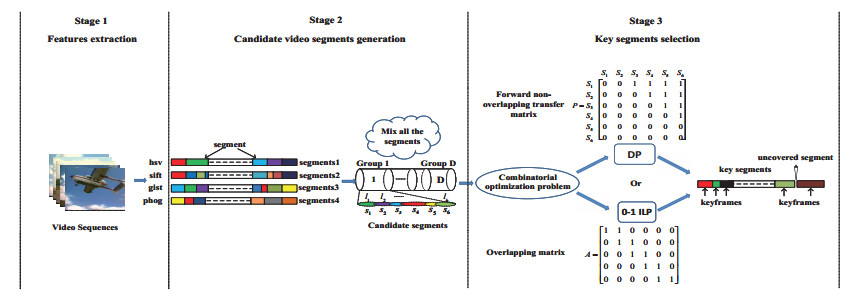
Recent advancements in network and multimedia technologies have facilitated the distribution and sharing of digital videos over the Internet. These long videos contain very complex contents. Additionally, it is very challenging to use as few frames as possible to cover the video contents without missing too much information. There are at least two ways to describe these complex videos contents with minimal frames: the keyframes extracted from the video or the video summary. The former lays stress on covering the whole video contents as much as possible. The latter emphasizes covering the video contents of interest. As a consequence, keyframes are widely used in many areas such as video segmentation and object tracking. In this paper, we propose a keyframe extraction method based on multiple features via a novel combinatorial optimization algorithm. The key frame extraction is modeled as a combinatorial optimization problem. A fast dynamic programming algorithm based on a forward non-overlapping transfer matrix in polynomial time and a 0-1 integer linear programming algorithm based on an overlapping matrix is proposed to solve our maximization problem. In order to quantitatively evaluate our approach, a long video dataset named 'Animal world' is self-constructed, and the segmentation evaluation criterions are introduced. A good result is achieved on 'Animal world' dataset and a public available Keyframe-Sydney KFSYD dataset [
Citation: Lei Ma, Weiyu Wang, Yaozong Zhang, Yu Shi, Zhenghua Huang, Hanyu Hong. Multi-features combinatorial optimization for keyframe extraction[J]. Electronic Research Archive, 2023, 31(10): 5976-5995. doi: 10.3934/era.2023304
Recent advancements in network and multimedia technologies have facilitated the distribution and sharing of digital videos over the Internet. These long videos contain very complex contents. Additionally, it is very challenging to use as few frames as possible to cover the video contents without missing too much information. There are at least two ways to describe these complex videos contents with minimal frames: the keyframes extracted from the video or the video summary. The former lays stress on covering the whole video contents as much as possible. The latter emphasizes covering the video contents of interest. As a consequence, keyframes are widely used in many areas such as video segmentation and object tracking. In this paper, we propose a keyframe extraction method based on multiple features via a novel combinatorial optimization algorithm. The key frame extraction is modeled as a combinatorial optimization problem. A fast dynamic programming algorithm based on a forward non-overlapping transfer matrix in polynomial time and a 0-1 integer linear programming algorithm based on an overlapping matrix is proposed to solve our maximization problem. In order to quantitatively evaluate our approach, a long video dataset named 'Animal world' is self-constructed, and the segmentation evaluation criterions are introduced. A good result is achieved on 'Animal world' dataset and a public available Keyframe-Sydney KFSYD dataset [

| [1] |
G. Guan, Z. Wang, S. Lu, J. Deng, D. Feng, Keypoint-based keyframe selection, IEEE Trans. Circuits Syst. Video Technol., 23 (2013), 729–734. https://doi.org/10.1007/978-1-4684-2001-2-9 doi: 10.1007/978-1-4684-2001-2-9

|
| [2] | Z. Dong, G. Zhang, J. Jia, H. Bao, Keyframe-based real-time camera tracking, in IEEE International Conference on Computer Vision, (2009), 1538–1545. https://doi.org/10.1109/ICCV.2009.5459273 |
| [3] | C. Huang, E. Boyer, N. Navab, S. Ilic, Human shape and pose tracking using keyframes, in IEEE Conference on Computer Vision and Pattern Recognition, (2014), 3446–3453. https://doi.org/10.1109/CVPR.2014.440 |
| [4] | C. Vondrick, D. Ramanan, Video annotation and tracking with active learning, in Conference on Neural Information Processing Systems, (2011), 28–36. |
| [5] |
Z. Li, G. M. Schuster, A. K. Katsaggelos, MINMAX optimal video summarization, IEEE Trans. Circuits Syst. Video Technol., 15 (2005), 1245–1256. https://doi.org/10.1109/TCSVT.2005.854230 doi: 10.1109/TCSVT.2005.854230
|
| [6] |
C. Ngo, Y. Ma, H. Zhang, Video summarization and scene detection by graph modeling, IEEE Trans. Circuits Syst. Video Technol., 15 (2005), 296–305. https://doi.org/10.1109/TCSVT.2004.841694 doi: 10.1109/TCSVT.2004.841694
|
| [7] |
C. Ngo, T. Pong, H. Zhang, Motion-based video representation for scene change detection, Int. J. Comput. Vision, 50 (2002), 127–142. https://doi.org/https://doi.org/10.1023/A:1020341931699 doi: 10.1023/A:1020341931699
|
| [8] | B. Han, J. Hamm, J. Sim, Personalized video summarization with human in the loop, in IEEE Workshop on Applications of Computer Vision, (2011), 51–57. https://doi.org/10.1109/WACV.2011.5711483 |
| [9] | K. Mahmoud, N. Ghanem, M. Ismail, Vgraph: An effective approach for generating static video summaries, in IEEE International Conference on Computer Vision Workshops, (2013), 811–818. https://doi.org/10.1109/ICCVW.2013.111 |
| [10] |
K. R. Raval, M. M. Goyani, A survey on event detection based video summarization for cricket, Multimedia Tools Appl., 81 (2022), 29253–29281. https://doi.org/10.1007/s11042-022-12834-y doi: 10.1007/s11042-022-12834-y
|
| [11] | G. Wang, Y. Lu, L. Zhang, A. Alfarrarjeh, R. Zimmermann, S. H. Kim, et al., Active key frame selection for 3d model reconstruction from crowdsourced geo-tagged videos, in IEEE International Conference on Multimedia and Expo, (2014), 1–6. https://doi.org/10.1109/ICME.2014.6890253 |
| [12] |
L. Liu, L. Shao, P. Rockett, Boosted key-frame selection and correlated pyramidal motion-feature representation for human action recognition, Pattern Recognit., 46 (2013), 1810–1818. https://doi.org/10.1016/j.patcog.2012.10.004 doi: 10.1016/j.patcog.2012.10.004
|
| [13] |
H. Zhang, J. Wu, D. Zhong, S. W. Smoliar, An integrated system for content-based video retrieval and browsing, Pattern Recognit., 30 (1997), 643–658. https://doi.org/10.1016/S0031-3203(96)00109-4 doi: 10.1016/S0031-3203(96)00109-4
|
| [14] |
R. S. Kiziltepe, J. Q. Gan, J. Escobar, A novel keyframe extraction method for video classification using deep neural networks, Neural Comput. Appl., 2021 (2021), 1–12. https://doi.org/10.1007/s00521-021-06322-x doi: 10.1007/s00521-021-06322-x
|
| [15] |
M. Jian, S. Zhang, L. Wu, S. Zhang, X. Wang, Y. He, Deep key frame extraction for sport training, Neurocomputing, 328 (2019), 147–156. https://doi.org/10.1016/j.neucom.2018.03.077 doi: 10.1016/j.neucom.2018.03.077
|
| [16] | S. Jadon, M. Jasim, Unsupervised video summarization framework using keyframe extraction and video skimming, in IEEE International Conference on Computing Communication and Automation (ICCCA), (2020), 140–145. https://doi.org/10.1109/ICCCA49541.2020.9250764 |
| [17] |
J. S. Boreczky, L. A. Rowe, Comparison of video shot boundary detection techniques, J. Electron. Imaging, 5 (1996), 122–128. https://doi.org/10.1117/12.238675 doi: 10.1117/12.238675
|
| [18] |
M. K. Mandal, F. M. Idris, S. Panchanathan, A critical evaluation of image and video indexing techniques in the compressed domain, Image Vision Comput., 17 (1999), 513–529. https://doi.org/10.1016/S0262-8856(98)00143-7 doi: 10.1016/S0262-8856(98)00143-7
|
| [19] |
C. Panagiotakis, A. Doulamis, G. Tziritas, Equivalent key frames selection based on iso-content principles, IEEE Trans. Circuits Syst. Video Technol., 19 (2009), 447–451. https://doi.org/10.1109/TCSVT.2009.2013517 doi: 10.1109/TCSVT.2009.2013517
|
| [20] | W. Chu, Y. Song, A. Jaimes, Video co-summarization: Video summarization by visual co-occurrence, in IEEE Conference on Computer Vision and Pattern Recognition, (2015), 3584–3592. https://doi.org/10.1109/CVPR.2015.7298981 |
| [21] | M. Naphade, R. Mehrotra, A. Ferman, J. Warnick, T. Huang, A. Tekalp, A high-performance shot boundary detection algorithm using multiple cues, in International Conference on Image Processing, 1 (1998), 884–887. https://doi.org/10.1109/ICIP.1998.723662 |
| [22] | V. Karasev, A. Ravichandran, S. Soatto, Active frame, location, and detector selection for automated and manual video annotation, in IEEE Conference on Computer Vision and Pattern Recognition, (2014), 2131–2138. https://doi.org/10.1109/CVPR.2014.273 |
| [23] |
M. Yeung, B. L. Yeo, Video visualization for compact presentation and fast browsing of pictorial content, IEEE Trans. Circuits Syst. Video Technol., 7 (1997), 771–785. https://doi.org/10.1109/76.633496 doi: 10.1109/76.633496
|
| [24] |
M. Omidyeganeh, S. Ghaemmaghami, S. Shirmohammadi, Video keyframe analysis using a segment-based statistical metric in a visually sensitive parametric space, IEEE Trans. Image Process., 20 (2011), 2730–2737. https://doi.org/10.1109/TIP.2011.2143421 doi: 10.1109/TIP.2011.2143421
|
| [25] | Y. Zhuang, Y. Rui, T. Huang, S. Mehrotra, Adaptive key frame extraction using unsupervised clustering, in International Conference on Image Processing, 1 (1998), 866–870. https://doi.org/10.1109/ICIP.1998.723655 |
| [26] |
A. Hanjalic, H. Zhang, An integrated scheme for automated video abstraction based on unsupervised cluster-validity analysis, IEEE Trans. Circuits Syst. Video Technol., 9 (1999), 1280–1289. https://doi.org/10.1109/76.809162 doi: 10.1109/76.809162
|
| [27] | A. Girgensohn, J. Boreczky, Time-constrained keyframe selection technique, in IEEE International Conference on Multimedia Computing and Systems, 1 (1999), 756–761. https://doi.org/10.1109/MMCS.1999.779294 |
| [28] | M. Kumar, A. Loui, Key frame extraction from consumer videos using sparse representation, in IEEE International Conference on Image Processing, (2011), 2437–2440. https://doi.org/10.1109/ICIP.2011.6116136 |
| [29] | T. H. Cormen, C. E. Leiserson, R. L. Rivest, C. Stein, Introduction to Algorithms, MIT Press, 2009. |
| [30] | G. L. Nemhauser, L. A. Wolsey, Integer and Combinatorial Optimization, Wiley, 1988. https://doi.org/10.1007/978-3-030-45771-6 |
| [31] | R. M. Karp, Reducibility among Combinatorial Problems, Springer Berlin Heidelberg, 2010. |
| [32] | H. S. Park, J. Shi, Social saliency prediction, in IEEE Conference on Computer Vision and Pattern Recognition, (2015), 971–987. https://doi.org/10.1109/CVPR.2015.7299110 |
| [33] |
H. S. Chang, S. Sull, S. U. Lee, Efficient video indexing scheme for content-based retrieval, IEEE Trans. Circuits Syst. Video Technol., 9 (1999), 1269–1279. https://doi.org/10.1109/76.809161 doi: 10.1109/76.809161
|
| [34] |
V. T. Paschos, A first course in combinatorial optimization, cambridge texts in applied mathematics, Eur. J. Oper. Res., 168 (2006), 1042–1044. https://doi.org/10.1017/CBO9780511616655 doi: 10.1017/CBO9780511616655
|
| [35] |
H. Lee, S. Kim, Iterative key frame selection in the rate-constraint environment, Signal Process. Image Commun., 18 (2003), 1–15. https://doi.org/10.1016/S0923-5965(02)00089-9 doi: 10.1016/S0923-5965(02)00089-9
|
| [36] | X. Liu, M. Song, L. Zhang, S. Wang, J. Bu, C. Chen, et al., Joint shot boundary detection and key frame extraction, in Proceedings of the 21st International Conference on Pattern Recognition (ICPR2012), (2012), 2565–2568. |
| [37] |
D. G. Lowe, Distinctive image features from scale-invariant keypoints, Int. J. Comput. Vision, 60 (2004), 91–110. https://doi.org/10.1023/B:VISI.0000029664.99615.94 doi: 10.1023/B:VISI.0000029664.99615.94
|
| [38] |
A. T. Aude Oliva, Modeling the shape of the scene: A holistic representation of the spatial envelope, Int. J. Comput. Vision, 42 (2001), 145–175. https://doi.org/10.1023/A:1011139631724 doi: 10.1023/A:1011139631724
|
| [39] | N. Dalal, B. Triggs, Histograms of oriented gradients for human detection, in IEEE Computer Society Conference on Computer Vision and Pattern Recognition, (2005), 886–893. https://doi.org/10.1109/CVPR.2005.177 |
| [40] | J. Bang-Jensen, G. Gutin, Digraphs: Theory, Algorithms and Applications, Springer, 2002. https://doi.org/10.1007/978-1-84800-998-1 |
| [41] | F. F. Li, P. Perona, A bayesian hierarchical model for learning natural scene categories, in IEEE Conference on Computer Vision and Pattern Recognition, (2005), 524–531. https://doi.org/10.1109/CVPR.2005.16 |
| [42] | S. Vijayanarasimhan, K. Grauman, Active frame selection for label propagation in videos, in European Conference on Computer Vision, (2012), 496–509. https://doi.org/10.1007/978-3-642-33715-4-36 |
| [43] | T. Liu, J. R. Kender, Optimization algorithms for the selection of key frame sequences of variable length, in European Conference on Computer Vision, (2002), 403–417. https://doi.org/10.1007/3-540-47979-1-27 |
| [44] |
J. Munkres, Algorithms for the assignment and transportation problems, J. Soc. Ind. Appl. Math., 5 (1957), 32–38. https://doi.org/10.1137/0105003 doi: 10.1137/0105003
|
| [45] | Y. Gong, M. Pawlowski, F. Yang, L. Brandy, L. Boundev, R. Fergus, Web scale photo hash clustering on a single machine, in IEEE Conference on Computer Vision and Pattern Recognition, (2015), 19–27. https://doi.org/10.1109/CVPR.2015.7298596 |







Figures(8) / Tables(1)
Lei Ma, Weiyu Wang, Yaozong Zhang, Yu Shi, Zhenghua Huang, Hanyu Hong. Multi-features combinatorial optimization for keyframe extraction[J]. Electronic Research Archive, 2023, 31(10): 5976-5995. doi: 10.3934/era.2023304







 DownLoad:
DownLoad: