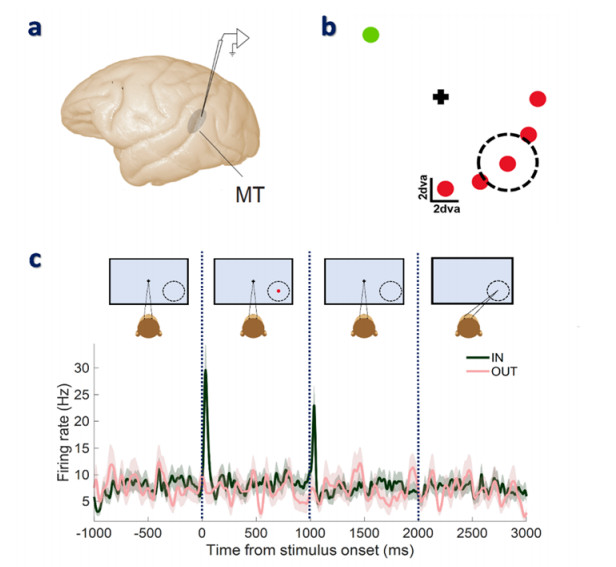
Neural signatures of working memory have been frequently identified in the spiking activity of different brain areas. However, some studies reported no memory-related change in the spiking activity of the middle temporal (MT) area in the visual cortex. However, recently it was shown that the content of working memory is reflected as an increase in the dimensionality of the average spiking activity of the MT neurons. This study aimed to find the features that can reveal memory-related changes with the help of machine-learning algorithms. In this regard, different linear and nonlinear features were obtained from the neuronal spiking activity during the presence and absence of working memory. To select the optimum features, the Genetic algorithm, Particle Swarm Optimization, and Ant Colony Optimization methods were employed. The classification was performed using the Support Vector Machine (SVM) and the K-Nearest Neighbor (KNN) classifiers. Our results suggest that the deployment of spatial working memory can be perfectly detected from spiking patterns of MT neurons with an accuracy of 99.65±0.12 using the KNN and 99.50±0.26 using the SVM classifiers.
Citation: Gayathri Vivekanandhan, Mahtab Mehrabbeik, Karthikeyan Rajagopal, Sajad Jafari, Stephen G. Lomber, Yaser Merrikhi. Applying machine learning techniques to detect the deployment of spatial working memory from the spiking activity of MT neurons[J]. Mathematical Biosciences and Engineering, 2023, 20(2): 3216-3236. doi: 10.3934/mbe.2023151
Neural signatures of working memory have been frequently identified in the spiking activity of different brain areas. However, some studies reported no memory-related change in the spiking activity of the middle temporal (MT) area in the visual cortex. However, recently it was shown that the content of working memory is reflected as an increase in the dimensionality of the average spiking activity of the MT neurons. This study aimed to find the features that can reveal memory-related changes with the help of machine-learning algorithms. In this regard, different linear and nonlinear features were obtained from the neuronal spiking activity during the presence and absence of working memory. To select the optimum features, the Genetic algorithm, Particle Swarm Optimization, and Ant Colony Optimization methods were employed. The classification was performed using the Support Vector Machine (SVM) and the K-Nearest Neighbor (KNN) classifiers. Our results suggest that the deployment of spatial working memory can be perfectly detected from spiking patterns of MT neurons with an accuracy of 99.65±0.12 using the KNN and 99.50±0.26 using the SVM classifiers.

| [1] |
A. E. Maxwell, T. A. Warner, F. Fang, Implementation of machine-learning classification in remote sensing: An applied review, Int. J. Remote Sens., 39 (2018), 2784–2817. https://doi.org/10.1080/01431161.2018.1433343 doi: 10.1080/01431161.2018.1433343

|
| [2] |
D. Maulud, A. M. Abdulazeez, A review on linear regression comprehensive in machine learning, J. Appl. Sci. Technol. Trends, 1 (2020), 140–147. https://doi.org/10.38094/jastt1457 doi: 10.38094/jastt1457
|
| [3] |
S. Sun, Z. Cao, H. Zhu, J. Zhao, A survey of optimization methods from a machine learning perspective, IEEE Trans. Cybern., 50 (2019), 3668–3681. https://doi.org/10.1109/TCYB.2019.2950779 doi: 10.1109/TCYB.2019.2950779
|
| [4] |
I. M. Ibrahim, A. M. Abdulazeez, The role of machine learning algorithms for diagnosing diseases, J. Appl. Sci. Technol. Trends, 2 (2021), 10–19. https://doi.org/10.38094/jastt20179 doi: 10.38094/jastt20179
|
| [5] |
J. Wang, M. Wang, Review of the emotional feature extraction and classification using EEG signals, Cognit. Rob., 1 (2021), 29–40. https://doi.org/10.1016/j.cogr.2021.04.001 doi: 10.1016/j.cogr.2021.04.001
|
| [6] |
A. I. Kadhim, Survey on supervised machine learning techniques for automatic text classification, Artif. Intell. Rev., 52 (2019), 273–292. https://doi.org/10.1007/s10462-018-09677-1 doi: 10.1007/s10462-018-09677-1
|
| [7] |
C. Jobanputra, J. Bavishi, N. Doshi, Human activity recognition: A survey, Procedia Comput. Sci., 155 (2019), 698–703. https://doi.org/10.1016/j.procs.2019.08.100 doi: 10.1016/j.procs.2019.08.100
|
| [8] |
O. Karabiber Cura, S. Kocaaslan Atli, H. S. Türe, A. Akan, Epileptic seizure classifications using empirical mode decomposition and its derivative, Biomed. Eng. Online, 19 (2020), 1–22. https://doi.org/10.1186/s12938-020-0754-y doi: 10.1186/s12938-020-0754-y
|
| [9] |
R. Zebari, A. Abdulazeez, D. Zeebaree, D. Zebari, J. Saeed, A comprehensive review of dimensionality reduction techniques for feature selection and feature extraction, J. Appl. Sci. Technol. Trends, 1 (2020), 56–70. https://doi.org/10.38094/jastt1224 doi: 10.38094/jastt1224
|
| [10] |
H. Namazi, A. Daneshi, H. Azarnoush, S. Jafari, F. Towhidkhah, Fractal-based analysis of the influence of auditory stimuli on eye movements, Fractals, 26 (2018), 1850040. https://doi.org/10.1142/S0218348X18500408 doi: 10.1142/S0218348X18500408
|
| [11] |
H. Alipour, F. Towhidkhah, S. Jafari, A. Menon, H. Namazi, Complexity-based analysis of the relation between fractal visual stimuli and fractal eye movements, Fluctuation Noise Lett., 18 (2019), 1950012. https://doi.org/10.1142/S0219477519500123 doi: 10.1142/S0219477519500123
|
| [12] |
H. Namazi, E. Aghasian, T. S. Ala, Fractal-based classification of electroencephalography (EEG) signals in healthy adolescents and adolescents with symptoms of schizophrenia, Technol. Health Care, 27 (2019), 233–241. https://doi.org/10.3233/THC-181497 doi: 10.3233/THC-181497
|
| [13] |
H. Namazi, R. Khosrowabadi, J. Hussaini, S. Habibi, A. Farid, V. V. Kulish, Analysis of the influence of memory content of auditory stimuli on the memory content of EEG signal, Oncotarget, 7 (2016), 56120–56128. https://doi.org/10.18632/oncotarget.11234 doi: 10.18632/oncotarget.11234
|
| [14] |
A. Narin, Y. Isler, M. Ozer, M. Perc, Early prediction of paroxysmal atrial fibrillation based on short-term heart rate variability, Physica A, 509 (2018), 56–65. https://doi.org/10.1016/j.physa.2018.06.022 doi: 10.1016/j.physa.2018.06.022
|
| [15] |
Y. Isler, A. Narin, M. Ozer, M. Perc, , Multi-stage classification of congestive heart failure based on short-term heart rate variability, Chaos, Solitons Fractals, 118 (2019), 145–151. https://doi.org/10.1016/j.chaos.2018.11.020 doi: 10.1016/j.chaos.2018.11.020
|
| [16] |
M. Mehrabbeik, S. Rashidi, A. Fallah, E. R. Khoshnood, Phonocardiography-based mitral valve prolapse detection with using fractional fourier transform, Biomed. Phys. Eng. Express, 7 (2020), 015003. https://doi.org/10.1088/2057-1976/abcaab doi: 10.1088/2057-1976/abcaab
|
| [17] |
S. Ansari Nasab, S. Panahi, F. Ghassemi, S. Jafari, K. Rajagopal, D. Ghosh, et al., Functional neuronal networks reveal emotional processing differences in children with ADHD, Cogn. Neurodyn., 16 (2022), 91–100. https://doi.org/10.1007/s11571-021-09699-6 doi: 10.1007/s11571-021-09699-6
|
| [18] |
Y. Merrikhi, K. Clark, B. Noudoost, Concurrent influence of top-down and bottom-up inputs on correlated activity of Macaque extrastriate neurons, Nat. Commun., 9 (2018), 5393. https://doi.org/10.1038/s41467-018-07816-4 doi: 10.1038/s41467-018-07816-4
|
| [19] |
Y. Merrikhi, K. Clark, E. Albarran, M. Parsa, M. Zirnsak, T. Moore, et al., Spatial working memory alters the efficacy of input to visual cortex, Nat. Commun., 8 (2017), 15041. https://doi.org/10.1038/ncomms15041 doi: 10.1038/ncomms15041
|
| [20] |
Y. Merrikhi, M. Shams-Ahmar, H. Karimi-Rouzbahani, K. Clark, R. Ebrahimpour, B. Noudoost, Dissociable contribution of extrastriate responses to representational enhancement of gaze targets, J. Cognit. Neurosci., 33 (2021), 2167–2180. https://doi.org/10.1162/jocn_a_01750 doi: 10.1162/jocn_a_01750
|
| [21] |
D. Zaksas, T. Pasternak, Directional signals in the prefrontal cortex and in area MT during a working memory for visual motion task, J. Neurosci., 26 (2006), 11726–11742. https://doi.org/10.1523/JNEUROSCI.3420-06.2006 doi: 10.1523/JNEUROSCI.3420-06.2006
|
| [22] |
J. W. Bisley, D. Zaksas, J. A. Droll, T. Pasternak, Activity of neurons in cortical area MT during a memory for motion task, J. Neurophysiol., 91 (2004), 286–300. https://doi.org/10.1152/jn.00870.2003 doi: 10.1152/jn.00870.2003
|
| [23] |
L. Chelazzi, E. K. Miller, J. Duncan, R. Desimone, Responses of neurons in macaque area V4 during memory-guided visual search, Cereb. Cortex, 11 (2001), 761–772. https://doi.org/10.1093/cercor/11.8.761 doi: 10.1093/cercor/11.8.761
|
| [24] |
M. Mehrabbeik, M. Shams-Ahmar, A. T. Levine, S. Jafari, Y. Merrikhi, Distinctive nonlinear dimensionality of neural spiking activity in extrastriate cortex during spatial working memory; a Higuchi fractal analysis, Chaos, Solitons Fractals, 158 (2022), 112051. https://doi.org/10.1016/j.chaos.2022.112051 doi: 10.1016/j.chaos.2022.112051
|
| [25] |
D. Mendoza-Halliday, S. Torres, J. C. Martinez-Trujillo, Sharp emergence of feature-selective sustained activity along the dorsal visual pathway, Nat. Neurosci., 17 (2014), 1255–1262. https://doi.org/10.1038/nn.3785 doi: 10.1038/nn.3785
|
| [26] |
K. M. Armstrong, M. H. Chang, T. Moore, Selection and maintenance of spatial information by frontal eye field neurons, J. Neurosci., 29 (2009), 15621–15629. https://doi.org/10.1523/JNEUROSCI.4465-09.2009 doi: 10.1523/JNEUROSCI.4465-09.2009
|
| [27] |
X. Zhou, F. Katsuki, X. L. Qi, C. Constantinidis, Neurons with inverted tuning during the delay periods of working memory tasks in the dorsal prefrontal and posterior parietal cortex, J. Neurophysiol., 108 (2012), 31–38. https://doi.org/10.1152/jn.01151.2011 doi: 10.1152/jn.01151.2011
|
| [28] |
Z. Bahmani, M. R. Daliri, Y. Merrikhi, K. Clark, B. Noudoost, Working memory enhances cortical representations via spatially specific coordination of spike times, Neuron, 97 (2018), 967–979. https://doi.org/10.1016/j.neuron.2018.01.012 doi: 10.1016/j.neuron.2018.01.012
|
| [29] |
R. Esteller, G. Vachtsevanos, J. Echauz, B. Litt, A comparison of waveform fractal dimension algorithms, IEEE Trans. Circuits. Syst. I Fundam. Theor. Appl., 48 (2001), 177–183. https://doi.org/10.1109/81.904882 doi: 10.1109/81.904882
|
| [30] |
T. Higuchi, Approach to an irregular time series on the basis of the fractal theory, Physica D, 31 (1988), 277–283. https://doi.org/10.1016/0167-2789(88)90081-4 doi: 10.1016/0167-2789(88)90081-4
|
| [31] |
M. J. Katz, Fractals and the analysis of waveforms, Comput. Biol. Med., 18 (1988), 145–156. https://doi.org/10.1016/0010-4825(88)90041-8 doi: 10.1016/0010-4825(88)90041-8
|
| [32] |
R. Morales, T. Di Matteo, R. Gramatica, T. Aste, Dynamical generalized Hurst exponent as a tool to monitor unstable periods in financial time series, Physica A, 391 (2012), 3180–3189. https://doi.org/10.1016/j.physa.2012.01.004 doi: 10.1016/j.physa.2012.01.004
|
| [33] |
C. Gómez, R. Hornero, Entropy and complexity analyses in Alzheimer's disease: An MEG study, Open Biomed. Eng. J., 4 (2010), 223–235. https://doi.org/10.2174/1874120701004010223 doi: 10.2174/1874120701004010223
|
| [34] |
P. Maragos, F. K. Sun, Measuring the fractal dimension of signals: Morphological covers and iterative optimization, IEEE Trans. Signal Process., 41 (1993), 108. https://doi.org/10.1109/TSP.1993.193131 doi: 10.1109/TSP.1993.193131
|
| [35] |
L. S. Liebovitch, T. Toth, A fast algorithm to determine fractal dimensions by box counting, Phys. Lett. A, 141 (1989), 386–390. https://doi.org/10.1016/0375-9601(89)90854-2 doi: 10.1016/0375-9601(89)90854-2
|
| [36] |
B. Klinkenberg, A review of methods used to determine the fractal dimension of linear features, Math. Geol., 26 (1994), 23–46. https://doi.org/10.1007/BF02065874 doi: 10.1007/BF02065874
|
| [37] |
K. Suganthi, G. Jayalalitha, Geometric brownian motion in stock prices, J. Phys. Conf. Ser., 1377 (2019), 012016. https://doi.org/10.1088/1742-6596/1377/1/012016 doi: 10.1088/1742-6596/1377/1/012016
|
| [38] | R. M. Rangayyan, Biomedical Signal Analysis, John Wiley & Sons, 2015. https://doi.org/10.1002/9781119068129 |
| [39] |
H. H. Giv, Directional short-time Fourier transform, J. Math. Anal. Appl., 399 (2013), 100–107. https://doi.org/10.1016/j.jmaa.2012.09.053 doi: 10.1016/j.jmaa.2012.09.053
|
| [40] |
R. G. Stockwell, L. Mansinha, R. P. Lowe, Localization of the complex spectrum: the S transform, IEEE Trans. Signal Process., 44 (1996), 998–1001. https://doi.org/10.1109/78.492555 doi: 10.1109/78.492555
|
| [41] |
V. Kumar, S. Minz, Feature selection: a literature review, Smart Comput. Rev., 4 (2014), 211–229. https://doi.org/10.6029/smartcr.2014.03.007 doi: 10.6029/smartcr.2014.03.007
|
| [42] | L. Haldurai, T. Madhubala, R. Rajalakshmi, A study on genetic algorithm and its applications, Int. J. Comput. Sci. Eng., 4 (2016), 139. |
| [43] |
B. Xue, M. Zhang, W. N. Browne, Particle Swarm Optimization for feature selection in classification: A multi-objective approach, IEEE Trans. Cybern., 43 (2013), 1656–1671. https://doi.org/10.1109/TSMCB.2012.2227469 doi: 10.1109/TSMCB.2012.2227469
|
| [44] |
B. Chen, L. Chen, Y. Chen, Efficient ant colony optimization for image feature selection, Signal Process., 93 (2013), 1566–1576. https://doi.org/10.1016/j.sigpro.2012.10.022 doi: 10.1016/j.sigpro.2012.10.022
|
| [45] |
A. A. B. Pessa, R. S. Zola, M. Perc, H. V. Ribeiro, Determining liquid crystal properties with ordinal networks and machine learning, Chaos, Solitons Fractals, 154 (2022), 111607. https://doi.org/10.1016/j.chaos.2021.111607 doi: 10.1016/j.chaos.2021.111607
|






Figures(7) / Tables(4)

Gayathri Vivekanandhan, Mahtab Mehrabbeik, Karthikeyan Rajagopal, Sajad Jafari, Stephen G. Lomber, Yaser Merrikhi. Applying machine learning techniques to detect the deployment of spatial working memory from the spiking activity of MT neurons[J]. Mathematical Biosciences and Engineering, 2023, 20(2): 3216-3236. doi: 10.3934/mbe.2023151







 DownLoad:
DownLoad: