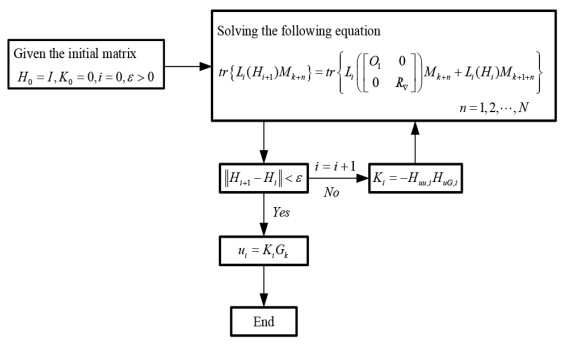
In this paper, a reinforcement Q-learning method based on value iteration (Ⅵ) is proposed for a class of model-free stochastic linear quadratic (SLQ) optimal tracking problem with time delay. Compared with the traditional reinforcement learning method, Q-learning method avoids the need for accurate system model. Firstly, the delay operator is introduced to construct a novel augmented system composed of the original system and the command generator. Secondly, the SLQ optimal tracking problem is transformed into a deterministic one by system transformation and the corresponding Q function of SLQ optimal tracking control is derived. Based on this, Q-learning algorithm is proposed and its convergence is proved. Finally, a simulation example shows the effectiveness of the proposed algorithm.
Citation: Xufeng Tan, Yuan Li, Yang Liu. Stochastic linear quadratic optimal tracking control for discrete-time systems with delays based on Q-learning algorithm[J]. AIMS Mathematics, 2023, 8(5): 10249-10265. doi: 10.3934/math.2023519
In this paper, a reinforcement Q-learning method based on value iteration (Ⅵ) is proposed for a class of model-free stochastic linear quadratic (SLQ) optimal tracking problem with time delay. Compared with the traditional reinforcement learning method, Q-learning method avoids the need for accurate system model. Firstly, the delay operator is introduced to construct a novel augmented system composed of the original system and the command generator. Secondly, the SLQ optimal tracking problem is transformed into a deterministic one by system transformation and the corresponding Q function of SLQ optimal tracking control is derived. Based on this, Q-learning algorithm is proposed and its convergence is proved. Finally, a simulation example shows the effectiveness of the proposed algorithm.

| [1] |
H. Modares, F. L. Lewis, Optimal tracking control of nonlinear partially-unknown constrained-input systems using integral reinforcement learning, Automatica, 50 (2014), 1780–1792. https://doi.org/10.1016/j.automatica.2014.05.011 doi: 10.1016/j.automatica.2014.05.011

|
| [2] |
B. Zhao, Y. Li, Model-free adaptive dynamic programming based near-optimal decentralized tracking control of reconfigurable manipulators, Int. J. Control, Autom. Syst., 16 (2018), 478–490. https://doi.org/10.1007/s12555-016-0711-5 doi: 10.1007/s12555-016-0711-5
|
| [3] |
T. Huang, D. Liu, A self-learning scheme for residential energy system control and management, Neural Comput. Appl., 22 (2013), 259–269. https://doi.org/10.1007/s00521-011-0711-6 doi: 10.1007/s00521-011-0711-6
|
| [4] |
M. Gluzman, J. G. Scott, A. Vladimirsky, Optimizing adaptive cancer therapy: dynamic programming and evolutionary game theory, Proc. Royal Soc. B: Biol. Sci., 287 (2020), 20192454. https://doi.org/10.1098/rspb.2019.2454 doi: 10.1098/rspb.2019.2454
|
| [5] |
I. Ha, E. Gilbert, Robust tracking in nonlinear systems, IEEE Trans. Automat. Control, 32 (1987), 763–771. https://doi.org/10.1109/TAC.1987.1104710 doi: 10.1109/TAC.1987.1104710
|
| [6] |
M. A. Rami, X. Y. Zhou, Linear matrix inequalities, Riccati equations and indefinite stochastic linear quadratic controls, IEEE Trans. Automat. Control, 45 (2000), 1131–1143. https://doi.org/10.1109/9.863597 doi: 10.1109/9.863597
|
| [7] |
R. Byers, Solving the algebraic Riccati equation with the matrix sign function, Linear Algebra Appl., 89 (1987), 267–279. https://doi.org/10.1016/0024-3795(87)90222-9 doi: 10.1016/0024-3795(87)90222-9
|
| [8] |
D. Vrabie, O. Pastravanu, M. Abu-Khalaf, F. L. Lewis, Adaptive optimal control for continuous-time linear systems based on policy iteration, Automatica, 45 (2009), 477–484. https://doi.org/10.1016/j.automatica.2008.08.017 doi: 10.1016/j.automatica.2008.08.017
|
| [9] |
B. Kiumarsi, F. L. Lewis, M. B. Naghibi-Sistani, A. Karimpour, Optimal tracking control of unknown discrete-time linear systems using input-output measured data, IEEE Trans. Cybern., 45 (2015), 2770–2779. https://doi.org/10.1109/TCYB.2014.2384016 doi: 10.1109/TCYB.2014.2384016
|
| [10] |
B. Kiumarsi, F. L. Lewis, H. Modares, A. Karimpour, M. B. Naghibi-Sistani, Reinforcement Q-learning for optimal tracking control of linear discrete-time systems with unknown dynamics, Automatica, 50 (2014), 1167–1175. https://doi.org/10.1016/j.automatica.2014.02.015 doi: 10.1016/j.automatica.2014.02.015
|
| [11] | G. Wang, H. Zhang, Model-free value iteration algorithm for continuous-time stochastic linear quadratic optimal control problems, arXiv, 2022. https://doi.org/10.48550/arXiv.2203.06547 |
| [12] | H. Zhang, Adaptive dynamic programming-based algorithm for infinite-horizon linear quadratic stochastic optimal control problems, arXiv, 2022. https://doi.org/10.48550/arXiv.2210.04486 |
| [13] |
R. Liu, Y. Li, X. Liu, Linear-quadratic optimal control for unknown mean-field stochastic discrete-time system via adaptive dynamic programming approach, Neurocomputing, 282 (2018), 16–24. https://doi.org/10.1016/j.neucom.2017.12.007 doi: 10.1016/j.neucom.2017.12.007
|
| [14] |
X. Chen, F. Wang, Neural-network-based stochastic linear quadratic optimal tracking control scheme for unknown discrete-time systems using adaptive dynamic programming, Control Theory Technol., 19 (2021), 315–327. https://doi.org/10.1007/s11768-021-00046-y doi: 10.1007/s11768-021-00046-y
|
| [15] | Z. Zhang, X. Zhao, Stochastic linear quadratic optimal tracking control for stochastic discrete time systems based on Q-learning, J. Nanjing Univ. Inf. Sci. Technol. (Nat. Sci.), 13 (2021), 548–555. |
| [16] |
Y. Liu, H. Zhang, Y. Luo, J. Han, ADP based optimal tracking control for a class of linear discrete-time system with multiple delays, J. Franklin Inst., 353 (2016), 2117–2136. https://doi.org/10.1016/j.jfranklin.2016.03.012 doi: 10.1016/j.jfranklin.2016.03.012
|
| [17] |
B. L. Zhang, Q. L. Han, X. M. Zhang, X. Yu, Sliding mode control with mixed current and delayed states for offshore steel jacket platforms, IEEE Trans. Control Syst. Technol., 22 (2014), 1769–1783. https://doi.org/10.1109/TCST.2013.2293401 doi: 10.1109/TCST.2013.2293401
|
| [18] |
M. J. Park, O. M. Kwon, J. H. Ryu, Advanced stability criteria for linear systems with time-varying delays, J. Franklin Inst., 355 (2018), 520–5433. https://doi.org/10.1016/j.jfranklin.2017.11.029 doi: 10.1016/j.jfranklin.2017.11.029
|
| [19] |
H. Zhang, Y. Luo, D. Liu, Neural-network-based near-optimal control for a class of discrete-time affine nonlinear systems with control constraints, IEEE Trans. Neural Networks, 20 (2009), 1490–1503. https://doi.org/10.1109/TNN.2009.2027233 doi: 10.1109/TNN.2009.2027233
|
| [20] |
H. Zhang, Z. Wang, D. Liu, Global asymptotic stability of recurrent neural networks with multiple time-varying delays, IEEE Trans. Neural Networks, 19 (2008), 855–873. https://doi.org/10.1109/TNN.2007.912319 doi: 10.1109/TNN.2007.912319
|
| [21] |
T. Wang, H. Zhang, Y. Luo, Infinite-time stochastic linear quadratic optimal control for unknown discrete-time systems using adaptive dynamic programming approach, Neurocomputing, 171 (2016), 379–386. https://doi.org/10.1016/j.neucom.2015.06.053 doi: 10.1016/j.neucom.2015.06.053
|
| [22] |
A. Garate-Garcia, L. A. Marquez-Martinez, C. H. Moog, Equivalence of linear time-delay systems, IEEE Trans. Automat. Control, 56 (2011), 666–670. https://doi.org/10.1109/TAC.2010.2095550 doi: 10.1109/TAC.2010.2095550
|
| [23] |
Y. Liu, R. Yu, Model-free optimal tracking control for discrete-time system with delays using reinforcement Q-learning, Electron. Lett., 54 (2018), 750–752. https://doi.org/10.1049/el.2017.3238 doi: 10.1049/el.2017.3238
|
| [24] |
H. Zhang, Q. Wei, Y. Luo, A novel infinite-time optimal tracking control scheme for a class of discrete-time nonlinear systems via the greedy HDP iteration algorithm, IEEE Trans. Syst., Man, Cybern. B, 38 (2008), 937–942. https://doi.org/10.1109/TSMCB.2008.920269 doi: 10.1109/TSMCB.2008.920269
|
| [25] |
J. Shi, D. Yue, X. Xie, Adaptive optimal tracking control for nonlinear continuous-time systems with time delay using value iteration algorithm, Neurocomputing, 396 (2020), 172–178. https://doi.org/10.1016/j.neucom.2018.07.098 doi: 10.1016/j.neucom.2018.07.098
|
| [26] |
Q. Wei, D. Liu, Adaptive dynamic programming for optimal tracking control of unknown nonlinear systems with application to coal gasification, IEEE Trans. Automat. Sci. Eng., 11 (2014), 1020–1036. https://doi.org/10.1109/TASE.2013.2284545 doi: 10.1109/TASE.2013.2284545
|
| [27] |
T. Wang, H. Zhang, Y. Luo, Stochastic linear quadratic optimal control for model-free discrete-time systems based on Q-learning algorithm, Neurocomputing, 312 (2018), 1–8. https://doi.org/10.1016/j.neucom.2018.04.018 doi: 10.1016/j.neucom.2018.04.018
|
| [28] |
F. L. Lewis, D. Vrabie, Reinforcement learning and adaptive dynamic programming for feedback control, IEEE Circuits Syst. Mag., 9 (2009), 32–50. https://doi.org/10.1109/MCAS.2009.933854 doi: 10.1109/MCAS.2009.933854
|



Figures(4)

Xufeng Tan, Yuan Li, Yang Liu. Stochastic linear quadratic optimal tracking control for discrete-time systems with delays based on Q-learning algorithm[J]. AIMS Mathematics, 2023, 8(5): 10249-10265. doi: 10.3934/math.2023519







 DownLoad:
DownLoad: