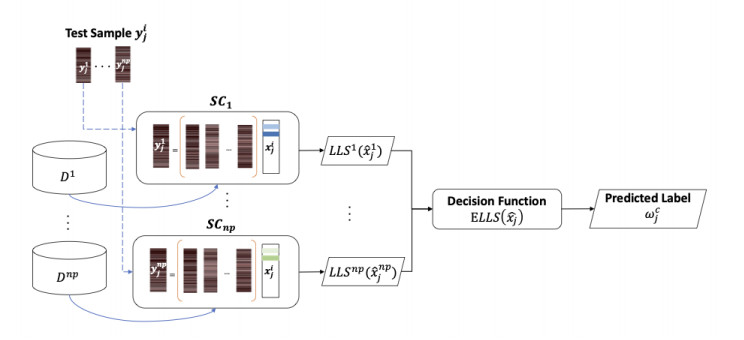
We propose a deep feature-based sparse approximation classification technique for classification of breast masses into benign and malignant categories in film screen mammographs. This is a significant application as breast cancer is a leading cause of death in the modern world and improvements in diagnosis may help to decrease rates of mortality for large populations. While deep learning techniques have produced remarkable results in the field of computer-aided diagnosis of breast cancer, there are several aspects of this field that remain under-studied. In this work, we investigate the applicability of deep-feature-generated dictionaries to sparse approximation-based classification. To this end we construct dictionaries from deep features and compute sparse approximations of Regions Of Interest (ROIs) of breast masses for classification. Furthermore, we propose block and patch decomposition methods to construct overcomplete dictionaries suitable for sparse coding. The effectiveness of our deep feature spatially localized ensemble sparse analysis (DF-SLESA) technique is evaluated on a merged dataset of mass ROIs from the CBIS-DDSM and MIAS datasets. Experimental results indicate that dictionaries of deep features yield more discriminative sparse approximations of mass characteristics than dictionaries of imaging patterns and dictionaries learned by unsupervised machine learning techniques such as K-SVD. Of note is that the proposed block and patch decomposition strategies may help to simplify the sparse coding problem and to find tractable solutions. The proposed technique achieves competitive performances with state-of-the-art techniques for benign/malignant breast mass classification, using 10-fold cross-validation in merged datasets of film screen mammograms.
Citation: Chelsea Harris, Uchenna Okorie, Sokratis Makrogiannis. Spatially localized sparse approximations of deep features for breast mass characterization[J]. Mathematical Biosciences and Engineering, 2023, 20(9): 15859-15882. doi: 10.3934/mbe.2023706
We propose a deep feature-based sparse approximation classification technique for classification of breast masses into benign and malignant categories in film screen mammographs. This is a significant application as breast cancer is a leading cause of death in the modern world and improvements in diagnosis may help to decrease rates of mortality for large populations. While deep learning techniques have produced remarkable results in the field of computer-aided diagnosis of breast cancer, there are several aspects of this field that remain under-studied. In this work, we investigate the applicability of deep-feature-generated dictionaries to sparse approximation-based classification. To this end we construct dictionaries from deep features and compute sparse approximations of Regions Of Interest (ROIs) of breast masses for classification. Furthermore, we propose block and patch decomposition methods to construct overcomplete dictionaries suitable for sparse coding. The effectiveness of our deep feature spatially localized ensemble sparse analysis (DF-SLESA) technique is evaluated on a merged dataset of mass ROIs from the CBIS-DDSM and MIAS datasets. Experimental results indicate that dictionaries of deep features yield more discriminative sparse approximations of mass characteristics than dictionaries of imaging patterns and dictionaries learned by unsupervised machine learning techniques such as K-SVD. Of note is that the proposed block and patch decomposition strategies may help to simplify the sparse coding problem and to find tractable solutions. The proposed technique achieves competitive performances with state-of-the-art techniques for benign/malignant breast mass classification, using 10-fold cross-validation in merged datasets of film screen mammograms.

| [1] |
H. Nagai, Y. H. Kim, Cancer prevention from the perspective of global cancer burden patterns, J. Thorac. Dis., 9 (2017), 448–451. https://doi.org/10.21037/jtd.2017.02.75 doi: 10.21037/jtd.2017.02.75

|
| [2] |
X. Yu, Q. Zhou, S. Wang, Y. D. Zhang, A systematic survey of deep learning in breast cancer, Int. J. Intell. Syst., 37 (2022), 152–216. https://doi.org/10.1002/int.22622 doi: 10.1002/int.22622
|
| [3] | B. S. Chhikara, K. Parang, Global cancer statistics 2022: the trends projection analysis, Chem. Biol. Lett., 10 (2023), 451. |
| [4] | A. G. Waks, E. P. Winer, Breast cancer treatment: a review, Jama, 321 (2019), 288–300. |
| [5] |
E. J. Watkins, Overview of breast cancer, J. Am. Acad. PAs, 32 (2019), 13–17. https://doi.org/10.1097/01.JAA.0000580524.95733.3d doi: 10.1097/01.JAA.0000580524.95733.3d
|
| [6] |
J. G. Elmore, S. L. Jackson, L. Abraham, D. L. Miglioretti, P. A. Carney, B. M. Geller, et al., Variability in interpretive performance at screening mammography and radiologists characteristics associated with accuracy, Radiology, 253 (2009), 641–651. https://doi.org/10.1148/radiol.2533082308 doi: 10.1148/radiol.2533082308
|
| [7] |
M. Caballo, A. M. Hernandez, S. H. Lyu, J. Teuwen, R. M. Mann, B. Van Ginneken, et al., Computer-aided diagnosis of masses in breast computed tomography imaging: deep learning model with combined handcrafted and convolutional radiomic features, J. Med. Imaging, 8 (2021), 024501. https://doi.org/10.1117/1.JMI.8.2.024501 doi: 10.1117/1.JMI.8.2.024501
|
| [8] |
M. M. Eltoukhy, I. Faye, B. B. Samir, A statistical based feature extraction method for breast cancer diagnosis in digital mammogram using multiresolution representation, Comput. Biol. Med., 42 (2012), 123–128. https://doi.org/10.1016/j.compbiomed.2011.10.016 doi: 10.1016/j.compbiomed.2011.10.016
|
| [9] | S. Khan, S. P. Yong, A comparison of deep learning and hand crafted features in medical image modality classification, in 2016 3rd International Conference on Computer and Information Sciences (ICCOINS), (2016), 633–638. https://doi.org/10.1109/ICCOINS.2016.7783289 |
| [10] | L. Ke, N. Mu, Y. Kang, Mass computer-aided diagnosis method in mammogram based on texture features, in 2010 3rd International Conference on Biomedical Engineering and Informatics, (2010), 354–357. https://doi.org/10.1109/BMEI.2010.5639515 |
| [11] |
D. L. Donoho, M. Elad, Optimally sparse representation in general (nonorthogonal) dictionaries via l1 minimization, Proc. Natl. Acad. Sci., 100 (2003), 2197–2202. https://doi.org/10.1073/pnas.0437847100 doi: 10.1073/pnas.0437847100
|
| [12] |
M. Aharon, M. Elad, A. Bruckstein, K-svd: An algorithm for designing overcomplete dictionaries for sparse representation, IEEE Trans. Signal. Process., 54 (2006), 4311–4322. https://doi.org/10.1109/TSP.2006.881199 doi: 10.1109/TSP.2006.881199
|
| [13] |
J. Wright, Y. Ma, J. Mairal, G. Sapiro, T. S. Huang, S. Yan, Sparse representation for computer vision and pattern recognition, Proc. IEEE, 98 (2010), 1031–1044. https://doi.org/10.1109/JPROC.2010.2044470 doi: 10.1109/JPROC.2010.2044470
|
| [14] | E. Plenge, S. S. Klein, W. J. Niessen, E. Meijering, Multiple sparse representations classification, PLos ONE. https://doi.org/10.1371/journal.pone.0131968 |
| [15] |
M. D. Kohli, R. M. Summers, J. R. Geis, Medical image data and datasets in the era of machine learning whitepaper from the 2016 c-mimi meeting dataset session, J. Digit. Imaging, 30 (2017), 392–399. https://doi.org/10.1007/s10278-017-9976-3 doi: 10.1007/s10278-017-9976-3
|
| [16] |
H. E. Kim, A. Cosa-Linan, N. Santhanam, M. Jannesari, M. E. Maros, T. Ganslandt, Transfer learning for medical image classification: A literature review, BMC Med. Imaging, 22 (2022), 69. https://doi.org/10.1186/s12880-022-00793-7 doi: 10.1186/s12880-022-00793-7
|
| [17] |
L. Alzubaidi, M. Al-Amidie, A. Al-Asadi, A. J. Humaidi, O. Al-Shamma, M. A. Fadhel, et al., Novel transfer learning approach for medical imaging with limited labeled data, Cancers, 13 (2021), 1590. https://doi.org/10.3390/cancers13071590 doi: 10.3390/cancers13071590
|
| [18] | D. Lévy, A. Jain, Breast mass classification from mammograms using deep convolutional neural networks, preprint, arXiv: 1612.00542. |
| [19] |
B. Q. Huynh, H. Li, M. L. Giger, Digital mammographic tumor classification using transfer learning from deep convolutional neural networks, J. Med. Imaging, 3 (2016), 034501. https://doi.org/10.1117/1.JMI.3.3.034501 doi: 10.1117/1.JMI.3.3.034501
|
| [20] | F. Jiang, H. Liu, S. Yu, Y. Xie, Breast mass lesion classification in mammograms by transfer learning, in Proceedings of the 5th International Conference on Bioinformatics and Computational Biology, (2017), 59–62. https://doi.org/10.1145/3035012.3035022 |
| [21] |
J. R. Burt, N. Torosdagli, N. Khosravan, H. RaviPrakash, A. Mortazi, F. Tissavirasingham, et al., Deep learning beyond cats and dogs: recent advances in diagnosing breast cancer with deep neural networks, Br. J. Radiol., 91 (2018), 20170545. https://doi.org/10.1259/bjr.20170545 doi: 10.1259/bjr.20170545
|
| [22] |
K. Munir, H. Elahi, A. Ayub, F. Frezza, A. Rizzi, Cancer diagnosis using deep learning: A bibliographic review, Cancers, 11 (2019), 1235. https://doi.org/10.3390/cancers11091235 doi: 10.3390/cancers11091235
|
| [23] |
M. A. Al-Antari, S. M. Han, T. S. Kim, Evaluation of deep learning detection and classification towards computer-aided diagnosis of breast lesions in digital x-ray mammograms, Comput. Methods Programs Biomed., 196 (2020), 105584. https://doi.org/10.1016/j.cmpb.2020.105584 doi: 10.1016/j.cmpb.2020.105584
|
| [24] |
N. Wu, J. Phang, J. Park, Y. Shen, Z. Huang, M. Zorin, et al., Deep neural networks improve radiologists' performance in breast cancer screening, IEEE Trans. Med. Imaging, 39 (2020), 1184–1194. https://doi.org/10.1109/TMI.2019.2945514 doi: 10.1109/TMI.2019.2945514
|
| [25] |
A. Saber, M. Sakr, O. M. Abo-Seida, A. Keshk, H. Chen, A novel deep-learning model for automatic detection and classification of breast cancer using the transfer-learning technique, IEEE Access, 9 (2021), 71194–71209. https://doi.org/10.1109/ACCESS.2021.3079204 doi: 10.1109/ACCESS.2021.3079204
|
| [26] |
Y. Shen, N. Wu, J. Phang, J. Park, K. Liu, S. Tyagi, et al., An interpretable classifier for high-resolution breast cancer screening images utilizing weakly supervised localization, Med. Image Anal., 68 (2021), 101908. https://doi.org/10.1016/j.media.2020.101908 doi: 10.1016/j.media.2020.101908
|
| [27] | C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, et al., Going deeper with convolutions, in Proceedings of the IEEE conference on computer vision and pattern recognition, (2015), 1–9. https://doi.org/10.1109/CVPR.2015.7298594 |
| [28] | C. Szegedy, V. Vanhoucke, S. Ioffe, J. Shlens, Z. Wojna, Rethinking the inception architecture for computer vision, in Proceedings of the IEEE conference on computer vision and pattern recognition, (2016), 2818–2826. https://doi.org/10.1109/CVPR.2016.308 |
| [29] | K. He, X. Zhang, S. Ren, J. Sun, Deep residual learning for image recognition, in Proceedings of the IEEE conference on computer vision and pattern recognition, (2016), 770–778. https://doi.org/10.1109/CVPR.2016.90 |
| [30] | G. Huang, Z. Liu, L. Van Der Maaten, K. Q. Weinberger, Densely connected convolutional networks, in Proceedings of the IEEE conference on computer vision and pattern recognition, (2017), 4700–4708. https://doi.org/10.1109/CVPR.2017.243 |
| [31] | C. Szegedy, S. Ioffe, V. Vanhoucke, A. Alemi, Inception-v4, Inception-ResNet and the impact of residual connections on learning, in Proceedings of the AAAI conference on artificial intelligence, 31 (2017). https://doi.org/10.1609/aaai.v31i1.11231 |
| [32] | F. Chollet, Xception: Deep learning with depthwise separable convolutions, in Proceedings of the IEEE conference on computer vision and pattern recognition, (2017), 1251–1258. https://doi.org/10.1109/CVPR.2017.195 |
| [33] | C. E. Harris, S. Makrogiannis, Breast mass characterization using sparse approximations of patch-sampled deep features, in Medical Imaging 2023: Computer-Aided Diagnosis, 2023. |
| [34] |
K. Zheng, C. Harris, P. Bakic, S. Makrogiannis, Spatially localized sparse representations for breast lesion characterization, Comput. Biol. Med., 123 (2020), 103914. https://doi.org/10.1016/j.compbiomed.2020.103914 doi: 10.1016/j.compbiomed.2020.103914
|
| [35] |
K. Zheng, C. E. Harris, R. Jennane, S. Makrogiannis, Integrative blockwise sparse analysis for tissue characterization and classification, Artif. Intell. Med., 107 (2020), 101885. https://doi.org/10.1016/j.artmed.2020.101885 doi: 10.1016/j.artmed.2020.101885
|
| [36] |
S. Makrogiannis, K. Zheng, C. Harris, Discriminative localized sparse approximations for mass characterization in mammograms, Front. Oncol., 11 (2021), 725320. https://doi.org/10.3389/fonc.2021.725320 doi: 10.3389/fonc.2021.725320
|
| [37] |
A. Oliver, J. Freixenet, J. Marti, E. Perez, J. Pont, E. R. Denton, et al., A review of automatic mass detection and segmentation in mammographic images, Med. Image Anal., 14 (2010), 87–110. https://doi.org/10.1016/j.media.2009.12.005 doi: 10.1016/j.media.2009.12.005
|
| [38] |
B. R. N. Matheus, H. Schiabel, Online mammographic images database for development and comparison of cad schemes, J. Digit. Imaging., 24 (2011), 500–506. https://doi.org/10.1007/s10278-010-9297-2 doi: 10.1007/s10278-010-9297-2
|
| [39] |
R. S. Lee, F. Gimenez, A. Hoogi, K. K. Miyake, M. Gorovoy, D. L. Rubin, A curated mammography data set for use in computer-aided detection and diagnosis research, Sci. Data, 4 (2017), 1–9. https://doi.org/10.1038/sdata.2017.177 doi: 10.1038/sdata.2017.177
|
| [40] |
M. N. Do, M. Vetterli, Framing pyramids, IEEE Trans. Signal Proc., 51 (2003), 2329–2342. https://doi.org/10.1109/TSP.2003.815389 doi: 10.1109/TSP.2003.815389
|
| [41] |
A. Duggento, M. Aiello, C. Cavaliere, G. L. Cascella, D. Cascella, G. Conte, et al., An ad hoc random initialization deep neural network architecture for discriminating malignant breast cancer lesions in mammographic images, Contrast Media Mol. Imaging, 2019 (2019), 5982834. https://doi.org/10.1155/2019/5982834 doi: 10.1155/2019/5982834
|
| [42] | F. Narvaez, A. Rueda, E. Romero, Breast masses classification using a sparse representation, in Proceedings of the 2nd International Workshop on Medical Image Analysis and Description for Diagnosis Systems, (2011), 26–33. |
| [43] |
P. Linardatos, V. Papastefanopoulos, S. Kotsiantis, Explainable AI: A review of machine learning interpretability methods, Entropy, 23 (2020), 18. https://doi.org/10.3390/e23010018 doi: 10.3390/e23010018
|







Figures(8) / Tables(8)

Chelsea Harris, Uchenna Okorie, Sokratis Makrogiannis. Spatially localized sparse approximations of deep features for breast mass characterization[J]. Mathematical Biosciences and Engineering, 2023, 20(9): 15859-15882. doi: 10.3934/mbe.2023706







 DownLoad:
DownLoad: