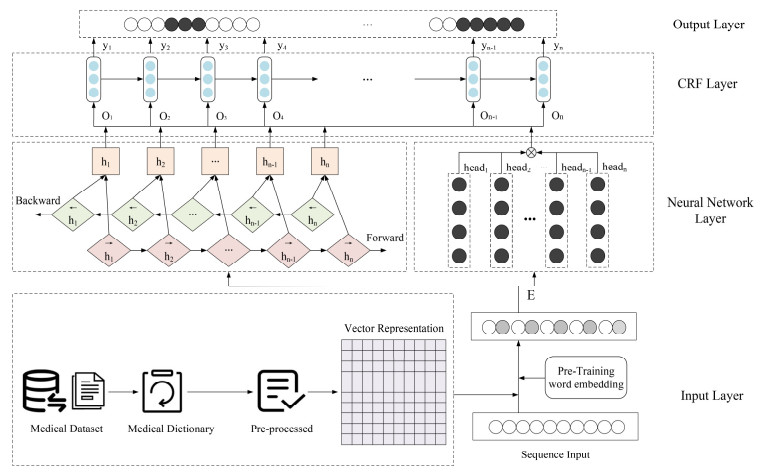
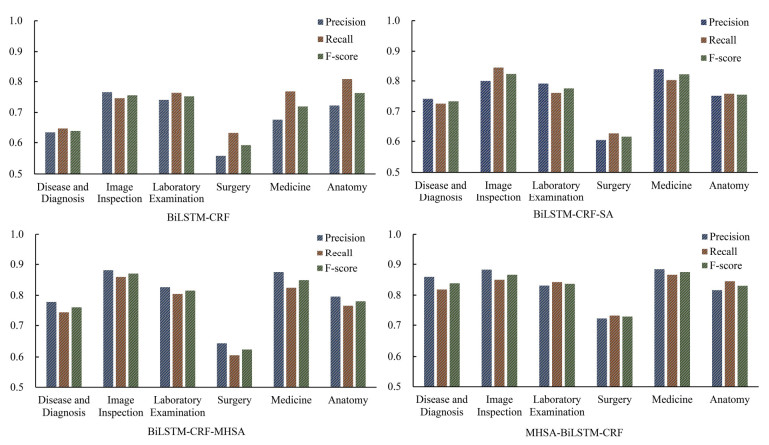
Named entities are the main carriers of relevant medical knowledge in Electronic Medical Records (EMR). Clinical electronic medical records lead to problems such as word segmentation ambiguity and polysemy due to the specificity of Chinese language structure, so a Clinical Named Entity Recognition (CNER) model based on multi-head self-attention combined with BILSTM neural network and Conditional Random Fields is proposed. Firstly, the pre-trained language model organically combines char vectors and word vectors for the text sequences of the original dataset. The sequences are then fed into the parallel structure of the multi-head self-attention module and the BILSTM neural network module, respectively. By splicing the output of the neural network module to obtain multi-level information such as contextual information and feature association weights. Finally, entity annotation is performed by CRF. The results of the multiple comparison experiments show that the structure of the proposed model is very reasonable and robust, and it can effectively improve the Chinese CNER model. The model can extract multi-level and more comprehensive text features, compensate for the defect of long-distance dependency loss, with better applicability and recognition performance.
Citation: Chaofan Li, Kai Ma. Entity recognition of Chinese medical text based on multi-head self-attention combined with BILSTM-CRF[J]. Mathematical Biosciences and Engineering, 2022, 19(3): 2206-2218. doi: 10.3934/mbe.2022103
Named entities are the main carriers of relevant medical knowledge in Electronic Medical Records (EMR). Clinical electronic medical records lead to problems such as word segmentation ambiguity and polysemy due to the specificity of Chinese language structure, so a Clinical Named Entity Recognition (CNER) model based on multi-head self-attention combined with BILSTM neural network and Conditional Random Fields is proposed. Firstly, the pre-trained language model organically combines char vectors and word vectors for the text sequences of the original dataset. The sequences are then fed into the parallel structure of the multi-head self-attention module and the BILSTM neural network module, respectively. By splicing the output of the neural network module to obtain multi-level information such as contextual information and feature association weights. Finally, entity annotation is performed by CRF. The results of the multiple comparison experiments show that the structure of the proposed model is very reasonable and robust, and it can effectively improve the Chinese CNER model. The model can extract multi-level and more comprehensive text features, compensate for the defect of long-distance dependency loss, with better applicability and recognition performance.

| [1] |
W. Lu, Y. Zhang, S. Wang, H. Huang, Q. Liu, S. Luo, Concept representation by learning explicit and implicit concept couplings, IEEE Intell. Syst., 36 (2021), 6–15. https://doi.org/10.1109/MIS.2020.3021188. doi: 10.1109/MIS.2020.3021188

|
| [2] |
N. Zhang, H. Ye, S. Deng, C. Tan, M. Chen, S. Huang, et al., Contrastive information extraction with generative transformer, IEEE/ACM Trans. Audio Speech Lang. Process., 29 (2021), 3077–3088. https://doi.org/10.1109/TASLP.2021.3110126. doi: 10.1109/TASLP.2021.3110126
|
| [3] |
R. Yu, W. Lu, H. Lu, S. Wang, F. Li, X. Zhang, et al., Sentence pair modeling based on semantic feature map for human interaction with IoT devices, Int. J. Mach. Learn. Cybern., 12 (2021), 3081–3099. https://doi.org/10.1007/s13042-021-01349-x. doi: 10.1007/s13042-021-01349-x
|
| [4] |
W. Lu, R. Yu, S. Wang, C. Wang, P. Jian, H. Huang, Sentence semantic matching based on 3D CNN for human–robot language interaction, ACM Trans. Internet Technol., 21 (2021), 1–24. https://doi.org/10.1145/3450520. doi: 10.1145/3450520
|
| [5] |
M. Mohd, R. Jan, M. Shah, Text document summarization using word embedding, Expert Syst. Appl., 143 (2020), 112958. https://doi.org/10.1016/j.eswa.2019.112958. doi: 10.1016/j.eswa.2019.112958
|
| [6] |
W. Li, W. Shao, S. Ji, E. Cambria, BiERU: Bidirectional emotional recurrent unit for conversational sentiment analysis, Neurocomputing, 467 (2022), 73–82. https://doi.org/10.1016/j.neucom.2021.09.057. doi: 10.1016/j.neucom.2021.09.057
|
| [7] | R. Grishman, B. Sundheim, Message understanding conference-6: a brief history, in Proceedings of the 16th conference on Computational linguistics, 1 (1996), 466–471. https://doi.org/10.3115/992628.992709. |
| [8] | M. Collins, Y. Singer, Unsupervised models for named entity classification, in Proceedings of the Joint SIGDA T Conference on Empirical Methods in Natural Language Processing and V ery Large Corpora, (1999), 100–110. |
| [9] |
A. Abbas, E. Varoglu, N. Dimililer, ChemTok: A new rule based tokenizer for chemical named entity recognition, BioMed Res. Int., (2016), 1–9. https://doi.org/10.1155/2016/4248026. doi: 10.1155/2016/4248026
|
| [10] | A. Ratnaparkhi, A Maximum entropy model for part-of-speech tagging, in Conference on Empirical Methods in Natural Language Processing, (1996), 133–142. https://aclanthology.org/W96-0213. |
| [11] | A. Borthwick, A Maximum Entropy Approach to Named Entity Recognition, US, New York University, 1999. |
| [12] | N. Cristianini, J. S. Taylor, An Introduction to Support Vector Machines and Other Kernel-based Learning Methods, UK, Cambridge University Press, 2000. https://doi.org/10.1017/CBO9780511801389. |
| [13] | A. Mccallum, W. Li, Early results for named entity recognition with conditional random fields, feature induction and web-enhanced lexicons, in Proceedings of the 7th Conference on Natural Language Learning at HLT-NAACL, 4 (2003), 188–191. https://doi.org/10.3115/1119176.1119206. |
| [14] |
Q. Pan, C. Huang, D. Chen, A method based on multi-standard active learning to recognize entities in electronic medical record, Math. Biosci. Eng., 18 (2021), 1000–1021. https://doi.org/10.3934/mbe.2021054. doi: 10.3934/mbe.2021054
|
| [15] | R. Collobert, J. Weston, A unified architecture for natural language processing: deep neural networks with multitask learning, in Proceedings of the 25th International Conference on Machine Learning, Helsinki, (2008), 160–167. https://doi.org/10.1145/1390156.1390177. |
| [16] | G. Lample, M. Ballesteros, S. Subramanian, K. Kawakami, C. Dyer, Neural architectures for named entity recognition, in Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, (2016), 260–270. https://doi.org/10.18653/v1/N16-1030. |
| [17] |
R. Y. Zhang, W. P. Lu, S. J. Wang, X. P. Peng, R. Yu, Y. Gao, Chinese clinical named entity recognition based on stacked neural network, Concurrency Comput.: Pract. Exper., 33 (2021). https://doi.org/10.1002/cpe.5775. doi: 10.1002/cpe.5775
|
| [18] |
N. Deng, H. Fu, X. Chen, Named entity recognition of traditional Chinese medicine patents based on BILSTM-CRF, Wireless Commun. Mobile Comput., 2021 (2021). https://doi.org/10.1155/2021/6696205. doi: 10.1155/2021/6696205
|
| [19] | D. Bahdanau, K. Cho, Y. Bengio. Neural machine translation by jointly learning to align and translate, preprint, arXiv: 1409. 0473. |
| [20] |
B. Z. Tang, X. L. Wang, J. Yan, Q. C. Chen, Entity recognition in Chinese clinical text using attention-based CNN-LSTM-CRF, BMC Med. Inf. Decis. Making, 19 (2019), 74. https://doi.org/10.1186/s12911-019-0787-y. doi: 10.1186/s12911-019-0787-y
|
| [21] |
L. Luo, Z. H. Yang, P. Yang, Y. Zhang, L. Wang, H. F. Lin, et al., An attention-based BILSTM-CRF approach to document-level chemical named entity recognition, Bioinformatics, 34 (2018), 1381–1388. https://doi.org/10.1093/bioinformatics/btx761. doi: 10.1093/bioinformatics/btx761
|
| [22] | A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, et al., Attention is all you need, in Proceedings of the 31st International Conference on Neural Information Processing Systems, (2017), 6000–6010. |
| [23] |
J. H. Qiu, Y. M. Zhou, Q. Wang, T. Ruan, J. Gao, Chinese clinical named entity recognition using residual dilated convolutional neural network with conditional random field, IEEE Trans. NanoBioscience, 18 (2019), 306–315. https://doi.org/10.1109/TNB.2019.2908678. doi: 10.1109/TNB.2019.2908678
|
| [24] | Z. Z. Li, Q. Zhang, Y. Liu, D. W. Feng, Z. Huang, Recurrent neural networks with specialized word embedding for Chinese clinical named entity recognition, in Proceedings of the Evaluation Task at the China Conference on Knowledge Graph and Semantic Computing, Berlin, German, Springer, (2017), 55–60. |
| [25] |
X. M. Han, F. Zhou, Z. Y. Hao, Q. M. Liu, Y. Li, Q. Qin, MAF-CNER: A Chinese named entity recognition model based on multifeature adaptive fusion, Complexity, 2021. https://doi.org/10.1155/2021/6696064. doi: 10.1155/2021/6696064
|
| [26] |
N. Ye, X. Qin, L. L. Dong, X. Zhang, K. K. Sun, Chinese named entity recognition based on character-word vector fusion, Wireless Commun. Mobile Comput., 2020. https://doi.org/10.1155/2020/8866540. doi: 10.1155/2020/8866540
|
| [27] |
C. Che, C. J. Zhou, H. Y. Zhao, B. Jin, Z. Gao, Fast and effective biomedical named entity recognition using temporal convolutional network with conditional random field, Math. Biosci. Eng., 17 (2020), 3553–3566. https://doi.org/10.3934/mbe.2020200. doi: 10.3934/mbe.2020200
|
| [28] |
X. Y. Song, A. Feng, W. K. Wang, Z. J. Gao, Multidimensional self-attention for aspect term extraction and biomedical named entity recognition, Math. Probl. Eng., 2020. https://doi.org/10.1155/2020/8604513. doi: 10.1155/2020/8604513
|
Figures(2) / Tables(1)

Chaofan Li, Kai Ma. Entity recognition of Chinese medical text based on multi-head self-attention combined with BILSTM-CRF[J]. Mathematical Biosciences and Engineering, 2022, 19(3): 2206-2218. doi: 10.3934/mbe.2022103







 DownLoad:
DownLoad: