Trace norm regularization is a widely used approach for learning low rank matrices. A standard optimization strategy is based on formulating the problem as one of low rank matrix factorization which, however, leads to a non-convex problem. In practice this approach works well, and it is often computationally faster than standard convex solvers such as proximal gradient methods. Nevertheless, it is not guaranteed to converge to a global optimum, and the optimization can be trapped at poor stationary points. In this paper we show that it is possible to characterize all critical points of the non-convex problem. This allows us to provide an efficient criterion to determine whether a critical point is also a global minimizer. Our analysis suggests an iterative meta-algorithm that dynamically expands the parameter space and allows the optimization to escape any non-global critical point, thereby converging to a global minimizer. The algorithm can be applied to problems such as matrix completion or multitask learning, and our analysis holds for any random initialization of the factor matrices. Finally, we confirm the good performance of the algorithm on synthetic and real datasets.
Citation: Carlo Ciliberto, Massimiliano Pontil, Dimitrios Stamos. Reexamining low rank matrix factorization for trace norm regularization[J]. Mathematics in Engineering, 2023, 5(3): 1-22. doi: 10.3934/mine.2023053
Trace norm regularization is a widely used approach for learning low rank matrices. A standard optimization strategy is based on formulating the problem as one of low rank matrix factorization which, however, leads to a non-convex problem. In practice this approach works well, and it is often computationally faster than standard convex solvers such as proximal gradient methods. Nevertheless, it is not guaranteed to converge to a global optimum, and the optimization can be trapped at poor stationary points. In this paper we show that it is possible to characterize all critical points of the non-convex problem. This allows us to provide an efficient criterion to determine whether a critical point is also a global minimizer. Our analysis suggests an iterative meta-algorithm that dynamically expands the parameter space and allows the optimization to escape any non-global critical point, thereby converging to a global minimizer. The algorithm can be applied to problems such as matrix completion or multitask learning, and our analysis holds for any random initialization of the factor matrices. Finally, we confirm the good performance of the algorithm on synthetic and real datasets.

| [1] | J. D. M. Rennie, N. Srebro, Fast maximum margin matrix factorization for collaborative prediction, In: ICML '05: Proceedings of the 22nd international conference on machine learning, 2005,713–719. http://doi.org/10.1145/1102351.1102441 |
| [2] |
Y. Koren, R. Bell, C. Volinsky, Matrix factorization techniques for recommender systems, Computer, 42 (2009), 30–37. http://doi.org/10.1109/MC.2009.263 doi: 10.1109/MC.2009.263

|
| [3] |
A. Argyriou, T. Evgeniou, M. Pontil, Convex multi-task feature learning, Mach. Learn., 73 (2008), 243–272. http://doi.org/10.1007/s10994-007-5040-8 doi: 10.1007/s10994-007-5040-8
|
| [4] | Z. Harchaoui, M. Douze, M. Paulin, M. Dudik, J. Malick, Large-scale image classification with trace-norm regularization, In: 2012 IEEE conference on computer vision and pattern recognition, 2012, 3386–3393. http://doi.org/10.1109/CVPR.2012.6248078 |
| [5] | Y. Amit, M. Fink, N. Srebro, S. Ullman, Uncovering shared structures in multiclass classification, In: ICML '07: Proceedings of the 24th international conference on machine learning, 2007, 17–24. http://doi.org/10.1145/1273496.1273499 |
| [6] | F. R. Bach, Consistency of trace norm minimization, The Journal of Machine Learning Research, 9 (2008), 1019–1048. |
| [7] | N. Srebro, J. D. M. Rennie, T. S. Jaakkola, Maximum-margin matrix factorization, In: NIPS'04: Proceedings of the 17th international conference on neural information processing systems, 2004, 1329–1336. |
| [8] | H. H. Bauschke, P. L. Combettes, Convex analysis and monotone operator theory in Hilbert spaces, New York, NY: Springer, 2011. http://doi.org/10.1007/978-1-4419-9467-7 |
| [9] | T. Hastie, R. Mazumder, J. D. Lee, R. Zadeh, Matrix completion and low-rank SVD via fast alternating least squares, The Journal of Machine Learning Research, 16 (2015), 3367–3402. |
| [10] | R. Ge, J. D. Lee, T. Ma, Matrix completion has no spurious local minimum, In: Advances in neural information processing systems 29, 2016, 2973–2981. |
| [11] | S. Bhojanapalli, B. Neyshabur, N. Srebro, Global optimality of local search for low rank matrix recovery, In: NIPS'16: Proceedings of the 30th international conference on neural information processing systems, 2016, 3880–3888. |
| [12] | C.-J. Hsieh, P. Olsen, Nuclear norm minimization via active subspace selection, In: ICML'14: Proceedings of the 31st international conference on international conference on machine learning, 2014,575–583. |
| [13] | J. Abernethy, F. Bach, T. Evgeniou, J.-P. Vert, A new approach to collaborative filtering: operator estimation with spectral regularization, The Journal of Machine Learning Research, 10 (2009), 803–826. |
| [14] |
A. Beck, M. Teboulle, A fast iterative shrinkage-thresholding algorithm for linear inverse problems, SIAM J. Imaging Sci., 2 (2009), 183–202. http://doi.org/10.1137/080716542 doi: 10.1137/080716542
|
| [15] | M. Dudik, Z. Harchaoui, J. Malick, Lifted coordinate descent for learning with trace-norm regularization, In: Proceedings of the fifteenth international conference on artificial intelligence and statistics, 2012,327–336. |
| [16] | G. J. O. Jameson, Summing and nuclear norms in Banach space theory, Cambridge University Press, 1987. http://doi.org/10.1017/CBO9780511569166 |
| [17] | D. P. Bertsekas, Nonlinear programming, Athena scientific Belmont, 1999. |
| [18] | J. D. Lee, M. Simchowitz, M. I. Jordan, B. Recht, Gradient descent only converges to minimizers, In: 29th Annual conference on learning theory, 2016, 1246–1257. |
| [19] | B. D. Haeffele, R. Vidal, Global optimality in tensor factorization, deep learning, and beyond, 2015, arXiv: 1506.07540. |
| [20] | D. P. Woodruff, Sketching as a tool for numerical linear algebra, Now Foundations and Trends, 2014. http://doi.org/10.1561/0400000060 |
| [21] |
K. G. Murty, S. N. Kabadi, Some NP-complete problems in quadratic and nonlinear programming, Mathematical Programming, 39 (1987), 117–129. http://doi.org/10.1007/BF02592948 doi: 10.1007/BF02592948
|
| [22] | S. Boyd, L. Vandenberghe, Convex optimization, Cambridge University Press, 2004. |
| [23] |
H. Attouch, J. Bolte, P. Redont, A. Soubeyran, Proximal alternating minimization and projection methods for nonconvex problems: An approach based on the kurdyka-ƚojasiewicz inequality, Math. Oper. Res., 35 (2010), 438–457. http://doi.org/10.1287/moor.1100.0449 doi: 10.1287/moor.1100.0449
|
| [24] |
J. Bolte, A. Daniilidis, O. Ley, L. Mazet, Characterizations of ƚojasiewicz inequalities: subgradient flows, talweg, convexity, Trans. Amer. Math. Soc., 362 (2010), 3319–3363. http://doi.org/10.1090/S0002-9947-09-05048-X doi: 10.1090/S0002-9947-09-05048-X
|
| [25] |
H. Attouch, J. Bolte, On the convergence of the proximal algorithm for nonsmooth functions involving analytic features, Mathematical Programming, 116 (2009), 5–16. http://doi.org/10.1007/s10107-007-0133-5 doi: 10.1007/s10107-007-0133-5
|
| [26] |
F. M. Harper, J. A. Konstan, The movielens datasets: history and context, ACM Trans. Interact. Intel. Syst., 5 (2016), 1–19. http://doi.org/10.1145/2827872 doi: 10.1145/2827872
|
| [27] | A. S. Lewis, The convex analysis of unitarily invariant matrix functions, J. Convex Anal., 2 (1995), 173–183. |
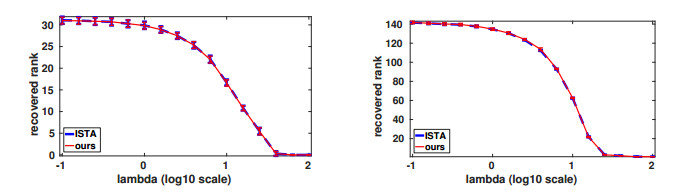
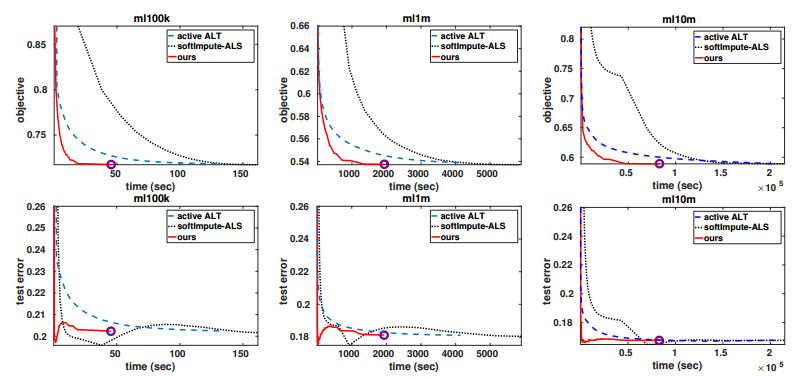
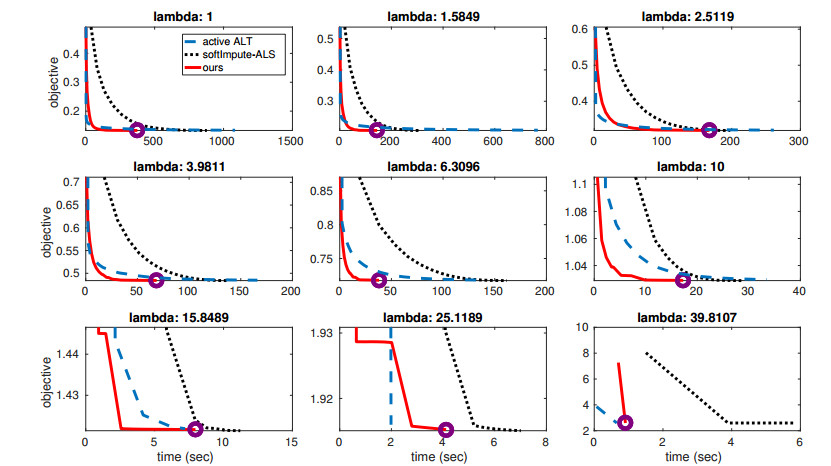

Figures(4) / Tables(1)

Carlo Ciliberto, Massimiliano Pontil, Dimitrios Stamos. Reexamining low rank matrix factorization for trace norm regularization[J]. Mathematics in Engineering, 2023, 5(3): 1-22. doi: 10.3934/mine.2023053







 DownLoad:
DownLoad: