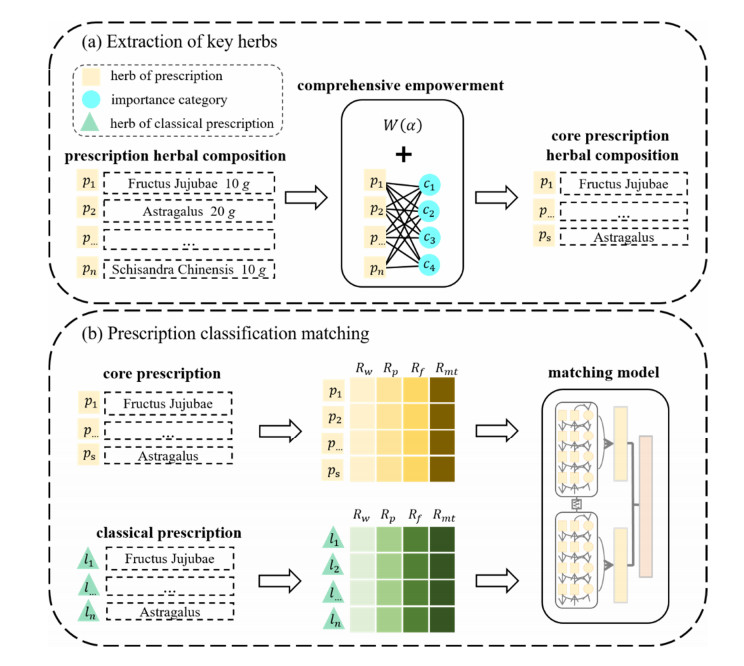
Prescription data is an important focus and breakthrough in the study of clinical treatment rules, and the complex multidimensional relationships between Traditional Chinese medicine (TCM) prescription data increase the difficulty of extracting knowledge from clinical data. This paper proposes a complex prescription recognition algorithm (MTCMC) based on the classification and matching of TCM prescriptions with classical prescriptions to identify the classical prescriptions contained in the prescriptions and provide a reference for mining TCM knowledge. The MTCMC algorithm first calculates the importance level of each drug in the complex prescriptions and determines the core prescription combinations of patients through the Analytic Hierarchy Process (AHP) combined with drug dosage. Secondly, a drug attribute tagging strategy was used to quantify the functional features of each drug in the core prescriptions; finally, a Bidirectional Long Short-Term Memory Network (BiLSTM) was used to extract the relational features of the core prescriptions, and a vector representation similarity matrix was constructed in combination with the Siamese network framework to calculate the similarity between the core prescriptions and the classical prescriptions. The experimental results show that the accuracy and F1 score of the prescription matching dataset constructed based on this paper reach 94.45% and 94.34% respectively, which is a significant improvement compared with the models of existing methods.
Citation: Wangping Xiong, Kaiqi Wang, Shixiong Liu, Zhaoyang Liu, Yimin Zhu, Peng Liu, Ming Yang, Xian Zhou. Multiple prescription pattern recognition model based on Siamese network[J]. Mathematical Biosciences and Engineering, 2023, 20(10): 18695-18716. doi: 10.3934/mbe.2023829
Prescription data is an important focus and breakthrough in the study of clinical treatment rules, and the complex multidimensional relationships between Traditional Chinese medicine (TCM) prescription data increase the difficulty of extracting knowledge from clinical data. This paper proposes a complex prescription recognition algorithm (MTCMC) based on the classification and matching of TCM prescriptions with classical prescriptions to identify the classical prescriptions contained in the prescriptions and provide a reference for mining TCM knowledge. The MTCMC algorithm first calculates the importance level of each drug in the complex prescriptions and determines the core prescription combinations of patients through the Analytic Hierarchy Process (AHP) combined with drug dosage. Secondly, a drug attribute tagging strategy was used to quantify the functional features of each drug in the core prescriptions; finally, a Bidirectional Long Short-Term Memory Network (BiLSTM) was used to extract the relational features of the core prescriptions, and a vector representation similarity matrix was constructed in combination with the Siamese network framework to calculate the similarity between the core prescriptions and the classical prescriptions. The experimental results show that the accuracy and F1 score of the prescription matching dataset constructed based on this paper reach 94.45% and 94.34% respectively, which is a significant improvement compared with the models of existing methods.

| [1] |
D. C. Klonoff, The new FDA real-world evidence program to support development of drugs and biologics, J. Diabetes Sci. Technol., 14 (2020), 345–349. https://doi.org/10.1177/1932296819832661 doi: 10.1177/1932296819832661

|
| [2] |
G. Li, X. Zuo, B. Liu, Scientific computation of big data in real-world clinical research, Front. Med., 8 (2014), 310–315. https://doi.org/10.1007/s11684-014-0358-7 doi: 10.1007/s11684-014-0358-7
|
| [3] |
Q. Zhang, C. Yang, S. Ma, S. Guo, X. Hu, Z. Zhou, Shiwei Qingwen decoction regulates TLR4/NF-κB signaling pathway and NLRP3 inflammasome to reduce inflammatory response in lipopolysaccharide-induced acute lung injury, J. Ethnopharmacol., 313 (2023). https://doi.org/10.1016/j.jep.2023.116615 doi: 10.1016/j.jep.2023.116615
|
| [4] |
G. Song, Y. Wang, R. Zhang, B. Liu, X. Zhou, X. Zhou, et al., Experience inheritance from famous specialists based on real-world clinical research paradigm of traditional Chinese medicine, Front. Med., 8 (2014), 300–309. https://doi.org/10.1007/s11684-014-0357-8 doi: 10.1007/s11684-014-0357-8
|
| [5] |
X. Xiong, C. Huang, F. Wang, J. Dong, D. Zhang, J. Jiang, et al., Qingxue jiedu formulation ameliorated DNFB-induced atopic dermatitis by inhibiting STAT3/MAPK/NF-κB signaling pathways, J. Ethnopharmacol., 270 (2021). https://doi.org/10.1016/j.jep.2020.113773 doi: 10.1016/j.jep.2020.113773
|
| [6] |
J. Su, X. M. Chen, Y. L. Xie, M. Q. Li, Q. Shang, D. K. Zhang, et al., Clinical efficacy, pharmacodynamic components, and molecular mechanisms of antiviral granules in the treatment of influenza: A systematic review, J. Ethnopharmacol., 318 (2023). https://doi.org/10.1016/j.jep.2023.117011 doi: 10.1016/j.jep.2023.117011
|
| [7] |
X. Chen, C. Ruan, Y. Zhang, H. Chen, Heterogeneous information network based clustering for precision traditional Chinese medicine, BMC Med. Inf. Decis. Making, 19 (2019), 264. https://doi.org/10.1186/s12911-019-0963-0 doi: 10.1186/s12911-019-0963-0
|
| [8] |
X. Ren, X. X. Shao, X. X. Li, X. H. Jia, T. Song, W. Y. Zhou, et al., Identifying potential treatments of COVID-19 from Traditional Chinese Medicine (TCM) by using a data-driven approach, J. Ethnopharmacol., 258 (2020). https://doi.org/10.1016/j.jep.2020.112932 doi: 10.1016/j.jep.2020.112932
|
| [9] |
K. W. DeGregory, P. Kuiper, T. DeSilvio, J. D. Pleuss, R. Miller, J. W. Roginski, et al., A review of machine learning in obesity, Obes. Rev., 19 (2018), 668–685. https://doi.org/10.1111/obr.12667 doi: 10.1111/obr.12667
|
| [10] |
S. K. Poon, J. Poon, M. McGrane, X. Zhou, P. Kwan, R. Zhang, A novel approach in discovering significant interactions from TCM patient prescription data, Int. J. Data Min. Bioinf., 5 (2011), 353–368. https://doi.org/10.1504/ijdmb.2011.041553 doi: 10.1504/ijdmb.2011.041553
|
| [11] |
S. Li, B. Zhang, D. Jiang, Y. Wei, Y. Zhang, Herb network construction and co-module analysis for uncovering the combination rule of traditional Chinese herbal formulae, BMC Bioinf., 11 (2010), 1–12. https://doi.org/10.1186/1471-2105-11-S11-S6 doi: 10.1186/1471-2105-11-S11-S6
|
| [12] |
J. Liu, C. Li, Y. Huang, J. Han, An intelligent medical guidance and recommendation model driven by patient-physician communication data, Front. Public Health, 11 (2023). https://doi.org/10.3389/fpubh.2023.1098206 doi: 10.3389/fpubh.2023.1098206
|
| [13] |
M. Arbane, R. Benlamri, Y. Brik, A. D. Alahmar, Social media-based COVID-19 sentiment classification model using Bi-LSTM, Expert Syst. Appl., 212 (2023). https://doi.org/10.1016/j.eswa.2022.118710 doi: 10.1016/j.eswa.2022.118710
|
| [14] | H. Zhao, J. Luo, C. Liu, X. Lei, Z. Wang, Method of TCM prescription recognition based on template matching algorithm, in 2018 International Conference on Computer Modeling, Simulation and Algorithm (CMSA 2018), (2018), 336–339. https://doi.org/10.2991/cmsa-18.2018.77 |
| [15] |
Y. Zhang, X. Li, Y. Shi, T. Chen, Z. Xu, P. Wang, et al., ETCM v2.0: An update with comprehensive resource and rich annotations for traditional Chinese medicine, Acta Pharm. Sin. B, 13 (2023), 2559–2571. https://doi.org/10.1016/j.apsb.2023.03.012 doi: 10.1016/j.apsb.2023.03.012
|
| [16] |
Y. Wang, J. Xu, J. Zhang, H. Xu, Y. Sun, Y. Miao, et al., SIAP: an intelligent algorithm for multiple prescription pattern recognition based on weighted similarity distances, BMC Med. Inf. Decis. Making, 23 (2023), 79. https://doi.org/10.1186/s12911-023-02141-3 doi: 10.1186/s12911-023-02141-3
|
| [17] |
C. Y. Ung, H. Li, C. Y. Kong, J. F. Wang, Y. Z. Chen, Usefulness of traditionally defined herbal properties for distinguishing prescriptions of traditional Chinese medicine from non-prescription recipes, J. Ethnopharmacol., 109 (2007), 21–28. https://doi.org/10.1016/j.jep.2006.06.007 doi: 10.1016/j.jep.2006.06.007
|
| [18] | Prescription identification assistant, The institute of information on traditional Chinese medicine of China academy of Chinese medical sciences, 2021. Available from: http://tcmks.cintcm.com: 81/. |
| [19] |
Q. Hu, T. Yu, J. Li, Q. Yu, L. Zhu, Y. Gu, End-to-End syndrome differentiation of Yin deficiency and Yang deficiency in traditional Chinese medicine, Comput. Methods Programs Biomed., 174 (2019), 9–15. https://doi.org/10.1016/j.cmpb.2018.10.011 doi: 10.1016/j.cmpb.2018.10.011
|
| [20] |
N. Cheng, Y. Chen, W. Gao, J. Liu, Q. Huang, C. Yan, et al., An improved deep learning model: S-TextBLCNN for traditional Chinese medicine formula classification, Front. Genet., 12 (2021). https://doi.org/10.3389/fgene.2021.807825 doi: 10.3389/fgene.2021.807825
|
| [21] |
L. Chen, X. Liu, S. Zhang, H. Yi, Y. Lu, P. Yao, Efficacy-specific herbal group detection from traditional Chinese medicine prescriptions via hierarchical attentive neural network model, BMC Med. Inf. Decis. Making, 21 (2021), 66. https://doi.org/10.1186/s12911-021-01411-2 doi: 10.1186/s12911-021-01411-2
|
| [22] |
X. Yang, C. Ding, SMRGAT: A traditional Chinese herb recommendation model based on a multi-graph residual attention network and semantic knowledge fusion, J. Ethnopharmacol., 315 (2023). https://doi.org/10.1016/j.jep.2023.116693 doi: 10.1016/j.jep.2023.116693
|
| [23] |
Q. Jia, D. Zhang, S. Yang, C. Xia, Y. Shi, H. Tao, et al., Traditional Chinese medicine symptom normalization approach leveraging hierarchical semantic information and text matching with attention mechanism, J. Biomed. Inf., 116 (2021). https://doi.org/10.1016/j.jbi.2021.103718 doi: 10.1016/j.jbi.2021.103718
|
| [24] |
W. T. Huang, H. H. Hung, Y. W. Kao, S. C. Ou, Y. C. Lin, W. Z. Cheng, et al., Application of neural network and cluster analyses to differentiate TCM patterns in patients with breast cancer, Front. Pharmacol., 11 (2020). https://doi.org/10.3389/fphar.2020.00670 doi: 10.3389/fphar.2020.00670
|
| [25] |
G. Xu, H. Jin, Using artificial intelligence technology to solve the electronic health service by processing the online case information, J. Healthcare Eng., 26 (2021). https://doi.org/10.1155/2021/9637018 doi: 10.1155/2021/9637018
|
| [26] |
R. Yuan, Y. Lin, Traditional Chinese medicine: an approach to scientific proof and clinical validation, Pharmacol. Ther., 86 (2000), 191–198. https://doi.org/10.1016/s0163-7258(00)00039-5 doi: 10.1016/s0163-7258(00)00039-5
|
| [27] |
H. Zhang, H. Huang, H. Song, B. Chin, H. Zheng, J. Ruan, et al., Serum metabolomics reveals the intervention mechanism and compatible regularity of Chaihu Shu Gan San on chronic unpredictable mild stress-induced depression rat model, J. Pharm. Pharmacol., 72 (2020), 1133–1143. https://doi.org/10.1111/jphp.13286 doi: 10.1111/jphp.13286
|
| [28] |
C. Zhang, Y. He, T. Li, X. Miao, M. Song, C. Qian, et al., Analysis of chemical components in herbal formula Qi Bai Granule by UPLC-ESI-Q-TOF-MS, Nat. Prod. Res., 33 (2019), 2271–2275. https://doi.org/10.1080/14786419.2018.1495641 doi: 10.1080/14786419.2018.1495641
|
| [29] |
J. Cancela, G. Fico, M. T. Arredondo Waldmeyer, Using the Analytic Hierarchy Process (AHP) to understand the most important factors to design and evaluate a telehealth system for Parkinson's disease, BMC Med. Inf. Decis. Making, 15 (2015), 1–11. https://doi.org/10.1186/1472-6947-15-S3-S7 doi: 10.1186/1472-6947-15-S3-S7
|
| [30] |
X. Zhu, Discovery of traditional Chinese medicine prescription patterns containing herbal dosage based on multilevel Top-K weighted association rules, Comput. Intell. Neurosci., 2022 (2022). https://doi.org/10.1155/2022/5466011 doi: 10.1155/2022/5466011
|
| [31] |
D. Wang, R. Zhao, H. X. Duan, M. M. Zhang, L. He, X. Ye, et al., Research progress regarding potential effects of traditional Chinese medicine on postoperative intestinal obstruction, J. Pharm. Pharmacol., 73 (2021), 1007–1022. https://doi.org/10.1093/jpp/rgaa054 doi: 10.1093/jpp/rgaa054
|
| [32] |
W. Dan, J. Liu, X. Guo, B. Zhang, Y. Qu, Q. He, Study on medication rules of traditional Chinese medicine against antineoplastic drug-induced cardiotoxicity based on network pharmacology and data mining, Evidence-Based Complementary Altern. Med., 2020 (2020). https://doi.org/10.1155/2020/7498525 doi: 10.1155/2020/7498525
|
| [33] |
B. Jang, I. Kim, J. W. Kim, Word2vec convolutional neural networks for classification of news articles and tweets, PLOS ONE, 14 (2019). https://doi.org/10.1371/journal.pone.0220976 doi: 10.1371/journal.pone.0220976
|
| [34] |
S. Akbar, M. Hayat, M. Tahir, S. Khan, F. K. Alarfaj, cACP-DeepGram: Classification of anticancer peptides via deep neural network and skip-gram-based word embedding model, Artif. Intell. Med., 131 (2022). https://doi.org/10.1016/j.artmed.2022.102349 doi: 10.1016/j.artmed.2022.102349
|
| [35] |
Z. Ma, L. Zhao, J. Li, X. Xu, J. Li, SiBERT: A Siamese-based BERT network for Chinese medical entities alignment, Methods, 205 (2022), 133–139. https://doi.org/10.1016/j.ymeth.2022.07.003 doi: 10.1016/j.ymeth.2022.07.003
|
| [36] |
H. Zhao, B. Tao, L. Huang, B. Chen, A siamese network-based approach for vehicle pose estimation, Front. Bioeng. Biotechnol., 10 (2022). https://doi.org/10.3389/fbioe.2022.948726 doi: 10.3389/fbioe.2022.948726
|
| [37] |
Y. Yu, X. Si, C. Hu, J. Zhang, A review of recurrent neural networks: LSTM cells and network architectures, Neural Comput., 31 (2019), 1235–1270. https://doi.org/10.1162/neco_a_01199 doi: 10.1162/neco_a_01199
|
| [38] |
M. Arbane, R. Benlamri, Y. Brik, A. D. Alahmar, Social media-based COVID-19 sentiment classification model using Bi-LSTM, Expert Syst. Appl., 212 (2022). https://doi.org/10.1016/j.eswa.2022.118710 doi: 10.1016/j.eswa.2022.118710
|
| [39] |
K. Liu, W. Gao, Q. Huang, Automatic modulation recognition based on a DCN-BiLSTM network, Sensors, 21 (2021). https://doi.org/10.3390/s21051577 doi: 10.3390/s21051577
|







Figures(8) / Tables(7)

Wangping Xiong, Kaiqi Wang, Shixiong Liu, Zhaoyang Liu, Yimin Zhu, Peng Liu, Ming Yang, Xian Zhou. Multiple prescription pattern recognition model based on Siamese network[J]. Mathematical Biosciences and Engineering, 2023, 20(10): 18695-18716. doi: 10.3934/mbe.2023829







 DownLoad:
DownLoad: