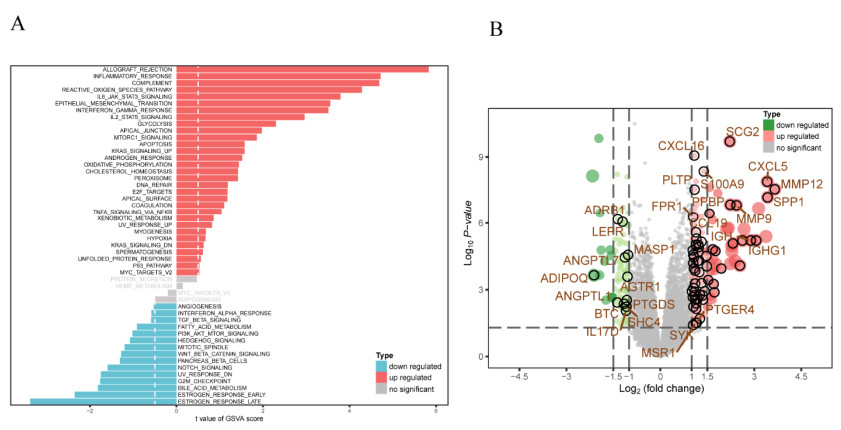
Background: Calcific aortic valve stenosis (CAVS) is a crucial cardiovascular disease facing aging societies. Our research attempts to identify immune-related genes through bioinformatics and machine learning analysis. Two machine learning strategies include Least Absolute Shrinkage Selection Operator (LASSO) and Support Vector Machine Recursive Feature Elimination (SVM-RFE). In addition, we deeply explore the role of immune cell infiltration in CAVS, aiming to study the potential therapeutic targets of CAVS and explore possible drugs. Methods: Download three data sets related to CAVS from the Gene Expression Omnibus. Gene set variation analysis (GSVA) looks for potential mechanisms, determines differentially expressed immune-related genes (DEIRGs) by combining the ImmPort database with CAVS differential genes, and explores the functions and pathways of enrichment. Two machine learning methods, LASSO and SVM-RFE, screen key immune signals and validate them in external data sets. Single-sample GSEA (ssGSEA) and CIBERSORT analyze the subtypes of immune infiltrating cells and integrate the analysis with DEIRGs and key immune signals. Finally, the possible targeted drugs are analyzed through the Connectivity Map (CMap). Results: GSVA analysis of the gene set suggests that it is highly correlated with multiple immune pathways. 266 differential genes (DEGs) integrate with immune genes to obtain 71 DEIRGs. Enrichment analysis found that DEIRGs are related to oxidative stress, synaptic membrane components, receptor activity, and a variety of cardiovascular diseases and immune pathways. Angiotensin II Receptor Type 1(AGTR1), Phospholipid Transfer Protein (PLTP), Secretogranin II (SCG2) are identified as key immune signals of CAVS by machine learning. Immune infiltration found that B cells naï ve and Macrophages M2 are less in CAVS, while Macrophages M0 is more in CAVS. Simultaneously, AGTR1, PLTP, SCG2 are highly correlated with a variety of immune cell subtypes. CMap analysis found that isoliquiritigenin, parthenolide, and pyrrolidine-dithiocarbamate are the top three targeted drugs related to CAVS immunity. Conclusion: The key immune signals, immune infiltration and potential drugs obtained from the research play a vital role in the pathophysiological progress of CAVS.
Citation: Chenyang Jiang, Weidong Jiang. AGTR1, PLTP, and SCG2 associated with immune genes and immune cell infiltration in calcific aortic valve stenosis: analysis from integrated bioinformatics and machine learning[J]. Mathematical Biosciences and Engineering, 2022, 19(4): 3787-3802. doi: 10.3934/mbe.2022174
Background: Calcific aortic valve stenosis (CAVS) is a crucial cardiovascular disease facing aging societies. Our research attempts to identify immune-related genes through bioinformatics and machine learning analysis. Two machine learning strategies include Least Absolute Shrinkage Selection Operator (LASSO) and Support Vector Machine Recursive Feature Elimination (SVM-RFE). In addition, we deeply explore the role of immune cell infiltration in CAVS, aiming to study the potential therapeutic targets of CAVS and explore possible drugs. Methods: Download three data sets related to CAVS from the Gene Expression Omnibus. Gene set variation analysis (GSVA) looks for potential mechanisms, determines differentially expressed immune-related genes (DEIRGs) by combining the ImmPort database with CAVS differential genes, and explores the functions and pathways of enrichment. Two machine learning methods, LASSO and SVM-RFE, screen key immune signals and validate them in external data sets. Single-sample GSEA (ssGSEA) and CIBERSORT analyze the subtypes of immune infiltrating cells and integrate the analysis with DEIRGs and key immune signals. Finally, the possible targeted drugs are analyzed through the Connectivity Map (CMap). Results: GSVA analysis of the gene set suggests that it is highly correlated with multiple immune pathways. 266 differential genes (DEGs) integrate with immune genes to obtain 71 DEIRGs. Enrichment analysis found that DEIRGs are related to oxidative stress, synaptic membrane components, receptor activity, and a variety of cardiovascular diseases and immune pathways. Angiotensin II Receptor Type 1(AGTR1), Phospholipid Transfer Protein (PLTP), Secretogranin II (SCG2) are identified as key immune signals of CAVS by machine learning. Immune infiltration found that B cells naï ve and Macrophages M2 are less in CAVS, while Macrophages M0 is more in CAVS. Simultaneously, AGTR1, PLTP, SCG2 are highly correlated with a variety of immune cell subtypes. CMap analysis found that isoliquiritigenin, parthenolide, and pyrrolidine-dithiocarbamate are the top three targeted drugs related to CAVS immunity. Conclusion: The key immune signals, immune infiltration and potential drugs obtained from the research play a vital role in the pathophysiological progress of CAVS.

| [1] |
P. Büttner, L. Feistner, P. Lurz, H. Thiele, J. D. Hutcheson, F. Schlotter, Dissecting calcific aortic valve disease—The role, etiology, and drivers of valvular fibrosis, Front Cardiovasc. Med., 10 (2021), 660797. https://doi.org/10.3389/fcvm.2021.660797 doi: 10.3389/fcvm.2021.660797

|
| [2] |
B. Alushi, L. Curini, M. R. Christopher, H. Grubitzch, U. Landmesser, A. Amedei, et al., Calcific aortic valve disease-natural history and future therapeutic strategies, Front Pharmacol., 13 (2020), 685. https://doi.org/10.3389/fphar.2020.00685 doi: 10.3389/fphar.2020.00685
|
| [3] |
A. D. Vito, A. Donato, I. Presta, T. Mancuso, F. S. Brunetti, P. Mastroroberto, et al., Extracellular matrix in calcific aortic valve disease: Architecture, dynamic and perspectives, Int. J. Mol. Sci., 22 (2021), 913. https://doi.org/10.3390/ijms22020913 doi: 10.3390/ijms22020913
|
| [4] |
J. Rysä, Novel insights into the molecular basis of calcific aortic valve disease, J. Thorac. Dis., 12 (2020), 6419–6421. https://doi.org/10.21037/jtd-20-1669 doi: 10.21037/jtd-20-1669
|
| [5] |
A. Kapelouzou, C. Kontogiannis, D. I. Tsilimigras, G. Georgiopoulos, L. Kaklamanis, L. Tsourelis, et al., Differential expression patterns of Toll Like Receptors and Interleukin-37 between calcific aortic and mitral valve cusps in humans, Cytokine, 116 (2019), 150–160. https://doi.org/10.1016/j.cyto.2019.01.009 doi: 10.1016/j.cyto.2019.01.009
|
| [6] | J. Podolec, J. Baran, M. Siedlinski, M. Urbanczyk, M. Krupinski, K. Bartus, et al., Serum rantes, transforming growth factor-β1 and interleukin-6 levels correlate with cardiac muscle fibrosis in patients with aortic valve stenosis, J. Physiol. Pharmacol., 69 (2018), 615–623. |
| [7] |
J. Weisell, P. Ohukainen, J. Näpänkangas, S. Ohlmeier, U. Bergmann, T. Peltonen, et al., Heat shock protein 90 is downregulated in calcific aortic valve disease, BMC Cardiovasc. Disord., 19 (2019), 306. https://doi.org/10.1186/s12872-019-01294-2 doi: 10.1186/s12872-019-01294-2
|
| [8] |
G. Karadimou, O. Plunde, S. Pawelzik, M. Carracedo, P. Eriksson, A. Franco-Cereceda, et al., TLR7 Expression Is Associated with M2 Macrophage Subset in Calcific Aortic Valve Stenosis, Cells, 9 (2020), 9071710. https://doi.org/10.3390/cells9071710 doi: 10.3390/cells9071710
|
| [9] |
G. Li, W. Qiao, W. Zhang, F. Li, J. Shi, N. Dong, The shift of macrophages toward M1 phenotype promotes aortic valvular calcification, J. Thorac. Cardiovasc. Surg., 153 (2017), 1318–1327. https://doi.org/10.1016/j.jtcvs.2017.01.052 doi: 10.1016/j.jtcvs.2017.01.052
|
| [10] |
M. A. Raddatz, T. Huffstater, M. R. Bersi, B. I. Reinfeld, M. Z. Madden, S. E. Booton, et al., Macrophages promote aortic valve cell calcification and alter STAT3 splicing, Arterioscler., Thromb., Vasc. Biol., 40 (2020), e153–e165. https://doi.org/10.1161/ATVBAHA.120.314360 doi: 10.1161/ATVBAHA.120.314360
|
| [11] |
B. Erkhem-Ochir, W. Tatsuishi, T. Yokobori, T. Ohno, K. Hatori, T. Handa, et al., Inflammatory and immune checkpoint markers are associated with the severity of aortic stenosis, JTCVS Open, 5 (2021), 1–12. https://doi.org/10.1016/j.xjon.2020.11.007 doi: 10.1016/j.xjon.2020.11.007
|
| [12] |
S. H. Lee, J. Choi, Involvement of inflammatory responses in the early development of calcific aortic valve disease: lessons from statin therapy, Anim. Cells Syst., 22 (2018), 390–399. https://doi.org/10.1080/19768354.2018.1528175 doi: 10.1080/19768354.2018.1528175
|
| [13] |
N. Venardos, X. Deng, Q. Yao, M. J. Weyant, T. B. Reece, X. Meng, et al., Simvastatin reduces the TLR4-induced inflammatory response in human aortic valve interstitial cells, J. Surg. Res., 230 (2018), 101–109. https://doi.org/10.1016/j.jss.2018.04.054 doi: 10.1016/j.jss.2018.04.054
|
| [14] |
P. Sarajlic, O. Plunde, A. Franco-Cereceda, M. Bäck, Artificial intelligence models reveal sex-specific gene expression in aortic valve calcification, JACC Basic Transl. Sci., 6 (2021), 403–412. https://doi.org/10.1016/j.jacbts.2021.02.005 doi: 10.1016/j.jacbts.2021.02.005
|
| [15] |
J. Qiu, B. Peng, Y. Tang, Y. Qian, Pi Guo, M. Li, et al., CpG methylation signature predicts recurrence in early-stage hepatocellular carcinoma: Results from a multicenter study, J. Clin. Oncol., 35 (2017), 734–742. https://doi.org/10.1200/JCO.2016.68.2153 doi: 10.1200/JCO.2016.68.2153
|
| [16] |
E. Zhao, H. Xie, Y. Zhang, Predicting diagnostic gene biomarkers associated with immune infiltration in patients with acute myocardial infarction, Front. Cardiovasc. Med., 7 (2020), 586871. https://doi.org/10.3389/fcvm.2020.586871 doi: 10.3389/fcvm.2020.586871
|
| [17] |
X. Zheng, F. Wang, J. Zhang, X. Cui, F. Jiang, N. Chen, et al., Using machine learning to predict atrial fibrillation diagnosed after ischemic stroke, Int. J. Cardiol., 347 (2022), 21–27. https://doi.org/10.1016/j.ijcard.2021.11.005 doi: 10.1016/j.ijcard.2021.11.005
|
| [18] |
D. Lambrechts, E. Wauters, B. Boeckx, S. Aibar, D. Nittner, O. Burton, et al., Phenotype molding of stromal cells in the lung tumor microenvironment, Nat. Med., 24 (2018), 1277–1289. https://doi.org/10.1038/s41591-018-0096-5 doi: 10.1038/s41591-018-0096-5
|
| [19] |
M. E. Ritchie, B. Phipson, D. Wu, Y. Hu, C. W. Law, W. Shi, et al., limma powers differential expression analyses for RNA-sequencing and microarray studies, Nucleic Acids Res., 43 (2015), e47. https://doi.org/10.1093/nar/gkv007 doi: 10.1093/nar/gkv007
|
| [20] |
C. Ginestet, ggplot2: Elegant graphics for data analysis, J. R. Stat. Soc. Ser. A, 174 (2011), 245–245. https://doi.org/10.1111/j.1467-985X.2010.00676_9.x doi: 10.1111/j.1467-985X.2010.00676_9.x
|
| [21] |
A. Liberzon, A. Subramanian, R. Pinchback, H. Thorvaldsdóttir, P. Tamayo, J. P. Mesirov, Molecular signatures database (MSigDB) 3.0, Bioinformatics, 27 (2011), 1739–1740. https://doi.org/10.1093/bioinformatics/btr260 doi: 10.1093/bioinformatics/btr260
|
| [22] |
P. Ghosh, S. Azam, M. Jonkman, A. Karim, F. M. J. M. Shamrat, E. Ignatious, et al., Efficient prediction of cardiovascular disease using machine learning algorithms with relief and LASSO feature selection techniques, IEEE Access, 9 (2021), 19304–19326. https://doi.org/10.1109/ACCESS.2021.3053759 doi: 10.1109/ACCESS.2021.3053759
|
| [23] |
B. Richhariya, M. Tanveer, A. H. Rashid, Diagnosis of Alzheimer's disease using universum support vector machine based recursive feature elimination (USVM-RFE), Biomed. Signal Process. Control, 59 (2020), 101903. https://doi.org/10.1016/j.bspc.2020.101903 doi: 10.1016/j.bspc.2020.101903
|
| [24] |
J. Friedman, T. Hastie, R. Tibshirani, Regularization paths for generalized linear models via coordinate descent, J. Stat. Softw., 33 (2010), 1–22. https://doi.org/10.18637/jss.v033.i01 doi: 10.18637/jss.v033.i01
|
| [25] |
M. Huang, Y. Hung, W. M. Lee, R. K. Li, B. Jiang, SVM-RFE based feature selection and Taguchi parameters optimization for multiclass SVM classifier, Sci. World J., 2014 (2014), 795624. https://doi.org/10.1155/2014/795624 doi: 10.1155/2014/795624
|
| [26] |
B. Xiao, L. Liu, A. Li, C. Xiang, P. Wang, H. Li, et al., Identification and verification of immune-related gene prognostic signature based on ssGSEA for osteosarcoma, Front. Oncol., 10 (2020), 607622. https://doi.org/10.3389/fonc.2020.607622 doi: 10.3389/fonc.2020.607622
|
| [27] |
J. Kawada, S. Takeuchi, H. Imai, T. Okumura, K. Horiba, T. Suzuki, et al., Immune cell infiltration landscapes in pediatric acute myocarditis analyzed by CIBERSORT, J. Cardiol., 77 (2021), 174–178. https://doi.org/10.1016/j.jjcc.2020.08.004 doi: 10.1016/j.jjcc.2020.08.004
|
| [28] |
M. Friendly, Corrgrams: Exploratory displays for correlation matrices, Am. Stat., 56 (2002), 316–324. https://doi.org/10.1198/000313002533 doi: 10.1198/000313002533
|
| [29] |
A. L. Dailey, Metabolomic bioinformatic analysis, Methods Mol. Biol., 1606 (2017), 341–352. https://doi.org/10.1007/978-1-4939-6990-6_22 doi: 10.1007/978-1-4939-6990-6_22
|
| [30] |
K. Hu, Become competent within one day in generating boxplots and violin plots for a novice without prior r experience, Methods Protoc., 3 (2020), E64. https://doi.org/10.3390/mps3040064 doi: 10.3390/mps3040064
|
| [31] |
O. Kwon, H. Lee, H. Kong, E. Kwon, J. E. Park, W. Lee, et al., Connectivity map-based drug repositioning of bortezomib to reverse the metastatic effect of GALNT14 in lung cancer, Oncogene, 39 (2020), 4567–4580. https://doi.org/10.1038/s41388-020-1316-2 doi: 10.1038/s41388-020-1316-2
|
| [32] |
F. E. C. M. Peeters, S. J. R. Meex, M. R. Dweck, E. Aikawa, H. J. G. M. Crijns, L. J. Schurgers, et al., Calcific aortic valve stenosis: hard disease in the heart: A biomolecular approach towards diagnosis and treatment, Eur. Heart J., 39 (2018), 2618–2624. https://doi.org/10.1093/eurheartj/ehx653 doi: 10.1093/eurheartj/ehx653
|
| [33] |
K. I. Cho, I. Sakuma, I. Sohn, S. Jo, K. K. Koh, Inflammatory and metabolic mechanisms underlying the calcific aortic valve disease, Atherosclerosis, 277 (2018), 60–65. https://doi.org/10.1016/j.atherosclerosis.2018.08.029 doi: 10.1016/j.atherosclerosis.2018.08.029
|
| [34] |
M. Erdoğan, S. Öztürk, B. Kardeşler, M. Yiğitbaşı, H. A. Kasapkara, S. Baştuğ, et al., The relationship between calcific severe aortic stenosis and systemic immune-inflammation index, Echocardiography, 38 (2021), 737–744. https://doi.org/10.1111/echo.15044 doi: 10.1111/echo.15044
|
| [35] |
A. G. Kutikhin, A. E. Yuzhalin, E. B. Brusina, A. V. Ponasenko, A. S. Golovkin, O. L. Barbarash, et al., Genetic predisposition to calcific aortic stenosis and mitral annular calcification, Mol. Biol. Rep., 41 (2014), 5645–5663. https://doi.org/10.1007/s11033-014-3434-9 doi: 10.1007/s11033-014-3434-9
|
| [36] |
M. Azova, K. Timizheva, A. A. Aissa, M. Blagonravov, O. Gigani, A. Aghajanyan, et al., Gene polymorphisms of the renin-angiotensin-aldosterone system as risk factors for the development of in-stent restenosis in patients with stable coronary artery disease, Biomolecules, 11 (2021), 763. https://doi.org/10.3390/biom11050763 doi: 10.3390/biom11050763
|
| [37] |
B. Saravi, Z. Li, C. N. Lang, B. Schmid, F. K. Lang, S. Grad, et al., The tissue renin-angiotensin system and its role in the pathogenesis of major human diseases: Quo vadis?, Cells, 10 (2021), 650. https://doi.org/10.3390/cells10030650 doi: 10.3390/cells10030650
|
| [38] |
P. J. Pussinen, M. Jauhiainen, J. Metso, L. E. Pyle, Y. L. Marcel, N. H. Fidge, et al., Binding of phospholipid transfer protein (PLTP) to apolipoproteins A-I and A-II: location of a PLTP binding domain in the amino terminal region of apoA-I, J. Lipid Res., 39 (1998), 152–161. https://doi.org/10.1016/S0022-2275(20)34211-5 doi: 10.1016/S0022-2275(20)34211-5
|
| [39] |
J. I. Lommi, P. T. Kovanen, M. Jauhiainen, M. Lee-Rueckert, M. Kupari, S. Helske, High-density lipoproteins (HDL) are present in stenotic aortic valves and may interfere with the mechanisms of valvular calcification, Atherosclerosis, 219 (2011), 538–544. https://doi.org/10.1016/j.atherosclerosis.2011.08.027 doi: 10.1016/j.atherosclerosis.2011.08.027
|
| [40] |
M. A. Heuschkel, N. T. Skenteris, J. D. Hutcheson, D. D. Valk, J. Bremer, P. Goody, et al., Integrative multi-omics analysis in calcific aortic valve disease reveals a link to the formation of amyloid-like deposits, Cells, 9 (2020), E2164. https://doi.org/10.3390/cells9102164 doi: 10.3390/cells9102164
|
| [41] |
F. Schlotter, R. C. C. Freitas, M. A. Rogers, M. C. Blaser, P. Wu, H. Higashi, et al., ApoC-III is a novel inducer of calcification in human aortic valves, J. Biol. Chem., 296 (2020), 100193. https://doi.org/10.1074/jbc.RA120.015700 doi: 10.1074/jbc.RA120.015700
|
| [42] |
K. Zhang, J. Zheng, Y. Chen, J. Dong, Z. Li, Y. Chiang, et al., Inducible phospholipid transfer protein deficiency ameliorates atherosclerosis, Atherosclerosis, 324 (2021), 9–17. https://doi.org/10.1016/j.atherosclerosis.2021.03.011 doi: 10.1016/j.atherosclerosis.2021.03.011
|
| [43] |
N. Biswas, E. Curello, D. T. O'Connor, S. K. Mahata, Chromogranin/secretogranin proteins in murine heart: myocardial production of chromogranin A fragment catestatin (Chga364–384), Cell Tissue Res., 342 (2010), 353–361. https://doi.org/10.1007/s00441-010-1059-4 doi: 10.1007/s00441-010-1059-4
|
| [44] |
M. Liu, M. Luo, H. Sun, B. Ni, Y. Shao, Integrated bioinformatics analysis predicts the key genes involved in aortic valve calcification: From hemodynamic changes to extracellular remodeling, Tohoku J. Exp. Med., 243 (2017), 263–273. https://doi.org/10.1620/tjem.243.263 doi: 10.1620/tjem.243.263
|
 mbe-19-04-174-Supplementary Figure 1.jpg mbe-19-04-174-Supplementary Figure 1.jpg

|

|






Figures(7)

Chenyang Jiang, Weidong Jiang. AGTR1, PLTP, and SCG2 associated with immune genes and immune cell infiltration in calcific aortic valve stenosis: analysis from integrated bioinformatics and machine learning[J]. Mathematical Biosciences and Engineering, 2022, 19(4): 3787-3802. doi: 10.3934/mbe.2022174







 DownLoad:
DownLoad: