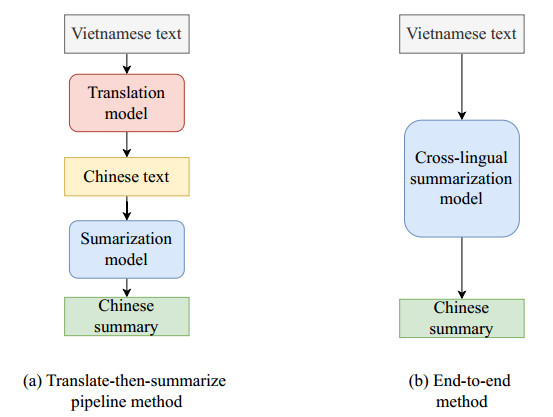
Cross-lingual summarization (CLS) is the task of condensing lengthy source language text into a concise summary in a target language. This presents a dual challenge, demanding both cross-language semantic understanding (i.e., semantic alignment) and effective information compression capabilities. Traditionally, researchers have tackled these challenges using two types of methods: pipeline methods (e.g., translate-then-summarize) and end-to-end methods. The former is intuitive but prone to error propagation, particularly for low-resource languages. The later has shown an impressive performance, due to multilingual pre-trained models (mPTMs). However, mPTMs (e.g., mBART) are primarily trained on resource-rich languages, thereby limiting their semantic alignment capabilities for low-resource languages. To address these issues, this paper integrates the intuitiveness of pipeline methods and the effectiveness of mPTMs, and then proposes a two-stage fine-tuning method for low-resource cross-lingual summarization (TFLCLS). In the first stage, by recognizing the deficiency in the semantic alignment for low-resource languages in mPTMs, a semantic alignment fine-tuning method is employed to enhance the mPTMs' understanding of such languages. In the second stage, while considering that mPTMs are not originally tailored for information compression and CLS demands the model to simultaneously align and compress, an adaptive joint fine-tuning method is introduced. This method further enhances the semantic alignment and information compression abilities of mPTMs that were trained in the first stage. To evaluate the performance of TFLCLS, a low-resource CLS dataset, named Vi2ZhLow, is constructed from scratch; moreover, two additional low-resource CLS datasets, En2ZhLow and Zh2EnLow, are synthesized from widely used large-scale CLS datasets. Experimental results show that TFCLS outperforms state-of-the-art methods by 18.88%, 12.71% and 16.91% in ROUGE-2 on the three datasets, respectively, even when limited with only 5,000 training samples.
Citation: Kaixiong Zhang, Yongbing Zhang, Zhengtao Yu, Yuxin Huang, Kaiwen Tan. A two-stage fine-tuning method for low-resource cross-lingual summarization[J]. Mathematical Biosciences and Engineering, 2024, 21(1): 1125-1143. doi: 10.3934/mbe.2024047
Cross-lingual summarization (CLS) is the task of condensing lengthy source language text into a concise summary in a target language. This presents a dual challenge, demanding both cross-language semantic understanding (i.e., semantic alignment) and effective information compression capabilities. Traditionally, researchers have tackled these challenges using two types of methods: pipeline methods (e.g., translate-then-summarize) and end-to-end methods. The former is intuitive but prone to error propagation, particularly for low-resource languages. The later has shown an impressive performance, due to multilingual pre-trained models (mPTMs). However, mPTMs (e.g., mBART) are primarily trained on resource-rich languages, thereby limiting their semantic alignment capabilities for low-resource languages. To address these issues, this paper integrates the intuitiveness of pipeline methods and the effectiveness of mPTMs, and then proposes a two-stage fine-tuning method for low-resource cross-lingual summarization (TFLCLS). In the first stage, by recognizing the deficiency in the semantic alignment for low-resource languages in mPTMs, a semantic alignment fine-tuning method is employed to enhance the mPTMs' understanding of such languages. In the second stage, while considering that mPTMs are not originally tailored for information compression and CLS demands the model to simultaneously align and compress, an adaptive joint fine-tuning method is introduced. This method further enhances the semantic alignment and information compression abilities of mPTMs that were trained in the first stage. To evaluate the performance of TFLCLS, a low-resource CLS dataset, named Vi2ZhLow, is constructed from scratch; moreover, two additional low-resource CLS datasets, En2ZhLow and Zh2EnLow, are synthesized from widely used large-scale CLS datasets. Experimental results show that TFCLS outperforms state-of-the-art methods by 18.88%, 12.71% and 16.91% in ROUGE-2 on the three datasets, respectively, even when limited with only 5,000 training samples.

| [1] | X. Wan, Using bilingual information for cross-language document summarization, in Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, (2011), 1546–1555. |
| [2] |
J. Zhang, Y. Zhou, C. Zong, Abstractive cross-language summarization via translation model enhanced predicate argument structure fusing, IEEE/ACM Trans. Audio Speech Language Process., 24 (2016), 1842–1853. https://doi.org/10.1109/TASLP.2016.2586608 doi: 10.1109/TASLP.2016.2586608

|
| [3] | X. Wan, H. Li, J. Xiao, Cross-language document summarization based on machine translation quality prediction, in Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, (2010), 917–926. |
| [4] | J. Zhu, Q. Wang, Y. Wang, Y. Zhou, J. Zhang, S. Wang, et al., NCLS: Neural cross-lingual summarization, in Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), (2019), 3054–3064. https://doi.org/10.18653/v1/D19-1302 |
| [5] |
G. Erkan, D. R. Radev, Lexrank: Graph-based lexical centrality as salience in text summarization, J. Artif. Int. Res., 22 (2004), 457–479. https://doi.org/10.1613/jair.1523 doi: 10.1613/jair.1523
|
| [6] | R. Mihalcea, P. Tarau, TextRank: Bringing order into text, in Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, (2004), 404–411. |
| [7] |
J. Zhao, L. Yang, X. Cai, Hettreesum: A heterogeneous tree structure-based extractive summarization model for scientific papers, Expert Syst. Appl., 210 (2022), 118335. https://doi.org/10.1016/j.eswa.2022.118335 doi: 10.1016/j.eswa.2022.118335
|
| [8] | R. Nallapati, B. Zhou, C. dos Santos, Ç. Gulçehre, B. Xiang, Abstractive text summarization using sequence-to-sequence RNNs and beyond, in Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, (2016), 280–290. https://doi.org/10.18653/v1/K16-1028 |
| [9] | U. Khandelwal, K. Clark, D. Jurafsky, L. Kaiser, Sample efficient text summarization using a single pre-trained transformer, preprint, arXiv: 1905.08836. |
| [10] |
Y. Huang, S. Hou, G. Li, Z. Yu, Abstractive summary of public opinion news based on element graph attention, Information, 14. https://doi.org/10.3390/info14020097 doi: 10.3390/info14020097
|
| [11] | J. Zhu, Y. Zhou, J. Zhang, C. Zong, Attend, translate and summarize: An efficient method for neural cross-lingual summarization, in Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, (2020), 1309–1321. https://doi.org/10.18653/v1/2020.acl-main.121 |
| [12] | Y. Qin, G. Neubig, P. Liu, Searching for effective multilingual fine-tuning methods: A case study in summarization, preprint, arXiv: 2212.05740. |
| [13] | J. Wang, F. Meng, T. Zhang, Y. Liang, J. Xu, Z. Li, et al., Understanding translationese in cross-lingual summarization, preprint, arXiv: 2212.07220. |
| [14] | J. Wang, F. Meng, D. Zheng, Y. Liang, Z. Li, J. Qu, et al., Towards unifying multi-lingual and cross-lingual summarization, in Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics, (2023), 15127–15143. https://doi.org/10.18653/v1/2023.acl-long.843 |
| [15] | D. Taunk, S. Sagare, A. Patil, S. Subramanian, M. Gupta, V. Varma, Xwikigen: Cross-lingual summarization for encyclopedic text generation in low resource languages, in Proceedings of the ACM Web Conference, (2023), 1703–1713. https://doi.org/10.1145/3543507.3583405 |
| [16] | Y. Bai, Y. Gao, H. Huang, Cross-lingual abstractive summarization with limited parallel resources, in Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, (2021), 6910–6924. https://doi.org/10.18653/v1/2021.acl-long.538 |
| [17] | T. T. Nguyen, A. T. Luu, Improving neural cross-lingual abstractive summarization via employing optimal transport distance for knowledge distillation, in Proceedings of the AAAI Conference on Artificial Intelligence, 36 2022, 11103–11111. https://doi.org/10.1609/aaai.v36i10.21359 |
| [18] |
Y. Liu, J. Gu, N. Goyal, X. Li, S. Edunov, M. Ghazvininejad, et al., Multilingual denoising pre-training for neural machine translation, Trans. Assoc. Comput. Linguist., 8 (2020), 726–742. https://doi.org/10.1162/tacl_a_00343 doi: 10.1162/tacl_a_00343
|
| [19] | L. Liebel, M. Körner, Auxiliary tasks in multi-task learning, preprint, arXiv: 1805.06334. |
| [20] | J. Zhu, H. Li, T. Liu, Y. Zhou, J. Zhang, C. Zong, MSMO: Multimodal summarization with multimodal output, in Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, (2018), 4154–4164. https://doi.org/10.18653/v1/D18-1448 |
| [21] | C. Y. Lin, ROUGE: A package for automatic evaluation of summaries, in Text Summarization Branches Out, Association for Computational Linguistics, Barcelona, Spain, (2004), 74–81. |
| [22] | R. Cipolla, Y. Gal, A. Kendall, Multi-task learning using uncertainty to weigh losses for scene geometry and semantics, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2018), 7482–7491. |
| [23] | S. Kiritchenko, S. Mohammad, Best-worst scaling more reliable than rating scales: A case study on sentiment intensity annotation, in Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, (2017), 465–470. https://doi.org/10.18653/v1/P17-2074 |





Figures(6) / Tables(4)

Kaixiong Zhang, Yongbing Zhang, Zhengtao Yu, Yuxin Huang, Kaiwen Tan. A two-stage fine-tuning method for low-resource cross-lingual summarization[J]. Mathematical Biosciences and Engineering, 2024, 21(1): 1125-1143. doi: 10.3934/mbe.2024047







 DownLoad:
DownLoad: