G. Cucurull, A. Casanova, A. Romero, P. Lio, Y. Bengio, Graph attention networks, preprint, arXiv: 1710.10903. |
| [42] | T. Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, et al., Microsoft coco: common objects in context, in European conference on computer vision (ECCV), Springer, (2014), 740–755. https://doi.org/10.1007/978-3-319-10602-1_48 |
| [43] | Y. Zhu, O. Groth, M. Bernstein, F. F. Li, Visual7w: grounded question answering in images, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2016), 4995–5004. https://doi.org/10.1109/CVPR.2016.540 |
| [44] |
R. Krishna, Y. Zhu, O. Groth, J. Johnson, K. Hata, J. Kravitz, et al., Visual genome: connecting language and vision using crowdsourced dense image annotations, Int. J. Comput. Vision, 123 (2017), 32–73. https://doi.org/10.1007/s11263-016-0981-7 doi: 10.1007/s11263-016-0981-7
|
| [45] | G. Li, H. Su, W. Zhu, Incorporating external knowledge to answer open-domain visual questions with dynamic memory networks, preprint, arXiv: 1712.00733. |
Figures(5) / Tables(3)
Zhenyu Yang, Lei Wu, Peian Wen, Peng Chen. Visual Question Answering reasoning with external knowledge based on bimodal graph neural network[J]. Electronic Research Archive, 2023, 31(4): 1948-1965. doi: 10.3934/era.2023100







 DownLoad:
DownLoad: