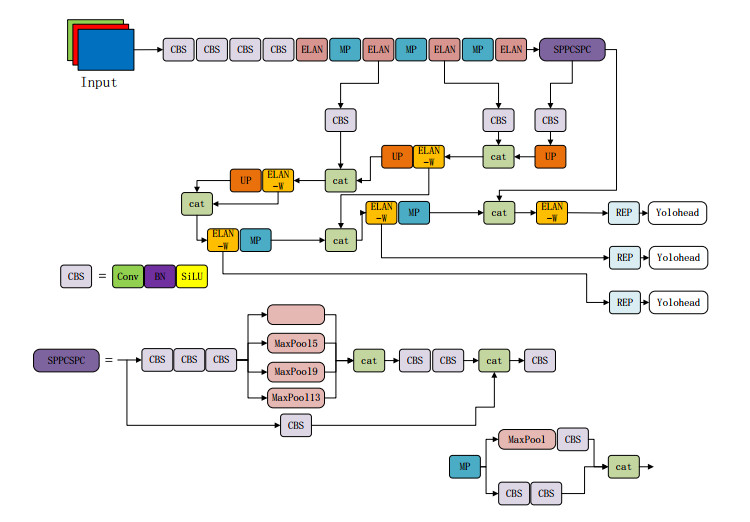
In response to the limited detection ability and low model generalization ability of the YOLOv7 algorithm for small targets, this paper proposes a detection algorithm based on the improved YOLOv7 algorithm for steel surface defect detection. First, the Transformer-InceptionDWConvolution (TI) module is designed, which combines the Transformer module and InceptionDWConvolution to increase the network's ability to detect small objects. Second, the spatial pyramid pooling fast cross-stage partial channel (SPPFCSPC) structure is introduced to enhance the network training performance. Third, a global attention mechanism (GAM) attention mechanism is designed to optimize the network structure, weaken the irrelevant information in the defect image, and increase the algorithm's ability to detect small defects. Meanwhile, the Mish function is used as the activation function of the feature extraction network to improve the model's generalization ability and feature extraction ability. Finally, a minimum partial distance intersection over union (MPDIoU) loss function is designed to locate the loss and solve the mismatch problem between the complete intersection over union (CIoU) prediction box and the real box directions. The experimental results show that on the Northeastern University Defect Detection (NEU-DET) dataset, the improved YOLOv7 network model improves the mean Average precision (mAP) performance by 6% when compared to the original algorithm, while on the VOC2012 dataset, the mAP performance improves by 2.6%. These results indicate that the proposed algorithm can effectively improve the small defect detection performance on steel surface defects.
Citation: Yinghong Xie, Biao Yin, Xiaowei Han, Yan Hao. Improved YOLOv7-based steel surface defect detection algorithm[J]. Mathematical Biosciences and Engineering, 2024, 21(1): 346-368. doi: 10.3934/mbe.2024016
In response to the limited detection ability and low model generalization ability of the YOLOv7 algorithm for small targets, this paper proposes a detection algorithm based on the improved YOLOv7 algorithm for steel surface defect detection. First, the Transformer-InceptionDWConvolution (TI) module is designed, which combines the Transformer module and InceptionDWConvolution to increase the network's ability to detect small objects. Second, the spatial pyramid pooling fast cross-stage partial channel (SPPFCSPC) structure is introduced to enhance the network training performance. Third, a global attention mechanism (GAM) attention mechanism is designed to optimize the network structure, weaken the irrelevant information in the defect image, and increase the algorithm's ability to detect small defects. Meanwhile, the Mish function is used as the activation function of the feature extraction network to improve the model's generalization ability and feature extraction ability. Finally, a minimum partial distance intersection over union (MPDIoU) loss function is designed to locate the loss and solve the mismatch problem between the complete intersection over union (CIoU) prediction box and the real box directions. The experimental results show that on the Northeastern University Defect Detection (NEU-DET) dataset, the improved YOLOv7 network model improves the mean Average precision (mAP) performance by 6% when compared to the original algorithm, while on the VOC2012 dataset, the mAP performance improves by 2.6%. These results indicate that the proposed algorithm can effectively improve the small defect detection performance on steel surface defects.

| [1] |
S. Mei, Y. D. Wang, G. J. Wen, Automatic fabric defect detection with a multi-scale convolutional denoising autoencoder network model, Sensors, 18 (2018), 1064. http://doi.org/10.3390/S18041064 doi: 10.3390/S18041064

|
| [2] |
Z. Q. He, Q. F. Liu, Deep regression neural network for industrial surface defect detection, IEEE Access, 8 (2020), 35583–35591. http://doi.org/10.1109/ACCESS.2020.2975030 doi: 10.1109/ACCESS.2020.2975030
|
| [3] |
J. X. Luo, Z. Y. Yang, S. P. Li, Y. Wu, FPCB surface defect detection: a decoupled two-stage object detection framework, IEEE Trans. Instrum. Meas., 70 (2021). http://doi.org/10.1109/TIM.2021.3092510 doi: 10.1109/TIM.2021.3092510
|
| [4] |
L. H. Shao, E. R. Zhang, Q. R. Ma, M. Li, Pixel-wise semisupervised fabric defect detection method combined with multitask mean teacher, IEEE Trans. Instrum. Meas., 71 (2022). http://doi.org/10.1109/TIM.2022.3162286 doi: 10.1109/TIM.2022.3162286
|
| [5] |
M. Q. Chen, L. J. Yu, C. Zhi, R. Sun, S. Zhu, Z. Gao, et al., Improved faster R-CNN for fabric defect detection based on Gabor filter with genetic algorithm optimization, Comput. Ind., 134 (2022). http://doi.org/10.1016/j.compind.2021.103551 doi: 10.1016/j.compind.2021.103551
|
| [6] | J. Redmon, S. Divvala, R. Girshick, A. Farhadi, You only look once: Unified, real-time object detection, in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2016), 27–30. http://doi.org/10.1109/CVPR.2016.91 |
| [7] | J. Redmon, A. Farhadi, YOLO9000: Better, faster, stronger, in 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), (2017), 21–26. http://doi.org/10.1109/CVPR.2017.690 |
| [8] | J. Redmon, A. Farhadi, YOLOv3: An incremental improvement, preprint, arXiv: 180402767. |
| [9] | A. Bochkovskiy, C. Y. Wang, H. Y. M. Liao, YOLOv4: Optimal speed and accuracy of object detection, preprint, arXiv: 200410934. |
| [10] |
X. H. Qian, X. Wang, S. Y. Yang, J. Lei, LFF-YOLO: A YOLO algorithm with lightweight feature fusion network for multi-scale defect detection, IEEE Access, 10 (2022), 130339–130349. http://doi.org/10.1109/ACCESS.2022.3227205 doi: 10.1109/ACCESS.2022.3227205
|
| [11] | N. Yang, W. Guo, Application of improved YOLOv5 model for strip surface defect detection, in 2022 Global Reliability and Prognostics and Health Management (PHM-Yantai), (2022), 1–5. http://doi.org/10.1109/PHM-Yantai55411.2022.9942194 |
| [12] |
Y. Wan, H. Y. Wang, Z. H. Xin, Efficient detection model of steel strip surface defects based on YOLO-V7, IEEE Access, 10 (2022), 133936–133944. http://doi.org/10.1109/ACCESS.2022.3230894 doi: 10.1109/ACCESS.2022.3230894
|
| [13] | X. Wang, K. Zhuang, An improved YOLOX method for surface defect detection of steel strips, in 2023 IEEE 3rd International Conference on Power, Electronics and Computer Applications (ICPECA), (2022), 152–157. http://doi.org/10.1109/ICPECA56706.2023.10075827 |
| [14] | C. Li, L. Li, H. Jiang, K. Weng, Y. Geng, L. Li, et al., YOLOv6: A single-stage object detection framework for industrial applications, preprint, arXiv: 220902976. |
| [15] | C. Y. Wang, A. Bochkovskiy, H. Y. M. Liao, YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (2023), 7464–7475. http://doi.org/10.48550/arXiv.2207.02696 |
| [16] | F. Akhyar, C. Y. Lin, K. Muchtar, T. Y. Wu, H. F. Ng, High efficient single-stage steel surface defect detection, in 16th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), (2019), 18–21. http://doi.org/10.1109/AVSS.2019.8909834 |
| [17] | V. Nath, C. Chattopadhyay, S2D2Net: An improved approach for robust steel surface defects diagnosis with small sample learning, in IEEE International Conference on Image Processing (ICIP), (2021), 1199–1203. http://doi.org/10.26599/TST.2018.9010090 |
| [18] | A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, et al., Attention is all you need, in Advances in Neural Information Processing Systems, 30 (2017). http://doi.org/10.1109/ICIP42928.2021.9506405 |
| [19] | W. Yu, P. Zhou, S. Yan, X. Wang, Inceptionnext: When inception meets convnext, preprint, arXiv: 230316900. |
| [20] | Y. Liu, Z. Shao, N. Hoffmann, Global attention mechanism: Retain information to enhance channel-spatial interactions, preprint, arXiv: 211205561. |















Figures(16) / Tables(4)

Yinghong Xie, Biao Yin, Xiaowei Han, Yan Hao. Improved YOLOv7-based steel surface defect detection algorithm[J]. Mathematical Biosciences and Engineering, 2024, 21(1): 346-368. doi: 10.3934/mbe.2024016







 DownLoad:
DownLoad: