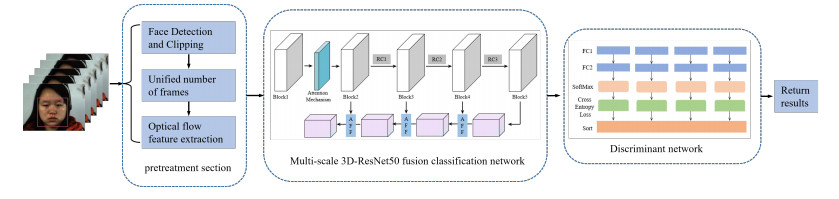
In demanding application scenarios such as clinical psychotherapy and criminal interrogation, the accurate recognition of micro-expressions is of utmost importance but poses significant challenges. One of the main difficulties lies in effectively capturing weak and fleeting facial features and improving recognition performance. To address this fundamental issue, this paper proposed a novel architecture based on a multi-scale 3D residual convolutional neural network. The algorithm leveraged a deep 3D-ResNet50 as the skeleton model and utilized the micro-expression optical flow feature map as the input for the network model. Drawing upon the complex spatial and temporal features inherent in micro-expressions, the network incorporated multi-scale convolutional modules of varying sizes to integrate both global and local information. Furthermore, an attention mechanism feature fusion module was introduced to enhance the model's contextual awareness. Finally, to optimize the model's prediction of the optimal solution, a discriminative network structure with multiple output channels was constructed. The algorithm's performance was evaluated using the public datasets SMIC, SAMM, and CASME Ⅱ. The experimental results demonstrated that the proposed algorithm achieves recognition accuracies of 74.6, 84.77 and 91.35% on these datasets, respectively. This substantial improvement in efficiency compared to existing mainstream methods for extracting micro-expression subtle features effectively enhanced micro-expression recognition performance and increased the accuracy of high-precision micro-expression recognition. Consequently, this paper served as an important reference for researchers working on high-precision micro-expression recognition.
Citation: Hongmei Jin, Ning He, Zhanli Li, Pengcheng Yang. Micro-expression recognition based on multi-scale 3D residual convolutional neural network[J]. Mathematical Biosciences and Engineering, 2024, 21(4): 5007-5031. doi: 10.3934/mbe.2024221
In demanding application scenarios such as clinical psychotherapy and criminal interrogation, the accurate recognition of micro-expressions is of utmost importance but poses significant challenges. One of the main difficulties lies in effectively capturing weak and fleeting facial features and improving recognition performance. To address this fundamental issue, this paper proposed a novel architecture based on a multi-scale 3D residual convolutional neural network. The algorithm leveraged a deep 3D-ResNet50 as the skeleton model and utilized the micro-expression optical flow feature map as the input for the network model. Drawing upon the complex spatial and temporal features inherent in micro-expressions, the network incorporated multi-scale convolutional modules of varying sizes to integrate both global and local information. Furthermore, an attention mechanism feature fusion module was introduced to enhance the model's contextual awareness. Finally, to optimize the model's prediction of the optimal solution, a discriminative network structure with multiple output channels was constructed. The algorithm's performance was evaluated using the public datasets SMIC, SAMM, and CASME Ⅱ. The experimental results demonstrated that the proposed algorithm achieves recognition accuracies of 74.6, 84.77 and 91.35% on these datasets, respectively. This substantial improvement in efficiency compared to existing mainstream methods for extracting micro-expression subtle features effectively enhanced micro-expression recognition performance and increased the accuracy of high-precision micro-expression recognition. Consequently, this paper served as an important reference for researchers working on high-precision micro-expression recognition.

| [1] |
X. Shen, Q. Wu, X. Fu, Effects of the duration of expressions on the recognition of microexpressions, J. Zhejiang Univ. Sci. B, 13 (2012), 221–230. https://doi.org/10.1631/jzus.B1100063 doi: 10.1631/jzus.B1100063

|
| [2] |
C. Zhu, X. Chen, J. Zhang, Z. Liu, Z. Tang, Y. Xu, et al., Comparison of ecological micro-expression recognition in patients with depression and healthy individuals, Front. Behav. Neurosci., 11 (2017), 199. https://doi.org/10.3389/fnbeh.2017.00199 doi: 10.3389/fnbeh.2017.00199
|
| [3] |
X. Ben, Y. Ren, J. Zhang, S. J. Wang, K. Kpalma, W. Meng, et al., Video-based facial micro-expression analysis: A survey of datasets, features and algorithms, IEEE Trans. Pattern Anal. Mach. Intell., 44 (2021), 5826–5846. https://doi.org/10.1109/TPAMI.2021.3067464 doi: 10.1109/TPAMI.2021.3067464
|
| [4] |
T. Ojala, M. Pietikainen, T. Maenpaa, Multiresolution gray-scale and rotation invariant texture classification with local binary patterns, IEEE Trans. Pattern Anal. Mach. Intell., 24 (2002), 971–987. https://doi.org/10.1109/TPAMI.2002.1017623 doi: 10.1109/TPAMI.2002.1017623
|
| [5] |
G. Zhao, M. Pietikainen, Dynamic texture recognition using local binary patterns with an application to facial expressions, IEEE Trans. Pattern Anal. Mach. Intell., 29 (2007), 915–928. https://doi.org/10.1109/TPAMI.2007.1110 doi: 10.1109/TPAMI.2007.1110
|
| [6] | Y. Wang, J. See, R. C. W. Phan, Y. H. Oh, Lbp with six intersection points: Reducing redundant information in lbp-top for micro-expression recognition, in Computer Vision–ACCV 2014, (2015), 525–537. https://doi.org/10.1007/978-3-319-16865-4_34 |
| [7] | T. Pfister, X. Li, G. Zhao, M. Pietikäinen, Recognising spontaneous facial micro-expressions, in 2011 International Conference on Computer Vision, (2011), 1449–1456. https://doi.org/10.1109/ICCV.2011.6126401 |
| [8] | X. Li, T. Pfister, X. Huang, G. Zhao, M. Pietikäinen, A spontaneous micro-expression database: Inducement, collection and baseline, in 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), (2013), 1–6. https://doi.org/10.1109/FG.2013.6553717 |
| [9] |
Y. S. Gan, S. T. Liong, W. C. Yau, Y. C. Huang, L. k. Tan, OFF-ApexNet on micro-expression recognition system, Signal Process.-Image Commun., 74 (2019), 129–139. https://doi.org/10.1016/j.image.2019.02.005 doi: 10.1016/j.image.2019.02.005
|
| [10] | H. Q. Khor, J. See, R. C. W. Phan, W. Lin, Enriched long-term recurrent convolutional network for facial micro-expression recognition, in 2018 13th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2018), (2018), 667–674. https://doi.org/10.1109/FG.2018.00105 |
| [11] |
X. Ben, Y. Ren, J. Zhang, S. J. Wang, K. Kpalma, W. Meng, et al., Video-Based Facial Micro-Expression Analysis: A Survey of Datasets, Features and Algorithms, IEEE Trans. Pattern Anal. Mach. Intell., 44 (2021), 5826–5846. https://doi.org/10.1109/TPAMI.2021.3067464 doi: 10.1109/TPAMI.2021.3067464
|
| [12] |
J. Li, Z. Dong, S. Lu, S. J. Wang, W. J. Yan, Y. Ma, et al., CAS(ME)3: A Third Generation Facial Spontaneous Micro-Expression Database With Depth Information and High Ecological Validity, IEEE Trans. Pattern Anal. Mach. Intell., 45 (2022), 2782–2800. https://doi.org/10.1109/TPAMI.2022.3174895 doi: 10.1109/TPAMI.2022.3174895
|
| [13] |
X. Li, S. Cheng, Y. Li, M. Behzad, J. Shen, S. Zafeiriou, et al., 4DME: A spontaneous 4D micro-expression dataset with multimodalities, IEEE Trans. Affect. Comput., 14 (2022), 3031–3047. https://doi.org/10.1109/TAFFC.2022.3182342 doi: 10.1109/TAFFC.2022.3182342
|
| [14] |
S. Liu, Y. Ren, L. Li, X. Sun, Y. Song, C. C. Hung, Micro-expression recognition based on SqueezeNet and C3D, Multimedia Syst., 28 (2022), 2227–2236. https://doi.org/10.1007/s00530-022-00949-z doi: 10.1007/s00530-022-00949-z
|
| [15] |
S. Zhao, H. Tang, S. Liu, Y. Zhang, H. Wang, T. Xu, et al., ME-PLAN: A deep prototypical learning with local attention network for dynamic micro-expression recognition, Neural Netw., 153 (2022), 427–443. https://doi.org/10.1016/j.neunet.2022.06.024 doi: 10.1016/j.neunet.2022.06.024
|
| [16] |
X. Huang, G. Zhao, X. Hong, W. Zheng, M. Pietikäinen, Spontaneous facial micro-expression analysis using Spatiotemporal Completed Local Quantized Patterns, Neurocomputing, 175 (2016), 564–578. https://doi.org/10.1016/j.neucom.2015.10.096 doi: 10.1016/j.neucom.2015.10.096
|
| [17] |
X. Huang, S. J. Wang, X. Liu, G. Zhao, X. Feng, M. Pietikäinen, Discriminative Spatiotemporal Local Binary Pattern with Revisited Integral Projection for Spontaneous Facial Micro-Expression Recognition, IEEE Trans. Affect. Comput., 10 (2017), 32–47. https://doi.org/10.1109/TAFFC.2017.2713359 doi: 10.1109/TAFFC.2017.2713359
|
| [18] |
Y. Li, X. Huang, G. Zhao, Joint Local and Global Information Learning With Single Apex Frame Detection for Micro-Expression Recognition, IEEE Trans. Image Process., 30 (2020), 249–263. https://doi.org/10.1109/TIP.2020.3035042 doi: 10.1109/TIP.2020.3035042
|
| [19] |
Y. J. Liu, B. J. Li, Y. K. Lai, Sparse mdmo: Learning a discriminative feature for spontaneous micro-expression recognition, IEEE Transactions on Affective computing, 12 (2021), 254–261. https://doi.org/10.1109/TAFFC.2018.2854166 doi: 10.1109/TAFFC.2018.2854166
|
| [20] |
S. T. Liong, J. See, K. S. Wong, R. C. W. Phan, Less is more: Micro-expression recognition from video using apex frame, Signal Process. Image Commun., 62 (2018), 82–92. https://doi.org/10.1016/j.image.2017.11.006 doi: 10.1016/j.image.2017.11.006
|
| [21] |
R. Ni, B. Yang, X. Zhou, S. Song, X. Liu, Diverse local facial behaviors learning from enhanced expression flow for microexpression recognition, Knowl.-Based Syst., 275 (2023), 110729. https://doi.org/10.1016/j.knosys.2023.110729 doi: 10.1016/j.knosys.2023.110729
|
| [22] | X. Li, J. Yu, S. Zhan, Spontaneous facial micro-expression detection based on deep learning, in 2016 IEEE 13th International Conference on Signal Processing (ICSP), (2016), 1130–1134. https://doi.org/10.1109/ICSP.2016.7878004 |
| [23] | R. Chaudhry, A. Ravichandran, G. Hager, R. Vidal, Histograms of oriented optical flow and binet-cauchy kernels on nonlinear dynamical systems for the recognition of human actions, in 2009 IEEE Conference on Computer Vision and Pattern Recognition, (2009), 1932–1939. https://doi.org/10.1109/CVPR.2009.5206821 |
| [24] |
L. Zhou, Q. Mao, X. Huang, F. Zhang, Z. Zhang, Feature refinement: An expression-specific feature learning and fusion method for micro-expression recognition, Pattern Recogn., 122 (2022), 108275. https://doi.org/10.1016/j.patcog.2021.108275 doi: 10.1016/j.patcog.2021.108275
|
| [25] | S. T. Liong, Y. S. Gan, J. See, H. Q. Khor, Y. C. Huang, Shallow triple stream three-dimensional CNN (STSTNet) for micro-expression recognition, in 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), (2019), 1–5. https://doi.org/10.1109/FG.2019.8756567 |
| [26] | J. Li, S. Zhang, T. Huang, Shallow Triple Stream Three-dimensional CNN (STSTNet) for Micro-expression Recognition, Computer Vision and Pattern Recognition, (2018), 8618–-8625. https://doi.org/10.1109/FG.2019.8756567 |
| [27] |
J. Li, T. Wang, S. J. Wang, Facial micro-expression recognition based on deep local-holistic network, Appl. Sci., 12 (2022), 4643. https://doi.org/10.3390/app12094643 doi: 10.3390/app12094643
|
| [28] | N. Van Quang, J. Chun, T. Tokuyama, CapsuleNet for micro-expression recognition, in 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), (2019), 1–7. https://doi.org/10.1109/FG.2019.8756544 |
| [29] |
Z. Xia, X. Hong, X. Gao, X. Feng, G. Zhao, Spatiotemporal recurrent convolutional networks for recognizing spontaneous micro-expressions, IEEE Trans. Multimedia, 22 (2019), 626–640. https://doi.org/10.1109/TMM.2019.2931351 doi: 10.1109/TMM.2019.2931351
|
| [30] |
L. Zhang, X. Hong, O. Arandjelović, G. Zhao, Short and long range relation based spatio-temporal transformer for micro-expression recognition, IEEE Trans. Affect. Comput., 13 (2022), 1973–1985. https://doi.org/10.1109/TAFFC.2022.3213509 doi: 10.1109/TAFFC.2022.3213509
|
| [31] | Y. Su, J. Zhang, J. Liu, G. Zhai, Key facial components guided micro-expression recognition based on first & second-order motion, in 2021 IEEE International Conference on Multimedia and Expo (ICME), (2021), 1–6. https://doi.org/10.1109/ICME51207.2021.9428407 |
| [32] | V. R. Gajjala, S. P. T. Reddy, S. Mukherjee, S. R. Dubey, MERANet: Facial micro-expression recognition using 3D residual attention network, in Proceedings of the twelfth Indian conference on computer vision, graphics and image processing, (2021), 1–10. https://doi.org/10.1145/3490035.3490260 |
| [33] | Z. Zhang, Z. Hu, W. Deng, C. Fan, T. Lv, Y. Ding, DINet: Deformation inpainting network for realistic face visually dubbing on high resolution video, preprint, arXiv: 2303.03988. |
| [34] |
H. Zhou, S. Huang, J. Li, S. J. Wang, Dual-ATME: Dual-branch attention network for micro-expression recognition, Entropy, 25 (2023), 460. https://doi.org/10.3390/e25030460 doi: 10.3390/e25030460
|
| [35] | V. Kazemi, J. Sullivan, One Millisecond Face Alignment with an Ensemble of Regression Trees, in 2014 IEEE Conference on Computer Vision and Pattern Recognition, (2014), 1867–1874. https://doi.org/10.1109/CVPR.2014.241 |










Figures(11) / Tables(1)

Hongmei Jin, Ning He, Zhanli Li, Pengcheng Yang. Micro-expression recognition based on multi-scale 3D residual convolutional neural network[J]. Mathematical Biosciences and Engineering, 2024, 21(4): 5007-5031. doi: 10.3934/mbe.2024221







 DownLoad:
DownLoad: