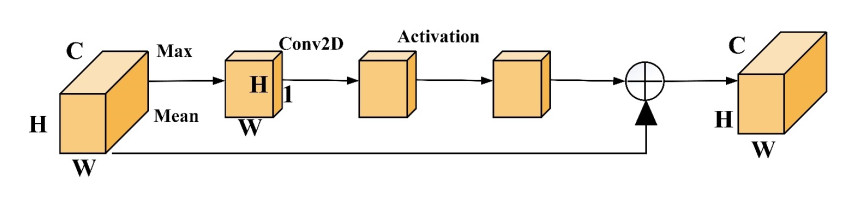
To solve the problem of missing data features using a deep convolutional neural network (DCNN), this paper proposes an improved gesture recognition method. The method first extracts the time-frequency spectrogram of surface electromyography (sEMG) using the continuous wavelet transform. Then, the Spatial Attention Module (SAM) is introduced to construct the DCNN-SAM model. The residual module is embedded to improve the feature representation of relevant regions, and reduces the problem of missing features. Finally, experiments with 10 different gestures are done for verification. The results validate that the recognition accuracy of the improved method is 96.1%. Compared with the DCNN, the accuracy is improved by about 6 percentage points.
Citation: Xiaoguang Liu, Mingjin Zhang, Jiawei Wang, Xiaodong Wang, Tie Liang, Jun Li, Peng Xiong, Xiuling Liu. Gesture recognition of continuous wavelet transform and deep convolution attention network[J]. Mathematical Biosciences and Engineering, 2023, 20(6): 11139-11154. doi: 10.3934/mbe.2023493
To solve the problem of missing data features using a deep convolutional neural network (DCNN), this paper proposes an improved gesture recognition method. The method first extracts the time-frequency spectrogram of surface electromyography (sEMG) using the continuous wavelet transform. Then, the Spatial Attention Module (SAM) is introduced to construct the DCNN-SAM model. The residual module is embedded to improve the feature representation of relevant regions, and reduces the problem of missing features. Finally, experiments with 10 different gestures are done for verification. The results validate that the recognition accuracy of the improved method is 96.1%. Compared with the DCNN, the accuracy is improved by about 6 percentage points.

| [1] | X. Jiang, Y. H. Li, K. Zou, X. D. Yuan, A multi-channel correlation feature gesture recognition method for electromyographic signals, Comput. Eng. Appl., 2023 (2023), 1–9. |
| [2] | L. Liu, H. Y. Pu, LSTM-based multi-dimensional feature gesture recognition in real time, Comput. Sci., 48 (2021), 328–333. |
| [3] |
Z. Zhu, X. He, G. Qi, Y. Li, B. Cong, Y. Liu, Brain tumor segmentation based on the fusion of deep semantics and edge information in multimodal MRI, Inf. Fusion , 91 (2023), 376–387. https://doi.org/10.1016/j.inffus.2022.10.022 doi: 10.1016/j.inffus.2022.10.022

|
| [4] |
N. Duan, L. Z. Liu, X. J. Yu, Q. Li, S. C. Yeh, Classification of multichannel surface-electromyography signals based on convolutional neural networks, J. Ind. Inf. Integr., 15 (2019), 201–206. https://doi.org/10.1016/j.jii.2018.09.001 doi: 10.1016/j.jii.2018.09.001
|
| [5] | F. Milletari, N. Navab, S. A. Ahmadi, V-net: Fully convolutional neural networks for volumetric medical image segmentation, in 2016 Fourth International Conference on 3D Vision (3DV), IEEE, (2016), 565–571. https://doi.org/10.1109/3DV.2016.79 |
| [6] |
L. M. Luo, Z. Y. Xu, X. H. Xie, L. Li, Convolutional neural network-based gesture recognition for surface EMG signals in Chinese, Comput. Program. Skills Maint., 2021 (2021), 137–138+163. https://doi.org/10.16184/j.cnki.comprg.2021.01.049 doi: 10.16184/j.cnki.comprg.2021.01.049
|
| [7] |
V. Shanmuganathan, H. R. Yesudhas, M. S. Khan, M. Khari, A. H. Gandomi, R-CNN and wavelet feature extraction for hand gesture recognition with EMG signals, Neural Comput. Appl., 32 (2020), 16723–16736. https://doi.org/10.1007/s00521-020-05349-w doi: 10.1007/s00521-020-05349-w
|
| [8] | L. K. Xu, K. Q. Zhang, Z. H. Xu, G. Yang, Convolutional neural network human gesture recognition algorithm based on energy kernel phase map of surface EMG signals, J. Biomed. Eng., 38 (2021), 621–629. |
| [9] |
M. A. Ozdemir, D. H. Kisa, O. Guren, A. Akan, Hand gesture classification using time–frequency images and transfer learning based on cnn, Biomed. Signal Process. Control, 77 (2022), 103787. https://doi.org/10.1016/j.bspc.2022.103787 doi: 10.1016/j.bspc.2022.103787
|
| [10] | K. Feng, S. Dong, D. B. Liu, Surface myoelectric signal gesture recognition based on empirical modal decomposition-wavelet packet transform, Chin. J. Med. Phys., 38 (2021), 461–467. |
| [11] |
X. Xi, W. Jiang, X. Hua, H. Wang, C. Yang, Y. B. Zhao, et al., Simultaneous and continuous estimation of joint angles based on surface electromyography state-space model, IEEE Sens. J., 21 (2021), 8089–8099. https://doi.org/10.1109/JSEN.2020.3048983 doi: 10.1109/JSEN.2020.3048983
|
| [12] |
Y. H. Li, X. Jiang, K. Zou, X. D. Yuan, A multi-stream convolutional myoelectric gesture recognition network with fused attention mechanism, Comput. Appl. Res., 38 (2021), 3258–3263. https://doi.org/10.19734/j.issn.1001-3695.2021.04.0100 doi: 10.19734/j.issn.1001-3695.2021.04.0100
|
| [13] |
L. H. Shi, Research on dynamic gesture recognition based on attentional convolutional neural network in Chinese, Opt. Technol., 46 (2020), 750–756. https://doi.org/10.13741/j.cnki.11-1879/o4.2020.06.019 doi: 10.13741/j.cnki.11-1879/o4.2020.06.019
|
| [14] | C. Yan, P. A. Mu, Research on static gesture recognition in complex context, Software Guide, 21 (2022), 171–176. |
| [15] | L. K. Xu, K. Q. Zhang, Z. H. Xu, G. K. Yang, Human gesture recognition algorithm based on convolution neural network based on energy kernel phase diagram of surface EMG signal, J. Biomed. Eng., 38 (2021), 621–629. |
| [16] |
W. Wei, Y. Wong, Y. Du, Y. Hu, M. Kankanhalli, W. Geng, A Multi-stream convolutional neural network for sEMG-based gesture recognition in muscle-computer interface, Pattern Recognit. Lett., 119 (2017), 131–138. https://doi.org/10.1016/j.patrec.2017.12.005 doi: 10.1016/j.patrec.2017.12.005
|
| [17] |
H. X. Cheng, K. Cheng, L. Cheng, Z. Q. Jiang, A gesture recognition method based on residual fusion biflow graph convolutional network in Chinese, Electron. Meas. Technol., 45 (2022), 20–24. https://doi.org/10.19651/j.cnki.emt.2108617 doi: 10.19651/j.cnki.emt.2108617
|
| [18] |
C. Liu, X. F. Feng, A gesture recognition method based on wireless signal and improved TCN in Chinese, Comput. Eng. Des., 43 (2022), 2317–2324. https://doi.org/10.16208/j.issn1000-7024.2022.08.029 doi: 10.16208/j.issn1000-7024.2022.08.029
|
| [19] |
C. Tepe, M. Erdim, Classification of surface electromyography and gyroscopic signals of finger gestures acquired by Myo armband using machine learning methods, Biomed. Signal Process. Control, 75 (2022), 103588. https://doi.org/10.1016/j.bspc.2022.103588 doi: 10.1016/j.bspc.2022.103588
|
| [20] |
X. J. Zhang, C. Y. Li, A gesture segmentation recognition algorithm based on deep learning multi-feature fusion in Chinese, J. Jinan Univ. (Nat. Sci. Ed.), 36 (2022), 286–291. https://doi.org/10.13349/j.cnki.jdxbn.20220110.001 doi: 10.13349/j.cnki.jdxbn.20220110.001
|
| [21] |
F. Kong, J. Deng, Z. Fan, Gesture recognition system based on ultrasonic FMCW and ConvLSTM model, Measurement, 190 (2022), 110743. https://doi.org/10.1016/j.measurement.2022.110743 doi: 10.1016/j.measurement.2022.110743
|
| [22] |
H. F. Hassan, S. J. Abou-Loukh, I. K. Ibraheem, Teleoperated robotic arm movement using electromyography signal with wearable Myo armband, J. King Saud Univ. Eng. Sci., 32 (2019), 378–387. https://doi.org/10.1016/j.jksues.2019.05.001 doi: 10.1016/j.jksues.2019.05.001
|
| [23] |
J. M. Fajardo, O. Gomez, F. Prieto, EMG hand gesture classification using handcrafted and deep features, Biomed. Signal Process. Control, 63 (2020), 102210. https://doi.org/10.1016/j.bspc.2020.102210 doi: 10.1016/j.bspc.2020.102210
|
| [24] |
C. Tepe, M. C. Demir, The effects of the number of channels and gyroscopic data on the classification performance in EMG data acquired by Myo armband, J. Comput. Sci., 51 (2021), 101348. https://doi.org/10.1016/j.jocs.2021.101348 doi: 10.1016/j.jocs.2021.101348
|
| [25] |
J. O. Pinzón-Arenas, R. Jiménez-Moreno, A. Rubiano, Percentage estimation of muscular activity of the forearm by means of EMG signals based on the gesture recognized using CNN, Sens. Bio-Sens. Res., 29 (2020), 100353. https://doi.org/10.1016/j.sbsr.2020.100353 doi: 10.1016/j.sbsr.2020.100353
|
| [26] |
L. Xu, K. Zhang, G. Yang, J. Chu, Gesture recognition using dual-stream CNN based on fusion of sEMG energy kernel phase portrait and IMU amplitude image, Biomed. Signal Process. Control, 73 (2022), 103364. https://doi.org/10.1016/j.bspc.2021.103364 doi: 10.1016/j.bspc.2021.103364
|
| [27] | X. Z. Wang, P. Yue, J. W. Wang, Z. Li, Q. H. Tian, Wavelet transform low-frequency information with Xception network for static gesture recognition, Software Guide, 20 (2021), 12–19. |
| [28] | C. Q. Hu, N. Qu, S. Zhang, Z. Jiang, Application of continuous wavelet transform and deep residual shrinkage network with attention mechanism to low-voltage series arc fault detection, Power Grid Technol., 2022 (2022), 1–10. |
| [29] | J. X. Li, L. Shen, C. Cai, R. N. Yang, K. Luo, Improved frequency slicing wavelet transform and convolutional neural network for myoelectric signal recognition of hand gestures, J. Nanchang Univ, 43 (2021), 401–408. |
| [30] |
Y. Jiang, C. Chen, X. Zhang, C. Chen, Y. Zhou, G. Ni, et al., Shoulder muscle activation pattern recognition based on sEMG and machine learning algorithms, Comput. Methods Programs Biomed., 197 (2020), 105721. https://doi.org/10.1016/j.cmpb.2020.105721 doi: 10.1016/j.cmpb.2020.105721
|
| [31] |
Z. C. Hu, Y. T. Zhou, B. J. Shi, H. He, A static gesture recognition algorithm combining attention mechanism and feature fusion in Chinese, Comput. Eng., 48 (2022), 240–246. https://doi.org/10.19678/j.issn.1000-3428.0060912 doi: 10.19678/j.issn.1000-3428.0060912
|











Figures(12) / Tables(4)

Xiaoguang Liu, Mingjin Zhang, Jiawei Wang, Xiaodong Wang, Tie Liang, Jun Li, Peng Xiong, Xiuling Liu. Gesture recognition of continuous wavelet transform and deep convolution attention network[J]. Mathematical Biosciences and Engineering, 2023, 20(6): 11139-11154. doi: 10.3934/mbe.2023493







 DownLoad:
DownLoad: