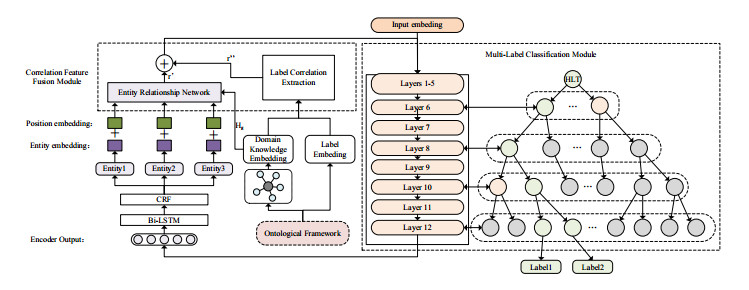
In traditional Chinese medicine (TCM), artificial intelligence (AI)-assisted syndrome differentiation and disease diagnoses primarily confront the challenges of accurate symptom identification and classification. This study introduces a multi-label entity extraction model grounded in TCM symptom ontology, specifically designed to address the limitations of existing entity recognition models characterized by limited label spaces and an insufficient integration of domain knowledge. This model synergizes a knowledge graph with the TCM symptom ontology framework to facilitate a standardized symptom classification system and enrich it with domain-specific knowledge. It innovatively merges the conventional bidirectional encoder representations from transformers (BERT) + bidirectional long short-term memory (Bi-LSTM) + conditional random fields (CRF) entity recognition methodology with a multi-label classification strategy, thereby adeptly navigating the intricate label interdependencies in the textual data. Introducing a multi-associative feature fusion module is a significant advancement, thereby enabling the extraction of pivotal entity features while discerning the interrelations among diverse categorical labels. The experimental outcomes affirm the model's superior performance in multi-label symptom extraction and substantially elevates the efficiency and accuracy. This advancement robustly underpins research in TCM syndrome differentiation and disease diagnoses.
Citation: Hangle Hu, Chunlei Cheng, Qing Ye, Lin Peng, Youzhi Shen. Enhancing traditional Chinese medicine diagnostics: Integrating ontological knowledge for multi-label symptom entity classification[J]. Mathematical Biosciences and Engineering, 2024, 21(1): 369-391. doi: 10.3934/mbe.2024017
In traditional Chinese medicine (TCM), artificial intelligence (AI)-assisted syndrome differentiation and disease diagnoses primarily confront the challenges of accurate symptom identification and classification. This study introduces a multi-label entity extraction model grounded in TCM symptom ontology, specifically designed to address the limitations of existing entity recognition models characterized by limited label spaces and an insufficient integration of domain knowledge. This model synergizes a knowledge graph with the TCM symptom ontology framework to facilitate a standardized symptom classification system and enrich it with domain-specific knowledge. It innovatively merges the conventional bidirectional encoder representations from transformers (BERT) + bidirectional long short-term memory (Bi-LSTM) + conditional random fields (CRF) entity recognition methodology with a multi-label classification strategy, thereby adeptly navigating the intricate label interdependencies in the textual data. Introducing a multi-associative feature fusion module is a significant advancement, thereby enabling the extraction of pivotal entity features while discerning the interrelations among diverse categorical labels. The experimental outcomes affirm the model's superior performance in multi-label symptom extraction and substantially elevates the efficiency and accuracy. This advancement robustly underpins research in TCM syndrome differentiation and disease diagnoses.

| [1] |
Q. Jia, D. Zhang, S. Yang, C. Xia, Y. Shi, H. Tao, et al., Traditional Chinese medicine symptom normalization approach leveraging hierarchical semantic information and text matching with attention mechanism, J. Biomed. Inf., 116 (2021), 103718. https://doi.org/10.1016/j.jbi.2021.103718 doi: 10.1016/j.jbi.2021.103718

|
| [2] |
Z. Huang, J. Miao, J. Chen, Y. Zhong, S. Yang, Y. Ma, et al., A traditional Chinese medicine syndrome classification model based on cross-feature generation by convolution neural network: model development and validation, JMIR Med. Inf., 10 (2022), e29290. https://doi.org/10.2196/29290 doi: 10.2196/29290
|
| [3] |
T. Bai, H. Guan, S. Wang, Y. Wang, L. Huang, Traditional Chinese medicine entity relation extraction based on CNN with segment attention, Neural Comput. Appl., 34 (2022), 2739–2748. https://doi.org/10.1007/s00521-021-05897-9 doi: 10.1007/s00521-021-05897-9
|
| [4] | A. Roy, S. Pan, Incorporating medical knowledge in BERT for clinical relation extraction, in Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, (2021), 5357–5366. https://aclanthology.org/2021.emnlp-main.435 |
| [5] |
P. Chandak, K. Huang, M. Zitnik, Building a knowledge graph to enable precision medicine, Sci. Data, 10 (2023), 67. https://doi.org/10.1038/s41597-023-01960-3 doi: 10.1038/s41597-023-01960-3
|
| [6] |
G. Zhou, E. Haihong, Z. Kuang, L. Tan, X. Xie, J. Li, et al., Clinical decision support system for hypertension medication based on knowledge graph, Comput. Methods Programs Biomed., 227 (2022). https://doi.org/10.1016/j.cmpb.2022.107220 doi: 10.1016/j.cmpb.2022.107220
|
| [7] |
D. Zhang, Q. Jia, S. Yang, X. Han, C. Xu, X. Liu, et al., Traditional Chinese medicine automated diagnosis based on knowledge graph reasoning, Comput. Mater. Contin., 71 (2022). https://doi.org/10.32604/cmc.2022.017295 doi: 10.32604/cmc.2022.017295
|
| [8] |
Y. An, X. Xia, X. Chen, F. X. Wu, J. Wang, Chinese clinical named entity recognition via multi-head self-attention based Bi-LSTM-CRF, Artif. Intell. Med., 127 (2022), 102282. https://doi.org/10.1016/j.artmed.2022.102282 doi: 10.1016/j.artmed.2022.102282
|
| [9] | Y. Ma, Y. Liu, D. Zhang, J. Zhang, H. Liu, Y. Xie, A multigranularity text driven named entity recognition CGAN model for traditional Chinese medicine literatures, Comput. Intell. Neurosci., 2022 (2022), 1495841. |
| [10] |
R. Qi, P. Lv, Q. Zhang, M. Wu, Research on Chinese medical entity recognition based on multi-neural network fusion and improved tri-training algorithm, Appl. Sci., 12 (2022), 8539. https://doi.org/10.3390/app12178539 doi: 10.3390/app12178539
|
| [11] | Y. Li, X. Wang, L. Hui, L. Zou, H. Li, L. Xu, et al., Chinese clinical named entity recognition in electronic medical records: Development of a lattice long short-term memory model with contextualized character representations, JMIR Med. Inf., 8 (2020), e19848. |
| [12] | M. Zhang, J. Wang, X. Zhang, Using a pre-trained language model for medical named entity extraction in Chinese clinic text, in 2020 IEEE 10th International Conference on Electronics Information and Emergency Communication (ICEIEC), IEEE, (2020), 312–317. https://doi.org/10.1109/ICEIEC49280.2020.9152257 |
| [13] |
R. Xie, Y. Wang, D. Peng, X. Liu, X. Su, X. Li, Research on standardization of traditional Chinese medicine symptoms, Henan Tradit. Chin. Med., 7 (2017), 11441146. https://doi.org/10.16367/j.issn.1003-5028.2017.07.0403 doi: 10.16367/j.issn.1003-5028.2017.07.0403
|
| [14] | K. Zhou, J. Dong, S. Wang, G. Li, Y. Zheng, T. Wang, A review of research ideas and methods for standardization of traditional Chinese medicine symptoms in the past 20 years, Glob. Tradit. Chin. Med., 4 (2022), 708–712. |
| [15] | Y. J. Hui, Q. L. Zha, A review of traditional Chinese medicine symptom information extraction, Comput. Eng. Appl., 59 (2023), 35–47. |
| [16] | L. Ma, J. Li, The significance and methodology of standardization of symptom nomenclature, Liaoning J. Tradit. Chin. Med., 37 (2010), 1264–1265. |
| [17] | W. Liu, F. Zhu, Reflections on several issues in the standardization of traditional Chinese medicine symptoms, J. Tradit. Chin. Med., 48 (2007), 555–556. |
| [18] | D. Yan, M. Cui, Exploration of 'symptoms and ssigns' classification in the traditional Chinese medicine clinical terminology system, Chin. J. Med. Libr. Inf. Sci., 10 (2015), 77–80. |
| [19] | Y. Dong, M. Cui, Discussion on the classification of 'symptoms and signs' in the clinical terminology system of traditional Chinese medicine, Chin. J. Med. Libr. Inf. Sci., 24 (2015), 77–80. |
| [20] | X. Ling, D. Weld, Fine-grained entity recognition, in Proceedings of the AAAI Conference on Artificial Intelligence, 26 (2012), 94–100. https://doi.org/10.1609/aaai.v26i1.8122 |
| [21] | K. Pu, H. Liu, Y. Yang, W. Lv, J. Li, Multi-label fine-grained entity typing for baidu Wikipedia based on pre-trained model, in China Conference on Knowledge Graph and Semantic Computing, 1553 (2021), 114–123. https://doi.org/10.1007/978-981-19-0713-5_13 |
| [22] | X. Ren, W. He, M. Qu, Label noise reduction in entity typing by heterogeneous partial-label embedding, in Proceedings of the 22nd ACM SIGKDD international conference on Knowledge discovery and data mining, (2016), 1825–1834. https://doi.org/10.1177/0165551521998048 |
| [23] | Y. Onoe, G. Durrett, Learning to denoise distantly-labeled data for entity typing, preprint, arXiv: 1905.01566. https://doi.org/10.48550/arXiv.1905.01566 |
| [24] | H. Zhang, D. Long, G. Xu, M. Zhu, P. Xie, F. Huang, et al., Learning with noise: improving distantly-supervised fine-grained entity typing via automatic relabeling, in Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, (2021), 3808–3815. https://doi.org/10.24963/ijcai.2020/527 |
| [25] | M. A. Ali, Y. Sun, B. Li, W. Wang, Fine-grained named entity typing over distantly supervised data based on refined representations, in Proceedings of the AAAI Conference on Artificial Intelligence, 34 (2020), 7391–7398. https://doi.org/10.1609/aaai.v34i05.6234 |
| [26] | Y. Prabhu, A. Kag, S. Harsola, R. Agrawal, M. Varma, Parabel: Partitioned label trees for extreme classification with application to dynamic search advertising, in Proceedings of the 2018 World Wide Web Conference, (2018), 993–1002. https://doi.org/10.1145/3178876.3185998 |
| [27] | R. You, Z. Zhang, Z. Wang, S. Dai, H. Mamitsuka, S. Zhu, Attentionxml: Label tree-based attention-aware deep model for high-performance extreme multi-label text classification, Adv. Neural Inf. Process. Syst., 32 (2019). https://arXiv.org/abs/1811.01727 |
| [28] |
J. Zhang, W. C. Chang, H. F. Yu, I. Dhillon, Fast multi-resolution transformer fine-tuning for extreme multi-label text classification, Adv. Neural Inf. Process. Syst., 34 (2021), 7267–7280. https://doi.org/10.48550/arXiv.2110.00685 doi: 10.48550/arXiv.2110.00685
|
| [29] | X. Xiao, Research on Data Elements of Traditional Chinese Medicine Clinical Symptoms Based on Machine Learning, Ph.D. thesis, Hunan University of Traditional Chinese Medicine, 2018. |
| [30] |
N. Zhang, X. Cao, R. Lin, B. Wang, H. Shi, H. Zhou, et al., Research on the normalization of traditional Chinese medicine symptom terms in epilepsy, World Sci. Technol.-Modernization Tradit. Chin. Med., 22 (2020), https://doi.org/10.11842/wst.20190415001 doi: 10.11842/wst.20190415001
|
| [31] | M. Li, Q. Zhou, X. Luo, B. Zhu, Research on the standard and classification system of traditional Chinese medicine symptom terminology, Chin. J. Tradit. Chin. Med. Pharm., 36 (2021), 4838–4842. |
| [32] | E. F. Sang, F. D. Meulder, Introduction to the CoNLL-2003 shared task: Language-independent named entity recognition, preprint, arXiv: cs/0306050. https://doi.org/10.48550/arXiv.cs/0306050 |
| [33] | D. Gillick, N. Lazic, K. Ganchev, J. Kirchner, D. Huynh, Context-dependent fine-grained entity type tagging, preprint, arXiv: 1412.1820. https://doi.org/10.48550/arXiv.1412.1820 |
| [34] | E. Choi, O. Levy, Y. Choi, L. Zettlemoyer, Ultra-fine entity typing, preprint, arXiv: 1807.04905. https://doi.org/10.48550/arXiv.1807.04905 |
| [35] | A. Abhishek, A. Anand, A. Awekar, Fine-grained entity type classification by jointly learning representations and label embeddings, in Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1, Long Papers, (2017), 797–807. https://aclanthology.org/E17-1075 |
| [36] | F. López, M. Strube, A fully hyperbolic neural model for hierarchical multi-class classification, preprint, arXiv: 2010.02053. https://doi.org/10.48550/arXiv.2010.02053 |
| [37] | W. Xiong, J. Wu, D. Lei, M. Yu, S. Chang, X. Guo, et al., Imposing label-relational inductive bias for extremely fine-grained entity typing, preprint, arXiv: 1903.02591. https://doi.org/10.48550/arXiv.1903.02591 |
| [38] |
Y. Fan, J. Liu, J. Tang, P. Liu, Y. Du, Learning correlation information for multi-label feature selection, Pattern Recognit., 2023. https://doi.org/10.1016/j.patcog.2023.109899 doi: 10.1016/j.patcog.2023.109899
|
| [39] |
Y. Fan, J. Liu, P. Liu, Y. Du, W. Lan, S. Wu, Manifold learning with structured subspace for multi-label feature selection, Pattern Recognit., 120 (2021). https://doi.org/10.1016/j.patcog.2021.108169 doi: 10.1016/j.patcog.2021.108169
|
| [40] |
Y. Fan, B. Chen, W. Huang, J. Liu, W. Weng, W. Lan, Multi-label feature selection based on label correlations and feature redundancy, Knowl.-Based Syst., 241 (2022). https://doi.org/10.1016/j.knosys.2022.108256 doi: 10.1016/j.knosys.2022.108256
|
| [41] |
Y. Fan, J. Liu, S. Wu, Exploring instance correlations with local discriminant model for multi-label feature selection, Appl. Intell., 52 (2022), 1–19. https://doi.org/10.1007/s10489-021-02799-0 doi: 10.1007/s10489-021-02799-0
|
| [42] | S. Kharbanda, A. Banerjee, E. Schultheis, R. Babbar, CascadeXML: Rethinking transformers for end-to-end multi-resolution training in extreme multi-label classification, in Part of Advances in Neural Information Processing Systems 35 (NeurIPS 2022), 2022. |
| [43] | J. Sun, F. Yang, W. Deng, Construction of a knowledge representation model for traditional Chinese medicine symptoms based on ontology, J. Med. Inf., 38 (2017). |
| [44] | T. N. Kipf, M. Welling, Semi-supervised classification with graph convolutional networks, preprint, arXiv: 1609.02907. https://doi.org/10.48550/arXiv.1609.02907 |
| [45] | J. Yu, B. Bohnet, M. Poesio, Named entity recognition as dependency parsing, preprint, arXiv: 2005.07150. https://doi.org/10.48550/arXiv.2005.07150 |
| [46] |
R. Yang, Q. Ye, C. Cheng, S. Zhang, Y. Lan, J. Zou, Decision-making system for the diagnosis of syndrome based on traditional Chinese medicine knowledge graph, Evid. Based Complementary Altern. Med., 2022. https://doi.org/10.1155/2022/8693937 doi: 10.1155/2022/8693937
|
| [47] |
N. Deng, H. Fu, X. Chen, Named entity recognition of traditional Chinese medicine patents based on BiLSTM-CRF, Wireless Commun. Mob. Comput, 2021. https://doi.org/10.1155/2021/6696205 doi: 10.1155/2021/6696205
|
| [48] | Q. Qu, H. Kan, Y. Wu, Y. Gao, Named entity recognition of TCM text based on bert model, in 2020 7th International Forum on Electrical Engineering and Automation (IFEEA), 2020. https://doi.org/10.1109/IFEEA51475.2020.00139 |
| [49] | P. Yang, X. Sun, W. Li, S. Ma, W. Wu, H. Wang, SGM: Sequence generation model for multi-label classification, preprint, arXiv: 1806.04822. https://doi.org/10.48550/arXiv.1806.04822 |







Figures(8) / Tables(5)

Hangle Hu, Chunlei Cheng, Qing Ye, Lin Peng, Youzhi Shen. Enhancing traditional Chinese medicine diagnostics: Integrating ontological knowledge for multi-label symptom entity classification[J]. Mathematical Biosciences and Engineering, 2024, 21(1): 369-391. doi: 10.3934/mbe.2024017







 DownLoad:
DownLoad: