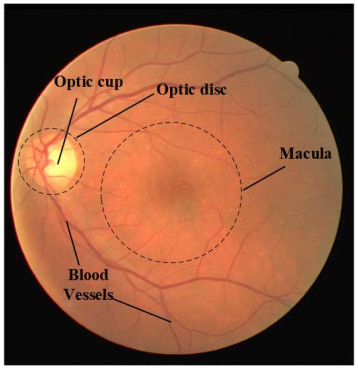
Automatic and fast segmentation of retinal vessels in fundus images is a prerequisite in clinical ophthalmic diseases; however, the high model complexity and low segmentation accuracy still limit its application. This paper proposes a lightweight dual-path cascaded network (LDPC-Net) for automatic and fast vessel segmentation. We designed a dual-path cascaded network via two U-shaped structures. Firstly, we employed a structured discarding (SD) convolution module to alleviate the over-fitting problem in both codec parts. Secondly, we introduced the depthwise separable convolution (DSC) technique to reduce the parameter amount of the model. Thirdly, a residual atrous spatial pyramid pooling (ResASPP) model is constructed in the connection layer to aggregate multi-scale information effectively. Finally, we performed comparative experiments on three public datasets. Experimental results show that the proposed method achieved superior performance on the accuracy, connectivity, and parameter quantity, thus proving that it can be a promising lightweight assisted tool for ophthalmic diseases.
Citation: Yanxia Sun, Xiang Li, Yuechang Liu, Zhongzheng Yuan, Jinke Wang, Changfa Shi. A lightweight dual-path cascaded network for vessel segmentation in fundus image[J]. Mathematical Biosciences and Engineering, 2023, 20(6): 10790-10814. doi: 10.3934/mbe.2023479
Automatic and fast segmentation of retinal vessels in fundus images is a prerequisite in clinical ophthalmic diseases; however, the high model complexity and low segmentation accuracy still limit its application. This paper proposes a lightweight dual-path cascaded network (LDPC-Net) for automatic and fast vessel segmentation. We designed a dual-path cascaded network via two U-shaped structures. Firstly, we employed a structured discarding (SD) convolution module to alleviate the over-fitting problem in both codec parts. Secondly, we introduced the depthwise separable convolution (DSC) technique to reduce the parameter amount of the model. Thirdly, a residual atrous spatial pyramid pooling (ResASPP) model is constructed in the connection layer to aggregate multi-scale information effectively. Finally, we performed comparative experiments on three public datasets. Experimental results show that the proposed method achieved superior performance on the accuracy, connectivity, and parameter quantity, thus proving that it can be a promising lightweight assisted tool for ophthalmic diseases.

| [1] |
S. Chaudhuri, S. Chatterjee, N. Katz, M. Nelson, M. Goldbaum, Detection of blood vessels in retinal images using two-dimensional matched filters, IEEE Trans. Med. Imaging, 8 (1989), 263–269. https://doi.org/10.1109/42.34715 doi: 10.1109/42.34715

|
| [2] |
Q. Li, J. You, D. Zhang, Vessel segmentation and width estimation in retinal images using multi-scale production of matched filter responses, Expert Syst. Appl., 39 (2012), 7600–7610. https://doi.org/10.1016/j.eswa.2011.12.046 doi: 10.1016/j.eswa.2011.12.046
|
| [3] |
K. S. Sreejini, V. K. Govindan, Improved multi-scale matched filter for retina vessel segmentation using PSO algorithm, Egyptian Inf. J., 16 (2015), 253–260. https://doi.org/10.1016/j.eij.2015.06.004 doi: 10.1016/j.eij.2015.06.004
|
| [4] |
S. K. Saroj, R. Kumar, N. P. Singh. Frechet PDF based matched filter approach for retinal blood vessels segmentation, Comput. Methods Programs Biomed., 194 (2020), 105490. https://doi.org/10.1016/j.cmpb.2020.105490 doi: 10.1016/j.cmpb.2020.105490
|
| [5] |
A. M. Aibinu, M. I. Iqbal, A. A. Shafie, M. J. E. Salami, M. Nilsson, Vascular intersection detection in retina fundus images using a new hybrid approach, Comput. Biol. Med., 40 (2010), 81–89. https://doi.org/10.1016/j.compbiomed.2009.11.004 doi: 10.1016/j.compbiomed.2009.11.004
|
| [6] |
M. Vlachos, E. Dermatas, Multi-scale retinal vessel segmentation using line tracking, Comput. Med. Imaging Graphics, 34 (2010), 213–227. https://doi.org/10.1016/j.compmedimag.2009.09.006 doi: 10.1016/j.compmedimag.2009.09.006
|
| [7] |
F. Zana, J. C. Klein, Segmentation of vessel-like patterns using mathematical morphology and curvature evaluation, IEEE Trans. Image Process., 10 (2001), 1010–1019. https://doi.org/10.1109/83.931095 doi: 10.1109/83.931095
|
| [8] |
M. M. Fraz, S. A. Barma, P. Remagnino, A. Hoppe, A. Basit, B. Uyyanonvara, et al., An approach to localize the retinal blood vessels using bit planes and centerline detection, Comput. Methods Programs Biomed., 108 (2012), 600–616. https://doi.org/10.1016/j.cmpb.2011.08.009 doi: 10.1016/j.cmpb.2011.08.009
|
| [9] |
Y. Yang, S. Y. Huang, N. N. Rao, An automatic hybrid method for retinal blood vessel extraction, Int. J. Appl. Math. Comput. Sci., 18 (2008), 399–407. https://doi.org/10.2478/v10006-008-0036-5 doi: 10.2478/v10006-008-0036-5
|
| [10] |
K. Mardani, K. Maghooli, Enhancing retinal blood vessel segmentation in medical images using combined segmentation modes extracted by DBSCAN and morphological reconstruction, Biomed. Signal Process. Control, 69 (2021), 102837. https://doi.org/10.1016/j.bspc.2021.102837 doi: 10.1016/j.bspc.2021.102837
|
| [11] |
J. Staal, M. D. Abràmoff, M. Niemeijer, M. A. Viergever; B. van Ginneken, Ridge-based vessel segmentation in color images of the retina, IEEE Trans. Med. Imaging, 23 (2004), 501–509. https://doi.org/10.1109/TMI.2004.825627 doi: 10.1109/TMI.2004.825627
|
| [12] |
J. V. B. Soares, J. J. G. Leandro, R. M. Cesar, Retinal vessel segmentation using the 2-D morlet wavelet and supervised classification, IEEE Trans. Med. Imaging, 25 (2005). https://doi.org/10.1109/TMI.2006.879967 doi: 10.1109/TMI.2006.879967
|
| [13] |
S. A. Khowaja, P. Khuwaja, I. A. Ismaili, A framework for retinal vessel segmentation from fundus images using hybrid feature set and hierarchical classification, Signal Image Video Process., 13 (2018), 379–387. https://doi.org/10.1007/s11760-018-1366-x doi: 10.1007/s11760-018-1366-x
|
| [14] | O. Ronneberger, P. Fischer, T. Brox, U-net: Convolutional networks for biomedical image segmentation, in International Conference on Medical Image Computing And Computer-assisted Intervention, (2015), 234–241. https://doi.org/10.48550/arXiv.1505.04597 |
| [15] |
J. K. Wang, X. Li, Y. Z. Cheng, Towards an extended efficient net-based u-Net framework for joint optic disc and cup segmentation in the fundus image, Biomed. Signal Process. Control, 85 (2023), 104906. https://doi.org/10.1016/j.bspc.2023.104906 doi: 10.1016/j.bspc.2023.104906
|
| [16] |
B. Yang, L. Qin, H. Peng, C. Guo, X. Luo, J. Wang, SDDC-Net: A U-shaped deep spiking neural P convolutional network for retinal vessel segmentation, Dig. Signal Process., 2023 (2023), 4002. https://doi.org/10.1016/j.dsp.2023.104002 doi: 10.1016/j.dsp.2023.104002
|
| [17] |
G. X. Xu, C. X. Ren, SPNet: A novel deep neural network for retinal vessel segmentation based on shared decoder and pyramid-like loss, Neurocomputing, 523 (2023), 199–212. https://doi.org/10.1016/j.neucom.2022.12.039 doi: 10.1016/j.neucom.2022.12.039
|
| [18] | Y. Wu, Y. Xia, Y. Song, Y. Zhang, W. Cai, Multi-scale network followed network model for retinal vessel segmentation, in International Conference on Medical Image Computing And Computer-Assisted Intervention, (2018), 119–126. https://doi.org/10.1007/978-3-030-00934-2_14 |
| [19] | J. Zhuang, LadderNet: Multi-path networks based on u-Net for medical image segmentation, preprint, arXiv: 1810.07810. |
| [20] |
M. Z. Alom, C. Yakopcic, M. Hasan, T. M. Taha, V. K. Asari, Recurrent residual u-Net for medical image segmentation, J. Med. Imaging, 6 (2019), 6–14. https://doi.org/10.1117/1.JMI.6.1.014006 doi: 10.1117/1.JMI.6.1.014006
|
| [21] | L. Li, M. Verma, Y. Nakashima, H. Nagahara, R. Kawasaki, IterNet: Retinal image segmentation utilizing structural redundancy in vessel networks, in IEEE Winter Conference on Applications of Computer Vision, (2020). https://doi.org/10.48550/arXiv.1912.05763 |
| [22] |
Z. Gu, J. Cheng, H. Fu, K. Zhou, H. Hao, Y. Zhao, CE-Net: Context encoder network for 2D medical image segmentation, IEEE Trans. Med. Imaging, (2019). https://doi.org/10.1109/TMI.2019.2903562 doi: 10.1109/TMI.2019.2903562
|
| [23] |
Z. F. Lin, J. P. Huang, Y. Y Chen, X. Zhang, W. Zhao, Y. Li, et al., A high resolution representation network with multi-path scale for retinal vessel segmentation, Comput. Methods Programs Biomed., 208 (2021). https://doi.org/10.1016/j.cmpb.2021.106206 doi: 10.1016/j.cmpb.2021.106206
|
| [24] |
X. Li, Y. Jiang, M. Li, S. Yin, Lightweight attention convolutional neural network for retinal vessel image segmentation, IEEE Trans. Ind. Inf., 17 (2021), 1958–1967. https://doi.org/10.1109/TII.2020.2993842 doi: 10.1109/TII.2020.2993842
|
| [25] |
Y. Zhang, J. Fang, Y. Chen, L. Jia, Edge-aware U-net with gated convolution for retinal vessel segmentation, Biomed. Signal Process. Control, 73 (2022), 103472. https://doi.org/10.1016/j.bspc.2021.103472 doi: 10.1016/j.bspc.2021.103472
|
| [26] |
X. Deng, J. Ye, A retinal blood vessel segmentation based on improved D-MNet and pulse-coupled neural network, Biomed. Signal Process. Control, 73 (2022), 103467. https://doi.org/10.1016/j.bspc.2021.103467 doi: 10.1016/j.bspc.2021.103467
|
| [27] |
J. He, Q. Zhu, K. Zhang, P. Yu, J. Tang, An evolvable adversarial network with gradient penalty for COVID-19 infection segmentation, Appl. Soft Comput., 113 (2021), 107947. https://doi.org/10.1016/j.asoc.2021.107947 doi: 10.1016/j.asoc.2021.107947
|
| [28] |
N. Mu, H. Wang, Y. Zhang, J. Jiang, J. Tang, Progressive global perception and local polishing network for lung infection segmentation of COVID-19 CT images, Pattern Recognit., 120 (2021), 108168. https://doi.org/10.1016/j.patcog.2021.108168 doi: 10.1016/j.patcog.2021.108168
|
| [29] |
C. Zhao, A. Vij, S Malhotra, J. Tang, H. Tang, D. Pienta, et al., Automatic extraction and stenosis evaluation of coronary arteries in invasive coronary angiograms, Comput. Biol. Med., 136 (2021), 104667. https://doi.org/10.1016/j.compbiomed.2021.104667 doi: 10.1016/j.compbiomed.2021.104667
|
| [30] |
X. Liu, Z. Guo, J. Cao, J. Tang, MDC-net: A new convolutional neural network for nucleus segmentation in histopathology images with distance maps and contour information, Comput. Biol. Med., 135 (2021), 104543. https://doi.org/10.1016/j.compbiomed.2021.104543 doi: 10.1016/j.compbiomed.2021.104543
|
| [31] |
Y. Wu., Y. Xia., Y. Song. Y. Zhang, W Cai, NFN+: a novel network followed network for retinal vessel segmentation, Neural Networks, 126 (2020), 153–162. https://doi.org/10.1016/j.neunet.2020.02.018 doi: 10.1016/j.neunet.2020.02.018
|
| [32] |
G. Ghiasi, T. Y. Lin, Q. V. Le, Dropblock: a regularization method for convolutional networks, Adv. Neural Inf. Process. Syst., 31 (2018). https://doi.org/10.48550/arXiv.1810.12890 doi: 10.48550/arXiv.1810.12890
|
| [33] |
Q. Jin, Z. Meng, T. D. Pham, Q. Chen, L. Wei, R. Su, DUNet: a deformable network for retinal vessel segmentation, Knowl. Based Syst., 178 (2019), 149–162. https://doi.org/10.1016/j.knosys.2019.04.025 doi: 10.1016/j.knosys.2019.04.025
|
| [34] | F. Chollet, Xception: Deep learning with depthwise separable convolutions, in Proceedings of the IEEE conference on computer vision and pattern recognition, (2017), 1251–1258. https://doi.org/10.48550/arXiv.1610.02357 |
| [35] |
L. Mou, L. Chen, J. Cheng, Z. Gu, Y. Zhao, J. Liu, Dense dilated network with probability regularized walk for vessel detection, IEEE Trans. Med. Imaging, 39 (2020), 1392–1403. https://doi.org/10.1109/TMI.2019.2950051 doi: 10.1109/TMI.2019.2950051
|
| [36] |
Z. Yan, X. Yang, K. T. Cheng, A three-stage deep learning model for accurate retinal vessel segmentation, biomedical and health informatics, IEEE J. Biomed. Health Inf., 23 (2019), 1427–1436. https://doi.org/10.1109/JBHI.2018.2872813 doi: 10.1109/JBHI.2018.2872813
|
| [37] |
V. Badrinarayanan, A. Kendall, R. Cipolla, Segnet: a deep convolutional encoder-decoder architecture for image segmentation, IEEE Trans. Pattern Anal. Mach. Intell., 39 (2017): 2481–2495. https://doi.org/10.1109/TPAMI.2016.2644615 doi: 10.1109/TPAMI.2016.2644615
|
| [38] | J. Long, E. Shelhamer, T. Darrell, Fully convolutional networks for semantic segmentation, in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (2014). https://doi.org/10.1109/TPAMI.2016.2572683 |
| [39] |
N. Ibtehaz, M. S. Rahman, MultiResUNet: Rethinking the u-Net architecture for multimodal biomedical image segmentation, Neural Networks, 121 (2020), 74–87. https://doi.org/10.1016/j.neunet.2019.08.025 doi: 10.1016/j.neunet.2019.08.025
|
| [40] | A. Chaurasia, E. Culurciello, Linknet: Exploiting encoder representations for efficient semantic segmentation, in 2017 IEEE Visual Communications and Image Processing (VCIP), (2017), 1–4. https://doi.org/10.1109/VCIP.2017.8305148 |
| [41] | L. C. Chen, Y. Zhu, G. Papandreou, F. Schroff, H. Adam, Encoder-decoder with atrous separable convolution for semantic image segmentation, in Proceedings of the European Conference on Computer Vision, (2018), 801–818. https://doi.org/10.48550/arXiv.1802.02611 |
| [42] | O. Papandreou, J. Schlemper, L. L. Folgoc, M. Lee, M. Heinrich, K. Misawa, et al., Attention u-net: Learning where to look for the pancreas, preprint, arXiv: 1804.03999. |
| [43] |
A. Glowacz, Thermographic fault diagnosis of shaft of BLDC motor, Sensors, 22 (2022), 8537. https://doi.org/10.3390/s22218537 doi: 10.3390/s22218537
|
| [44] |
A. Glowacz, Fault diagnosis of electric impact drills using thermal imaging, Measurement, 171 (2021), 108815. https://doi.org/10.1016/j.measurement.2020.108815 doi: 10.1016/j.measurement.2020.108815
|













Figures(14) / Tables(5)

Yanxia Sun, Xiang Li, Yuechang Liu, Zhongzheng Yuan, Jinke Wang, Changfa Shi. A lightweight dual-path cascaded network for vessel segmentation in fundus image[J]. Mathematical Biosciences and Engineering, 2023, 20(6): 10790-10814. doi: 10.3934/mbe.2023479







 DownLoad:
DownLoad: