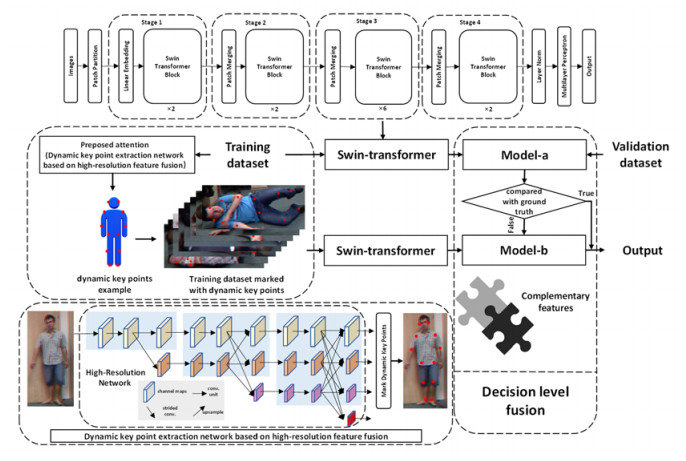
Accidental falls pose a significant threat to the elderly population, and accurate fall detection from surveillance videos can significantly reduce the negative impact of falls. Although most fall detection algorithms based on video deep learning focus on training and detecting human posture or key points in pictures or videos, we have found that the human pose-based model and key points-based model can complement each other to improve fall detection accuracy. In this paper, we propose a preposed attention capture mechanism for images that will be fed into the training network, and a fall detection model based on this mechanism. We accomplish this by fusing the human dynamic key point information with the original human posture image. We first propose the concept of dynamic key points to account for incomplete pose key point information in the fall state. We then introduce an attention expectation that predicates the original attention mechanism of the depth model by automatically labeling dynamic key points. Finally, the depth model trained with human dynamic key points is used to correct the detection errors of the depth model with raw human pose images. Our experiments on the Fall Detection Dataset and the UP-Fall Detection Dataset demonstrate that our proposed fall detection algorithm can effectively improve the accuracy of fall detection and provide better support for elderly care.
Citation: Kun Zheng, Bin Li, Yu Li, Peng Chang, Guangmin Sun, Hui Li, Junjie Zhang. Fall detection based on dynamic key points incorporating preposed attention[J]. Mathematical Biosciences and Engineering, 2023, 20(6): 11238-11259. doi: 10.3934/mbe.2023498
Accidental falls pose a significant threat to the elderly population, and accurate fall detection from surveillance videos can significantly reduce the negative impact of falls. Although most fall detection algorithms based on video deep learning focus on training and detecting human posture or key points in pictures or videos, we have found that the human pose-based model and key points-based model can complement each other to improve fall detection accuracy. In this paper, we propose a preposed attention capture mechanism for images that will be fed into the training network, and a fall detection model based on this mechanism. We accomplish this by fusing the human dynamic key point information with the original human posture image. We first propose the concept of dynamic key points to account for incomplete pose key point information in the fall state. We then introduce an attention expectation that predicates the original attention mechanism of the depth model by automatically labeling dynamic key points. Finally, the depth model trained with human dynamic key points is used to correct the detection errors of the depth model with raw human pose images. Our experiments on the Fall Detection Dataset and the UP-Fall Detection Dataset demonstrate that our proposed fall detection algorithm can effectively improve the accuracy of fall detection and provide better support for elderly care.

| [1] |
Y. Chen, Y. Zhang, B. Xiao, H. Li, A framework for the elderly first aid system by integrating vision-based fall detection and BIM-based indoor rescue routing, Adv. Eng. Inf., 54 (2022), 101766. http://doi.org/10.1016/j.aei.2022.101766 doi: 10.1016/j.aei.2022.101766

|
| [2] |
M. Mubashir, L. Shao, L. Seed, A survey on fall detection: Principles and approaches, Neurocomputing, 100 (2013), 144–152. http://doi.org/10.1016/j.neucom.2011.09.037 doi: 10.1016/j.neucom.2011.09.037
|
| [3] |
S. Nooruddin, M. Islam, F. A. Sharna, H. Alhetari, M. N. Kabir, Sensor-based fall detection systems: a review, J. Ambient Intell. Hum. Comput., 2009 (2009), 1–17. http://doi.org/10.1109/biocas.2009.5372032 doi: 10.1109/biocas.2009.5372032
|
| [4] |
F. A. S. F. de Sousa, C. Escriba, E. G. A. Bravo, V. Brossa, J. Y. Fourniols, C. Rossi, Wearable pre-impact fall detection system based on 3D accelerometer and subject's height, IEEE Sens. J., 22 (2022), 1738–1745. http://doi.org/10.1109/biocas.2009.5372032 doi: 10.1109/biocas.2009.5372032
|
| [5] |
Z. Lin, Z. Wang, H. Dai, X. Xia, Efficient fall detection in four directions based on smart insoles and RDAE-LSTM model, Expert Syst. Appl., 205 (2022), 117661. http://doi.org/10.1016/j.eswa.2022.117661 doi: 10.1016/j.eswa.2022.117661
|
| [6] |
P. Bet, P. C. Castro, M. A. Ponti, Fall detection and fall risk assessment in older person using wearable sensors: A systematic review, Int. J. Med. Inf., 130 (2019), 103946. http://doi.org/10.1016/j.ijmedinf.2019.08.006 doi: 10.1016/j.ijmedinf.2019.08.006
|
| [7] |
I. Boudouane, A. Makhlouf, M. A. Harkat, M. Z. Hammouche, N. Saadia, A. R. Cherif, Fall detection system with portable camera, J. Ambient Intell. Hum. Comput., 11 (2019), 2647–2659. http://doi.org/10.1007/s12652-019-01326-x doi: 10.1007/s12652-019-01326-x
|
| [8] |
E. Casilari, C. A. Silva, An analytical comparison of datasets of Real-World and simulated falls intended for the evaluation of wearable fall alerting systems, Measurement, 202 (2022), 111843. http://doi.org/10.1016/j.measurement.2022.111843 doi: 10.1016/j.measurement.2022.111843
|
| [9] |
C. Wang, L. Tang, M. Zhou, Y. Ding, X. Zhuang, J. Wu, Indoor human fall detection algorithm based on wireless sensing, Tsinghua Sci. Technol., 27 (2022), 1002–1015. http://doi.org/10.26599/tst.2022.9010011 doi: 10.26599/tst.2022.9010011
|
| [10] | S. Madansingh, T. A. Thrasher, C. S. Layne, B. C. Lee, Smartphone based fall detection system, in 2015 15th International Conference on Control, Automation and Systems, ICCAS, (2015), 370–374. https://doi.org/10.1109/ICCAS.2015.7364941 |
| [11] |
B. Wang, Z. Zheng, Y. X. Guo, Millimeter-Wave frequency modulated continuous wave radar-based soft fall detection using pattern contour-confined Doppler-Time maps, IEEE Sens. J., 22 (2022), 9824–9831. http://doi.org/10.1109/jsen.2022.3165188 doi: 10.1109/jsen.2022.3165188
|
| [12] |
K. Chaccour, R. Darazi, A. H. El Hassani, E. Andres, From fall detection to fall prevention: A generic classification of fall-related systems, IEEE Sens. J., 17 (2017), 812–822. http://doi.org/10.1109/jsen.2016.2628099 doi: 10.1109/jsen.2016.2628099
|
| [13] | J. Gutiérrez, V. Rodríguez, S. Martin, Comprehensive review of vision-based fall detection systems, Sensors, 21 (2021), 947. https://pubmed.ncbi.nlm.nih.gov/33535373 |
| [14] | C. Y. Hsieh, K. C. Liu, C. N. Huang, W. C. Chu, C. T. Chan, Novel hierarchical fall detection algorithm using a multiphase fall model, Sensors, 17 (2017), 307. https://pubmed.ncbi.nlm.nih.gov/28208694 |
| [15] |
L. Ren, Y. Peng, Research of fall detection and fall prevention technologies: A systematic review, IEEE Access, 7 (2019), 77702–77722. http://doi.org/10.1109/access.2019.2922708 doi: 10.1109/access.2019.2922708
|
| [16] | N. Dalal, B. Triggs, Histograms of oriented gradients for human detection, in 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, (2005), 886–893. http://doi.org/10.1109/cvpr.2005.177 |
| [17] | E. Rublee, V. Rabaud, K. Konolige, G. Bradski, ORB: An efficient alternative to SIFT or SURF, in 2011 International Conference on Computer Vision, (2011), 2564–2571. http://doi.org/10.1109/iccv.2011.6126544 |
| [18] | X. Wang, T. X. Han, S. Yan, An HOG-LBP human detector with partial occlusion handling, in 2009 IEEE 12th International Conference on Computer Vision, (2009), 32–39. http://doi.org/10.1109/iccv.2009.5459207 |
| [19] | M. Islam, S. Nooruddin, F. Karray, G. Muhammad, Human activity recognition using tools of convolutional neural networks: A state of the art review, data sets, challenges and future prospects, Comput. Biol. Med., 149 (2022), 106060. http://doi.org/10.1109/iccv.2009.5459207 |
| [20] |
K. C. Liu, K. H. Hung, C. Y. Hsieh, H. Y. Huang, C. T. Chan, Y. Tsao, Deep-learning-based signal enhancement of low-resolution accelerometer for fall detection systems, IEEE Trans. Cognit. Dev. Syst., 14 (2022), 1270–1281. http://doi.org/10.1109/tcds.2021.3116228 doi: 10.1109/tcds.2021.3116228
|
| [21] |
X. Yu, B. Koo, J. Jang, Y. Kim, S. Xiong, A comprehensive comparison of accuracy and practicality of different types of algorithms for pre-impact fall detection using both young and old adults, Measurement, 201 (2022), 111785. http://doi.org/10.2139/ssrn.4132951 doi: 10.2139/ssrn.4132951
|
| [22] |
X. Lu, W. Wang, J. Shen, D. J. Crandall, L. Van Gool, Segmenting objects from relational visual data, IEEE Trans. Pattern Anal. Mach. Intell., 44 (2022), 7885–7897. http://doi.org/10.1109/tpami.2021.3115815 doi: 10.1109/tpami.2021.3115815
|
| [23] |
H. M. Abdulwahab, S. Ajitha, M. A. N. Saif, Feature selection techniques in the context of big data: taxonomy and analysis, Appl. Intell., 52 (2022), 13568–13613. http://doi.org/10.1007/s10489-021-03118-3 doi: 10.1007/s10489-021-03118-3
|
| [24] |
D. Mrozek, A. Koczur, B. Małysiak-Mrozek, Fall detection in older adults with mobile IoT devices and machine learning in the cloud and on the edge, Inf. Sci., 537 (2020), 132–147. http://doi.org/10.1016/j.ins.2020.05.070 doi: 10.1016/j.ins.2020.05.070
|
| [25] |
X. Cai, S. Li, X. Liu, G. Han, Vision-based fall detection with multi-task hourglass convolutional auto-encoder, IEEE Access, 8 (2020), 44493–44502. http://doi.org/10.1109/access.2020.2978249 doi: 10.1109/access.2020.2978249
|
| [26] |
C. Vishnu, R. Datla, D. Roy, S. Babu, C. K. Mohan, Human fall detection in surveillance videos using fall motion vector modeling, IEEE Sens. J., 21 (2021), 17162–17170. http://doi.org/10.1109/jsen.2021.3082180 doi: 10.1109/jsen.2021.3082180
|
| [27] | Z. Liu, Y. Lin, Y. Cao, H. Hu, Y. Wei, Z. Zhang, et al., Swin transformer: Hierarchical vision transformer using shifted windows, in Proceedings of the IEEE/CVF International Conference on Computer Vision, (2021), 10012–10022. https://doi.org/10.48550/arXiv.2103.14030 |
| [28] | A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, et al, Attention is all you need, in Advances in Neural Information Processing Systems, 30 (2017). |
| [29] |
Y. LeCun, L. Bottou, Y. Bengio, P. Haffner, Gradient-based learning applied to document recognition, Proc. IEEE, 86 (1998), 2278–2324. http://doi.org/10.1109/5.726791 doi: 10.1109/5.726791
|
| [30] | H. Pashler, J. C. Johnston, E. Ruthruff, Attention and performance, Ann. Rev. Psychol., 52 (2001), 629. https://doi.org/10.1146/annurev.psych.52.1.629 |
| [31] | J. Wang, K. Sun, T. Cheng, B. Jiang, C. Deng, Y. Zhao, et al., Deep high-resolution representation learning for visual recognition, IEEE Trans. Pattern Anal. Mach. Intell., 43 (2021), 3349–3364. https://doi.org/10.1109/TPAMI.2020.2983686 |
| [32] | T. Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, et al., Microsoft coco: Common objects in context, in European Conference on Computer Vision, (2014), 740–755. http://doi.org/10.1007/978-3-319-10602-1_48 |
| [33] | M. Andriluka, L. Pishchulin, P. Gehler, B. Schiele, 2d human pose estimation: New benchmark and state of the art analysis, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, (2014), 3686–3693. http://doi.org/10.1109/cvpr.2014.471 |
| [34] | B. Sapp, B. Taskar, Modec: Multimodal decomposable models for human pose estimation, in 2013 IEEE Conference on Computer Vision and Pattern Recognition, (2013), 3674–3681. http://doi.org/10.1109/cvpr.2013.471 |
| [35] |
B. Kwolek, M. Kepski, Human fall detection on embedded platform using depth maps and wireless accelerometer, Comput. Methods Programs Biomed., 117 (2014), 489–501. http://doi.org/10.1016/j.cmpb.2014.09.005 doi: 10.1016/j.cmpb.2014.09.005
|
| [36] | K. Adhikari, H. Bouchachia, H. Nait-Charif, Activity recognition for indoor fall detection using convolutional neural network, in 2017 Fifteenth IAPR International Conference on Machine Vision Applications, MVA, (2017), 81–84. http://doi.org/10.23919/mva.2017.7986795 |
| [37] | L. Martínez-Villaseñor, H. Ponce, J. Brieva, E. Moya-Albor, J. Núñez-Martínez, C. Peñafort-Asturiano, UP-fall detection dataset: A multimodal approach, Sensors, 19 (2019), 988. https://pubmed.ncbi.nlm.nih.gov/31035377 |
| [38] | H. Yhdego, J. Li, S. Morrison, M. Audette, C. Paolini, M. Sarkar, et al., Towards musculoskeletal simulation-aware fall injury mitigation: transfer learning with deep CNN for fall detection, in 2019 Spring Simulation Conference (SpringSim), (2019), 1–12. http://doi.org/10.22360/springsim.2019.msm.015 |
| [39] |
H. Sadreazami, M. Bolic, S. Rajan, Fall detection using standoff radar-based sensing and deep convolutional neural network, IEEE Trans. Circuits Syst. Ⅱ Express Briefs, 67 (2020), 197–201. http://doi.org/10.1109/tcsii.2019.2904498 doi: 10.1109/tcsii.2019.2904498
|
| [40] |
A. Núñez-Marcos, G. Azkune, I. Arganda-Carreras, Vision-based fall detection with convolutional neural networks, Wireless Commun. Mobile Comput., 2017 (2017). https://doi.org/10.1155/2017/9474806 doi: 10.1155/2017/9474806
|
| [41] |
S. Chhetri, A. Alsadoon, T. Al-Dala'in, P. W. C. Prasad, T. A. Rashid, A. Maag, Deep learning for vision-based fall detection system: Enhanced optical dynamic flow, Comput. Intell., 37 (2020), 578–595. http://doi.org/10.1111/coin.12428 doi: 10.1111/coin.12428
|
| [42] |
C. Khraief, F. Benzarti, H. Amiri, Elderly fall detection based on multi-stream deep convolutional networks, Multimedia Tools Appl., 79 (2020), 19537–19560. http://doi.org/10.1007/s11042-020-08812-x doi: 10.1007/s11042-020-08812-x
|
| [43] |
N. Lu, Y. Wu, L. Feng, J. Song, Deep learning for fall detection: Three-dimensional CNN combined with LSTM on video kinematic data, IEEE J. Biomed. Health Inf., 23 (2019), 314–323. http://doi.org/10.1109/jbhi.2018.2808281 doi: 10.1109/jbhi.2018.2808281
|
| [44] |
H. Li, C. Li, Y. Ding, Fall detection based on fused saliency maps, Multimedia Tools Appl., 80 (2020), 1883–1900. http://doi.org/10.1007/s11042-020-09708-6 doi: 10.1007/s11042-020-09708-6
|
| [45] | R. K. Meleppat, M. V. Matham, L. K. Seah, Optical frequency domain imaging with a rapidly swept laser in the 1300 nm bio-imaging window, in International Conference on Optical and Photonic Engineering, (2015), 721–729. http://doi.org/10.1117/12.2190530 |
| [46] |
K. M. Ratheesh, L. K. Seah, V. M. Murukeshan, Spectral phase-based automatic calibration scheme for swept source-based optical coherence tomography systems, Phys. Med. Biol., 61 (2016), 7652–7663. http://doi.org/10.1088/0031-9155/61/21/7652 doi: 10.1088/0031-9155/61/21/7652
|
| [47] |
R. K. Meleppat, M. V. Matham, L. K. Seah, An efficient phase analysis-based wavenumber linearization scheme for swept source optical coherence tomography systems, Laser Phys. Lett., 12 (2015), 055601. http://doi.org/10.1088/1612-2011/12/5/055601 doi: 10.1088/1612-2011/12/5/055601
|
| [48] | R. K. Meleppat, C. R. Fortenbach, Y. Jian, E. S. Martinez, K. Wagner, B. S. Modjtahedi, et al. In Vivo imaging of retinal and choroidal morphology and vascular plexuses of vertebrates using swept-source optical coherence tomography, Transl. Vision Sci. Technol., 11 (2022), 11. https://pubmed.ncbi.nlm.nih.gov/35972433 |
| [49] | V. M. Murukeshan, L. K. Seah, C. Shearwood, Quantification of biofilm thickness using a swept source based optical coherence tomography system, in International Conference on Optical and Photonic Engineering, (2015), 683–688. http://doi.org/10.1117/12.2190106 |














Figures(15) / Tables(9)

Kun Zheng, Bin Li, Yu Li, Peng Chang, Guangmin Sun, Hui Li, Junjie Zhang. Fall detection based on dynamic key points incorporating preposed attention[J]. Mathematical Biosciences and Engineering, 2023, 20(6): 11238-11259. doi: 10.3934/mbe.2023498







 DownLoad:
DownLoad: