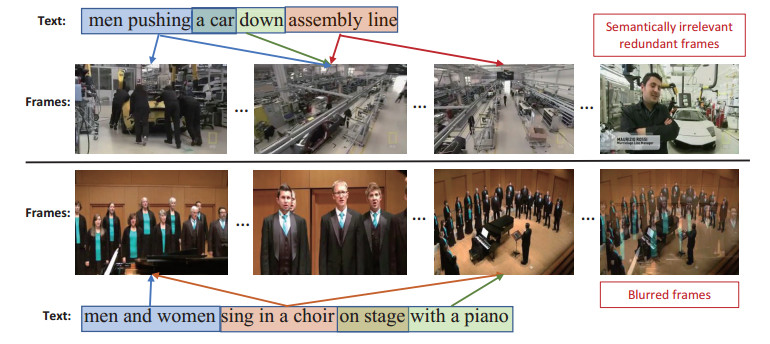
Current research in cross-modal retrieval has primarily focused on aligning the global features of videos and sentences. However, video conveys a much more comprehensive range of information than text. Thus, text-video matching should focus on the similarities between frames containing critical information and text semantics. This paper proposes a cross-modal conditional feature aggregation model based on the attention mechanism. It includes two innovative modules: (1) A cross-modal attentional feature aggregation module, which uses the semantic text features as conditional projections to extract the most relevant features from the video frames. It aggregates these frame features to form global video features. (2) A global-local similarity calculation module calculates similarities at two granularities (video-sentence and frame-word features) to consider both the topic and detail features in the text-video matching process. Our experiments on the four widely used MSR-VTT, LSMDC, MSVD and DiDeMo datasets demonstrate the effectiveness of our model and its superiority over state-of-the-art methods. The results show that the cross-modal attention aggregation approach can effectively capture the primary semantic information of the video. At the same time, the global-local similarity calculation model can accurately match text and video based on topic and detail features.
Citation: Wanru Du, Xiaochuan Jing, Quan Zhu, Xiaoyin Wang, Xuan Liu. A cross-modal conditional mechanism based on attention for text-video retrieval[J]. Mathematical Biosciences and Engineering, 2023, 20(11): 20073-20092. doi: 10.3934/mbe.2023889
Current research in cross-modal retrieval has primarily focused on aligning the global features of videos and sentences. However, video conveys a much more comprehensive range of information than text. Thus, text-video matching should focus on the similarities between frames containing critical information and text semantics. This paper proposes a cross-modal conditional feature aggregation model based on the attention mechanism. It includes two innovative modules: (1) A cross-modal attentional feature aggregation module, which uses the semantic text features as conditional projections to extract the most relevant features from the video frames. It aggregates these frame features to form global video features. (2) A global-local similarity calculation module calculates similarities at two granularities (video-sentence and frame-word features) to consider both the topic and detail features in the text-video matching process. Our experiments on the four widely used MSR-VTT, LSMDC, MSVD and DiDeMo datasets demonstrate the effectiveness of our model and its superiority over state-of-the-art methods. The results show that the cross-modal attention aggregation approach can effectively capture the primary semantic information of the video. At the same time, the global-local similarity calculation model can accurately match text and video based on topic and detail features.

| [1] | A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, et al., An image is worth 16x16 words: Transformers for image recognition at scale, preprint, arXiv: 2010.11929. |
| [2] | Y. Liu, S. Albanie, A. Nagrani, A. Zisserman, Use what you have: Video retrieval using representations from collaborative experts, preprint, arXiv: 1907.13487. |
| [3] | X. Wang, J. Wu, J. Chen, L. Li, Y. F. Wang, W. Y. Wang, Vatex: A large-scale, high-quality multilingual dataset for video-and-language research, in Proceedings of the IEEE/CVF International Conference on Computer Vision, (2019), 4581–4591. https://doi.org/10.1109/ICCV.2019.00468 |
| [4] | L. Zhu, Y. Yang, Actbert: Learning global-local video-text representations, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2020), 8746–8755. https://doi.org/10.1109/CVPR42600.2020.00877 |
| [5] | F. C. Heilbron, V. Escorcia, B. Ghanem, J. C. Niebles, Activitynet: A large-scale video benchmark for human activity understanding, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2015), 961–970. https://doi.org/10.1109/CVPR.2015.7298698 |
| [6] | H. Luo, L. Ji, B. Shi, H. Huang, N. Duan, T. Li, et al., Univl: A unified video and language pre-training model for multimodal understanding and generation, preprint, arXiv: 2002.06353. |
| [7] | N. Shvetsova, B. Chen, A. Rouditchenko, S. Thomas, B. Kingsbury, R. S. Feris, et al., Everything at once-multi-modal fusion transformer for video retrieval, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2022), 20020–20029. https://doi.org/10.1109/CVPR52688.2022.01939 |
| [8] | N. C. Mithun, J. Li, F. Metze, A. K. Roy-Chowdhury, Learning joint embedding with multimodal cues for cross-modal video-text retrieval, in Proceedings of the 2018 ACM on International Conference on Multimedia Retrieval, (2018), 19–27. https://doi.org/10.1145/3206025.3206064 |
| [9] | J. Xu, T. Mei, T. Yao, Y. Rui, Msr-vtt: A large video description dataset for bridging video and language, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2016), 5288–5296. https://doi.org/10.1109/CVPR.2016.571 |
| [10] | Y. Yuan, T. Mei, W. Zhu, To find where you talk: Temporal sentence localization in video with attention based location regression, in Proceedings of the AAAI Conference on Artificial Intelligence, 33 (2019), 9159–9166. https://doi.org/10.1609/aaai.v33i01.33019159 |
| [11] | J. Dong, X. Li, C. Xu, S. Ji, Y. He, G. Yang, et al., Dual encoding for zero-example video retrieval, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2019), 9346–9355. https://doi.org/10.1109/CVPR.2019.00957 |
| [12] | M. Bain, A. Nagrani, G. Varol, A. Zisserman, Frozen in time: A joint video and image encoder for end-to-end retrieval, in Proceedings of the IEEE/CVF International Conference on Computer Vision, (2021), 1728–1738. https://doi.org/10.1109/ICCV48922.2021.00175 |
| [13] | A. Miech, D. Zhukov, J. B. Alayrac, M. Tapaswi, I. Laptev, J. Sivic, Howto100m: Learning a text-video embedding by watching hundred million narrated video clips, in Proceedings of the IEEE/CVF International Conference on Computer Vision, (2019), 2630–2640. https://doi.org/10.1109/ICCV.2019.00272 |
| [14] | S. Wang, R. Wang, Z. Yao, S. Shan, X. Chen, Cross-modal scene graph matching for relationship-aware image-text retrieval, in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, (2020), 1508–1517. https://doi.org/10.1109/WACV45572.2020.9093614 |
| [15] |
F. Shang, C. Ran, An entity recognition model based on deep learning fusion of text feature, Inf. Process. Manage., 59 (2022), 102841. https://doi.org/10.1016/j.ipm.2021.102841 doi: 10.1016/j.ipm.2021.102841

|
| [16] | Y. Zhou, R. Zhang, C. Chen, C. Li, C. Tensmeyer, T. Yu, et al., Towards language-free training for text-to-image generation, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2022), 17907–17917. https://doi.org/10.1109/CVPR52688.2022.01738 |
| [17] |
W. Li, S. Wen, K. Shi, Y. Yang, T. Huang, Neural architecture search with a lightweight transformer for text-to-image synthesis, IEEE Trans. Network Sci. Eng., 9 (2022), 1567–1576. https://doi.org/10.1109/TNSE.2022.3147787 doi: 10.1109/TNSE.2022.3147787
|
| [18] | T. Mikolov, K. Chen, G. Corrado, J. Dean, Efficient estimation of word representations in vector space, preprint, arXiv: 1301.3781. |
| [19] | F. Perronnin, C. Dance, Fisher kernels on visual vocabularies for image categorization, in 2007 IEEE Conference on Computer Vision and Pattern Recognition, (2007), 1–8. https://doi.org/10.1109/CVPR.2007.383266 |
| [20] | B. Klein, G. Lev, G. Sadeh, L. Wolf, Associating neural word embeddings with deep image representations using Fisher vectors, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2015), 4437–4446. https://doi.org/10.1109/CVPR.2015.7299073 |
| [21] | R. Kiros, R. Salakhutdinov, R. S. Zemel, Unifying visual-semantic embeddings with multimodal neural language models, preprint, arXiv: 1411.2539. |
| [22] | A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, et al., Learning transferable visual models from natural language supervision, preprint, arXiv: 2103.00020. |
| [23] | I. Croitoru, S. V. Bogolin, M. Leordeanu, H. Jin, A. Zisserman, S. Albanie, et al., Teachtext: Crossmodal generalized distillation for text-video retrieval, in Proceedings of the IEEE/CVF International Conference on Computer Vision, (2021), 11583–11593. https://doi.org/10.1109/ICCV48922.2021.01138 |
| [24] | A. Arnab, M. Dehghani, G. Heigold, C. Sun, M. Lučić, C. Schmid, Vivit: A video vision transformer, in Proceedings of the IEEE/CVF International Conference on Computer Vision, (2021), 6836–6846. https://doi.org/10.1109/ICCV48922.2021.00676 |
| [25] |
G. Bertasius, H. Wang, L. Torresani, Is space-time attention all you need for video understanding?, ICML, 2 (2021), 4. https://doi.org/10.48550/arXiv.2102.05095 doi: 10.48550/arXiv.2102.05095
|
| [26] | A. Miech, J. B. Alayrac, L. Smaira, I. Laptev, J. Sivic, A. Zisserman, End-to-end learning of visual representations from uncurated instructional videos, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2020), 9879–9889. https://doi.org/10.1109/CVPR42600.2020.00990. |
| [27] | X. Duan, W. Huang, C. Gan, J. Wang, W. Zhu, J. Huang, Weakly supervised dense event captioning in videos, Adv. Neural Inf. Process. Syst., 31 (2018). https://doi.org/10.48550/arXiv.1812.03849 |
| [28] | R. Tan, H. Xu, K. Saenko, B. A. Plummer, Logan: Latent graph co-attention network for weakly-supervised video moment retrieval, in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, (2021), 2083–2092. https://doi.org/10.1109/WACV48630.2021.00213 |
| [29] | V. Gabeur, C. Sun, K. Alahari, C. Schmid, Multi-modal transformer for video retrieval, in Computer Vision–ECCV 2020: 16th European Conference, (2020), 214–229. https://doi.org/10.48550/arXiv.2007.10639 |
| [30] | M. Dzabraev, M. Kalashnikov, S. Komkov, A. Petiushko, Mdmmt: Multidomain multimodal transformer for video retrieval, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2021), 3354–3363. https://doi.org/10.1109/CVPRW53098.2021.00374 |
| [31] |
L. Li, Z. Shu, Z. Yu, X. J. Wu, Robust online hashing with label semantic enhancement for cross-modal retrieval, Pattern Recognit., 145 (2023), 109972. https://doi.org/10.1109/ICME55011.2023.00173 doi: 10.1109/ICME55011.2023.00173
|
| [32] |
Z. Shu, K. Yong, J. Yu, S. Gao, C. Mao, Z. Yu, Discrete asymmetric zero-shot hashing with application to cross-modal retrieval, Neurocomputing, 511 (2022), 366–379. https://doi.org/10.1016/j.neucom.2022.09.037 doi: 10.1016/j.neucom.2022.09.037
|
| [33] |
Z. Shu, Y. Bai, D. Zhang, J. Yu, Z. Yu, X. J. Wu, Specific class center guided deep hashing for cross-modal retrieval, Inf. Sci., 609 (2022), 304–318. https://doi.org/10.1016/j.ins.2022.07.095 doi: 10.1016/j.ins.2022.07.095
|
| [34] |
M. Su, G. Gu, X. Ren, H. Fu, Y. Zhao, Semi-supervised knowledge distillation for cross-modal hashing, IEEE Trans. Multimedia, 25 (2021), 662–675. https://doi.org/10.1109/TMM.2021.3129623 doi: 10.1109/TMM.2021.3129623
|
| [35] | J. A. Portillo-Quintero, J. C. Ortiz-Bayliss, H. Terashima-Marín, A straightforward framework for video retrieval using clip, in Mexican Conference on Pattern Recognition, (2021), 3–12. https://doi.org/10.1007/978-3-030-77004-4_1 |
| [36] | M. Patrick, P. Y. Huang, Y. Asano, F. Metze, A. Hauptmann, J. Henriques, et al., Support-set bottlenecks for video-text representation learning, preprint, arXiv: 2010.02824. |
| [37] | Z. Wang, X. Liu, H. Li, L. Sheng, J. Yan, X. Wang, et al., Camp: Cross-modal adaptive message passing for text-image retrieval, in Proceedings of the IEEE/CVF International Conference on Computer Vision, (2019), 5764–5773. https://doi.org/10.1109/ICCV.2019.00586 |
| [38] | H. Diao, Y. Zhang, L. Ma, H. Lu, Similarity reasoning and filtration for image-text matching, in Proceedings of the AAAI Conference on Artificial Intelligence, 35 (2021), 1218–1226. https://doi.org/10.1609/aaai.v35i2.16209 |
| [39] |
Y. Liu, H. Liu, H. Wang, F. Meng, M. Liu, BCAN: Bidirectional correct attention network for cross-modal retrieval, IEEE Trans. Neural Netw. Learn. Syst., (2023). https://doi.org/10.1109/TNNLS.2023.3276796 doi: 10.1109/TNNLS.2023.3276796
|
| [40] | S. K. Gorti, N. Vouitsis, J. Ma, K. Golestan, M. Volkovs, A. Garg, et al., X-pool: Cross-modal language-video attention for text-video retrieval, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2022), 5006–5015. https://doi.org/10.1109/CVPR52688.2022.00495 |
| [41] | H. Chen, G. Ding, X. Liu, Z. Lin, J. Liu, J. Han, Imram: Iterative matching with recurrent attention memory for cross-modal image-text retrieval, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2020), 12655–12663. https://doi.org/10.1109/CVPR42600.2020.01267 |
| [42] | F. Faghri, D. J. Fleet, J. R. Kiros, S. Fidler, Vse++: Improving visual-semantic embeddings with hard negatives, preprint, arXiv: 1707.05612. |
| [43] | Y. Yu, J. Kim, G. Kim, A joint sequence fusion model for video question answering and retrieval, in Proceedings of the European Conference on Computer Vision (ECCV), (2018), 471–487. https://doi.org/10.1007/978-3-030-01234-2_29 |
| [44] | A. Rohrbach, M. Rohrbach, N. Tandon, B. Schiele, A dataset for movie description, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2015), 3202–3212. https://doi.org/10.1109/CVPR.2015.7298940 |
| [45] | N. Srivastava, G. Hinton, A. Krizhevsky, I. Sutskever, R. Salakhutdinov, Dropout: A simple way to prevent neural networks from overfitting, J. Mach. Learn. Res., 15 (2014), 1929–1958. |
| [46] | Z. Xie, I. Sato, M. Sugiyama, Stable weight decay regularization, preprint, arXiv: 2011.11152. |
| [47] | S. Liu, H. Fan, S. Qian, Y. Chen, W. Ding, Z. Wang, Hit: Hierarchical transformer with momentum contrast for video-text retrieval, in Proceedings of the IEEE/CVF International Conference on Computer Vision, (2021), 11915–11925. https://doi.org/10.1109/ICCV48922.2021.01170 |
| [48] | J. Wang, Y. Ge, R. Yan, Y. Ge, K. Q. Lin, S. Tsutsui, et al., All in one: Exploring unified video-language pre-training, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2023), 6598–6608. https://doi.org/10.1109/CVPR52729.2023.00638 |
| [49] | J. Lei, L. Li, L. Zhou, Z. Gan, T. L. Berg, M. Bansal, et al., Less is more: Clipbert for video-and-language learning via sparse sampling, in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, (2021), 7331–7341. https://doi.org/10.1109/CVPR46437.2021.00725 |
| [50] | H. Fang, P. Xiong, L. Xu, Y. Chen, Clip2video: Mastering video-text retrieval via image clip, preprint, arXiv: 2106.11097. |
| [51] | J. Lei, T. L. Berg, M. Bansal, Revealing single frame bias for video-and-language learning, preprint, arXiv: 2011.11152. |
| [52] | L. Li, Z. Gan, K. Lin, C. C. Lin, Z. Liu, C. Liu, et al., Lavender: Unifying video-language understanding as masked language modeling, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2023), 23119–23129. https://doi.org/10.1109/CVPR52729.2023.02214 |
| [53] |
H. Luo, L. Ji, M. Zhong, Y. Chen, W. Lei, N. Duan, et al., Clip4clip: An empirical study of clip for end to end video clip retrieval and captioning, Neurocomputing, 508 (2022), 293–304. https://doi.org/10.1016/j.neucom.2022.07.028 doi: 10.1016/j.neucom.2022.07.028
|
| [54] | F. Cheng, X. Wang, J. Lei, D. Crandall, M. Bansal, G. Bertasius, Vindlu: A recipe for effective video-and-language pretraining, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2023), 10739–10750. https://doi.org/10.1109/CVPR52729.2023.01034 |




Figures(5) / Tables(3)

Wanru Du, Xiaochuan Jing, Quan Zhu, Xiaoyin Wang, Xuan Liu. A cross-modal conditional mechanism based on attention for text-video retrieval[J]. Mathematical Biosciences and Engineering, 2023, 20(11): 20073-20092. doi: 10.3934/mbe.2023889







 DownLoad:
DownLoad: