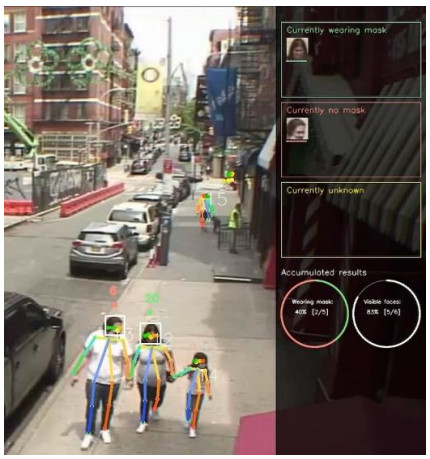
Recent works have illustrated that many facial privacy protection methods are effective in specific face recognition algorithms. However, the COVID-19 pandemic has promoted the rapid innovation of face recognition algorithms for face occlusion, especially for the face wearing a mask. It is tricky to avoid being tracked by artificial intelligence only through ordinary props because many facial feature extractors can determine the ID only through a tiny local feature. Therefore, the ubiquitous high-precision camera makes privacy protection worrying. In this paper, we establish an attack method directed against liveness detection. A mask printed with a textured pattern is proposed, which can resist the face extractor optimized for face occlusion. We focus on studying the attack efficiency in adversarial patches mapping from two-dimensional to three-dimensional space. Specifically, we investigate a projection network for the mask structure. It can convert the patches to fit perfectly on the mask. Even if it is deformed, rotated and the lighting changes, it will reduce the recognition ability of the face extractor. The experimental results show that the proposed method can integrate multiple types of face recognition algorithms without significantly reducing the training performance. If we combine it with the static protection method, people can prevent face data from being collected.
Citation: Guangmin Sun, Hao Wang, Yu Bai, Kun Zheng, Yanjun Zhang, Xiaoyong Li, Jie Liu. PrivacyMask: Real-world privacy protection in face ID systems[J]. Mathematical Biosciences and Engineering, 2023, 20(2): 1820-1840. doi: 10.3934/mbe.2023083
Recent works have illustrated that many facial privacy protection methods are effective in specific face recognition algorithms. However, the COVID-19 pandemic has promoted the rapid innovation of face recognition algorithms for face occlusion, especially for the face wearing a mask. It is tricky to avoid being tracked by artificial intelligence only through ordinary props because many facial feature extractors can determine the ID only through a tiny local feature. Therefore, the ubiquitous high-precision camera makes privacy protection worrying. In this paper, we establish an attack method directed against liveness detection. A mask printed with a textured pattern is proposed, which can resist the face extractor optimized for face occlusion. We focus on studying the attack efficiency in adversarial patches mapping from two-dimensional to three-dimensional space. Specifically, we investigate a projection network for the mask structure. It can convert the patches to fit perfectly on the mask. Even if it is deformed, rotated and the lighting changes, it will reduce the recognition ability of the face extractor. The experimental results show that the proposed method can integrate multiple types of face recognition algorithms without significantly reducing the training performance. If we combine it with the static protection method, people can prevent face data from being collected.

| [1] | M. Sharif, S. Bhagavatula, L. Bauer, M. K. Reiter, Accessorize to a crime: real and stealthy attacks on state-of-the-art face recognition, in Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, (2016), 1528–1540. https://doi.org/10.1145/2976749.2978392 |
| [2] | S. Komkov, A. Petiushko, Advhat: Real-world adversarial attack on ArcFace face id system, preprint, arXiv: 1908/08705 |
| [3] | M. Pautov, G. Melnikov, E. Kaziakhmedov, K. Kireev, A. Petiushko, On adversarial patches: Real-world attack on ArcFace-100 face recognition system, in 2019 International Multi-Conference on Engineering, Computer and Information Sciences, (2019), 391–396. https://doi.org/10.1109/SIBIRCON48586.2019.8958134 |
| [4] | S. Thys, W. Van Ranst, T. Goedemé, Fooling automated surveillance cameras: Adversarial patches to attack person detection, in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, (2019), 49–55. https://doi.org/10.1109/CVPRW.2019.00012 |
| [5] |
N. Ud Din, K. Javed, S. Bae, J. Yi, A novel GAN-based network for unmasking of masked face, IEEE Access, 8 (2020), 44276–44287. https://doi.org/10.1109/ACCESS.2020.2977386 doi: 10.1109/ACCESS.2020.2977386

|
| [6] |
S. Ge, C. Li, S. Zhao, D. Zeng, Occluded face recognition in the wild by identity-diversity inpainting, IEEE Trans. Circ. Syst. Vid., 30 (2020), 3387–3397. https://doi.org/10.1109/TCSVT.2020.2967754 doi: 10.1109/TCSVT.2020.2967754
|
| [7] |
R. Weng, J. Lu, Y. P. Tan, Robust point set matching for partial face recognition, IEEE Trans. Image Process., 25 (2016), 1163–1176. https://doi.org/10.1109/TIP.2016.2515987 doi: 10.1109/TIP.2016.2515987
|
| [8] |
W. Hariri, Efficient masked face recognition method during the COVID-19 pandemic, Signal Image Video Process., 16 (2022), 605–612. https://doi.org/10.1007/s11760-021-02050-w doi: 10.1007/s11760-021-02050-w
|
| [9] | D. Montero, M. Nieto, P. Leskovsky, N. Aginako, Boosting masked face recognition with multi-task ArcFace, preprint, arXiv: 2104/09874 |
| [10] | M. Sharif, S. Bhagavatula, L. Bauer, M. K. Reiter, Accessorize to a crime: Real and stealthy attacks on state-of-the-art face recognition, in Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, (2016), 1528–1540. https://doi.org/10.1145/2976749.2978392 |
| [11] |
Y. Kim, J. Na, S. Yoon, J. Yi, Masked fake face detection using radiance measurements, J. Opt. Soc. Am. A. Opt. Image Sci. Vis., 26 (2009), 760–766, https://doi.org/10.1364/JOSAA.26.000760 doi: 10.1364/JOSAA.26.000760
|
| [12] | N. Kose, J. L. Dugelay, Countermeasure for the protection of face recognition systems against mask attacks, in 2013 10th IEEE International Conference and Workshops on Automatic Face and Gesture Recognition (FG), (2013), 1–6. https://doi.org/10.1109/FG.2013.6553761 |
| [13] | Y. Song, H. Zhang, A framework of face synthesis based on multilinear analysis, in Proceedings of the 15th ACM SIGGRAPH Conference on Virtual-Reality Continuum and Its Applications in Industry, 1 (2016), 111–114. https://doi.org/10.1145/3013971.3014026 |
| [14] | J. Pu, N. Mangaokar, L. Kelly, P. Bhattacharya, K. Sundaram, M. Javed, et al., Deepfake videos in the wild: Analysis and detection, in Proceedings of the Web Conference 2021, (2021), 981–992. https://doi.org/10.1145/3442381.3449978 |
| [15] |
R. Sun, C. Huang, H. Zhu, L. Ma, Mask-aware photorealistic facial attribute manipulation, Comput. Visual Media, 7 (2021), 363–374. https://doi.org/10.1007/s41095-021-0219-7 doi: 10.1007/s41095-021-0219-7
|
| [16] | J. Lei, Z. Liu, Z. Zou, T. Li, J. Xu, Z. Feng, et al., Facial expression recognition by expression-specific representation swapping, in Artificial Neural Networks and Machine Learning—ICANN 2021, Lecture Notes in Computer Science, (2021), 80–91. https://doi.org/10.1007/978-3-030-86340-1_7 |
| [17] |
H. Wang, G. Sun, K. Zheng, H. Li, J. Liu, Y. Bai, Privacy protection generalization with adversarial fusion, Math. Biosci. Eng., 19 (2022), 7314–7336. https://doi.org/10.3934/mbe.2022345 doi: 10.3934/mbe.2022345
|
| [18] |
W. Ou, X. You, D. Tao, P. Zhang, Y. Tang, Z. Zhu, Robust face recognition via occlusion dictionary learning, Pattern Recogn., 47 (2014), 1559–1572. https://doi.org/10.1016/j.patcog.2013.10.017 doi: 10.1016/j.patcog.2013.10.017
|
| [19] |
N. Alyuz, B. Gokberk, L. Akarun, 3-D Face recognition under occlusion using masked projection, IEEE Trans. Inf. Foren. Sec., 8 (2013), 789–802. https://doi.org/10.1109/TIFS.2013.2256130 doi: 10.1109/TIFS.2013.2256130
|
| [20] |
H. Drira, B. Ben Amor, A. Srivastava, M. Daoudi, R. Slama, 3D Face recognition under expressions, occlusions and pose variations, IEEE Trans. Pattern Anal. Mach. Intell., 35 (2013), 2270–2283. https://doi.org/10.1109/TPAMI.2013.48 doi: 10.1109/TPAMI.2013.48
|
| [21] |
H. Li, D. Huang, J. M. Morvan, Y. Wang, L. Chen, Towards 3D face recognition in the real: A registration-free approach using fine-grained matching of 3D keypoint descriptors, Int. J. Comput. Vis., 113 (2015), 128–142. https://doi.org/10.1007/s11263-014-0785-6 doi: 10.1007/s11263-014-0785-6
|
| [22] |
Y. Guo, J. Zhang, J. Cai, B. Jiang, J. Zheng, CNN-based real-time dense face reconstruction with inverse-rendered photo-realistic face images, IEEE Trans. Pattern Anal. Mach. Intell., 41 (2019), 1294–1307. https://doi.org/10.1109/TPAMI.2018.2837742 doi: 10.1109/TPAMI.2018.2837742
|
| [23] | Q. Hong, Z. Wang, Z. He, N. Wang, X. Tian, T. Lu, Masked face recognition with identification association, in 2020 IEEE 32nd International Conference on Tools with Artificial Intelligence (ICTAI), (2020), 731–735. https://doi.org/10.1109/ICTAI50040.2020.00116 |
| [24] | Y. Utomo, G. P. Kusuma, Masked face recognition: Progress, dataset and dataset generation, in 2021 3rd International Conference on Cybernetics and Intelligent System (ICORIS), (2021), 419–422. https://doi.org/10.1109/ICORIS52787.2021.9649622 |
| [25] | J. Prinosil, O. Maly, Detecting faces with face masks, in 2021 44th International Conference on Telecommunications and Signal Processing (TSP), (2021) 259–262. https://doi.org/10.1109/TSP52935.2021.9522677 |
| [26] |
R. Tolosana, R. Vera-Rodriguez, J. Fierrez, A. Morales, J. Ortega-Garcia, Deepfakes and beyond: A survey of face manipulation and fake detection, Inf. Fusion, 64 (2020), 131–148. https://doi.org/10.1016/j.inffus.2020.06.014 doi: 10.1016/j.inffus.2020.06.014
|
| [27] | S. Avidan, M, Butman, Blind vision, in Computer Vision–ECCV 2006, (2006), 1–13, https://doi.org/10.1007/11744078_1 |
| [28] |
G. Sun, H. Wang, Image encryption and decryption technology based on Rubik's cube and dynamic password, J. Beijing Univ. Technol., 47 (2021), 833–841. https://doi.org/10.11936/bjutxb2020120003 doi: 10.11936/bjutxb2020120003
|
| [29] |
J. Zhou, C. Pun, Personal privacy protection via irrelevant faces tracking and pixelation in video live streaming, IEEE Trans. Inf. Foren. Sec., 16 (2021), 1088–1103. https://doi.org/10.1109/TIFS.2020.3029913 doi: 10.1109/TIFS.2020.3029913
|
| [30] |
P. Climent-Pérez, F. Florez-Revuelta, Protection of visual privacy in videos acquired with RGB cameras for active and assisted living applications, Multimed. Tools Appl., 80 (2021), 23649–23664. https://doi.org/10.1007/s11042-020-10249-1 doi: 10.1007/s11042-020-10249-1
|
| [31] |
K. Zheng, J. Shen, G. Sun, H. Li, Y. Li, Shielding facial physiological information in video, Math. Biosci. Eng., 19 (2021), 5153–5168. https://doi.org/10.3934/mbe.2022241 doi: 10.3934/mbe.2022241
|
| [32] |
M. Chen, X. Liao, M. Wu, PulseEdit: Editing physiological signals in facial videos for privacy protection, IEEE Trans. Inf. Foren. Sec., 17 (2022), 457–471. https://doi.org/10.1109/TIFS.2022.3142993 doi: 10.1109/TIFS.2022.3142993
|
| [33] | S. Shan, E. Wenger, J. Zhang, H. Li, H. Zheng, B. Y. Zhao, Fawkes: Protecting personal privacy against unauthorized deep learning models, in 29th USENIX Security Symposium (USENIX Security 20), (2020), 1589–1604 |
| [34] |
J. R. Padilla-López, A. A. Chaaraoui, F. Flórez-Revuelta, Visual privacy protection methods: A survey, Expert Syst. Appl., 42 (2015), 4177–4195. https://doi.org/10.1016/j.eswa.2015.01.041 doi: 10.1016/j.eswa.2015.01.041
|
| [35] | S. N. Patel, J. W. Summet, K. N. Truong, BlindSpot: Creating capture-resistant spaces, in Protecting Privacy in Video Surveillance, 13 (2009), 185–201. https://doi.org/10.1007/978-1-84882-301-3_11 |
| [36] | T. B. Brown, D. Mané, A. Roy, M. Abadi, J. Gilmer, Adversarial patch, preprint, arXiv: 1712/09665 |
| [37] |
C. He, H. Hu, Image captioning with text-based visual attention, Neural Process. Lett., 49 (2019), 177–185. https://doi.org/10.1007/s11063-018-9807-7 doi: 10.1007/s11063-018-9807-7
|
| [38] | K. Cho, B. van Merriënboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, et al., Learning phrase representations using RNN encoder-decoder for statistical machine translation, in Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), (2014), 1724–1734. http://dx.doi.org/10.3115/v1/D14-1179 |
| [39] |
Q. Guo, J. Huang, N. Xiong, MS-Pointer network: Abstractive text summary based on multi-head self-attention, IEEE Access, 7 (2019), 138603–138613. https://doi.org/10.1109/ACCESS.2019.2941964 doi: 10.1109/ACCESS.2019.2941964
|
| [40] | H. Li, A. Kadav, I. Durdanovic, H. Samet, H. P. Graf, Pruning filters for efficient convnets, preprint, arXiv: 1608.08710 |
| [41] |
J. Liu, B. Zhuang, Z. Zhuang, Y. Guo, J. Huang, J. Zhu, et al., Discrimination-aware network pruning for deep model compression, IEEE Trans. Pattern Anal. Mach. Intell., 44 (2022), 4035–4051. https://doi.org/10.1109/TPAMI.2021.3066410 doi: 10.1109/TPAMI.2021.3066410
|
| [42] |
H. Zou, X. Sun, 3D Face recognition based on an attention mechanism and sparse loss function, Electronics, 10 (2021), 2539. https://doi.org/10.3390/electronics10202539 doi: 10.3390/electronics10202539
|
| [43] |
J. J Koenderink, A. J. Doorn, Surface shape and curvature scales, Image Vis. Comput., 10 (1992), 557–564. https://doi.org/10.1016/0262-8856(92)90076-F doi: 10.1016/0262-8856(92)90076-F
|
| [44] |
I. G. Kang, F. C. Park, Cubic spline algorithms for orientation interpolation, Int. J. Numer. Meth. Eng., 46 (1999), 45–64. https://doi.org/10.1002/(SICI)1097-0207(19990910)46:1%3C45::AID-NME662%3E3.0.CO; 2-K doi: 10.1002/(SICI)1097-0207(19990910)46:1<45::AID-NME662>3.0.CO;2-K
|
| [45] | P. J. Phillips, P. J. Flynn, T. Scruggs, K. W. Bowyer, J. Chang, K. Hoffman, et al., Overview of the face recognition grand challenge, in 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR'05), 1 (2005), 947–954. https://doi.org/10.1109/CVPR.2005.268 |
| [46] | M. Jaderberg, K. Simonyan, A. Zisserman, K. Kavukcuoglu, Spatial transformer networks, in Advances in Neural Information Processing Systems, 2 (2015), 2017–2025. Available from: https://papers.nips.cc/paper/2015/file/33ceb07bf4eeb3da587e268d663aba1a-Paper.pdf |
| [47] |
W. Arendt, M. Warma, Dirichlet and neumann boundary conditions: What is in between?, J. Evol. Equations, 3 (2003), 119–135. https://doi.org/10.1007/978-3-0348-7924-8_6 doi: 10.1007/s000280300005
|
| [48] |
R. Carbó-Dorca, Logical kronecker delta deconstruction of the absolute value function and the treatment of absolute deviations, J. Math. Chem., 49 (2011), 619–624. https://doi.org/10.1007/s10910-010-9781-4 doi: 10.1007/s10910-010-9781-4
|
| [49] | M. Jaderberg, K. Simonyan, A. Zisserman, K. Kavukcuoglu, Spatial transformer networks, preprint, arXiv: 1506/02025 |
| [50] | Z. Wang, G. Wang, B. Huang, Z. Xiong, Q. Hong, H. Wu, et al., Masked face recognition dataset and application, preprint, arXiv: 2003/09093 |
| [51] |
X. Li, S. Liu, H. Chen, K. Wang, A potential information capacity index for link prediction of complex networks based on the cannikin, Entropy, 21 (2019), 863. https://doi.org/10.3390/e21090863 doi: 10.3390/e21090863
|
| [52] | A. Athalye, L. Engstrom, A. Ilyas, K. Kwok, Synthesizing robust adversarial examples, preprint, arXiv: 1707/07397 |
















Figures(17) / Tables(1)

Guangmin Sun, Hao Wang, Yu Bai, Kun Zheng, Yanjun Zhang, Xiaoyong Li, Jie Liu. PrivacyMask: Real-world privacy protection in face ID systems[J]. Mathematical Biosciences and Engineering, 2023, 20(2): 1820-1840. doi: 10.3934/mbe.2023083







 DownLoad:
DownLoad: