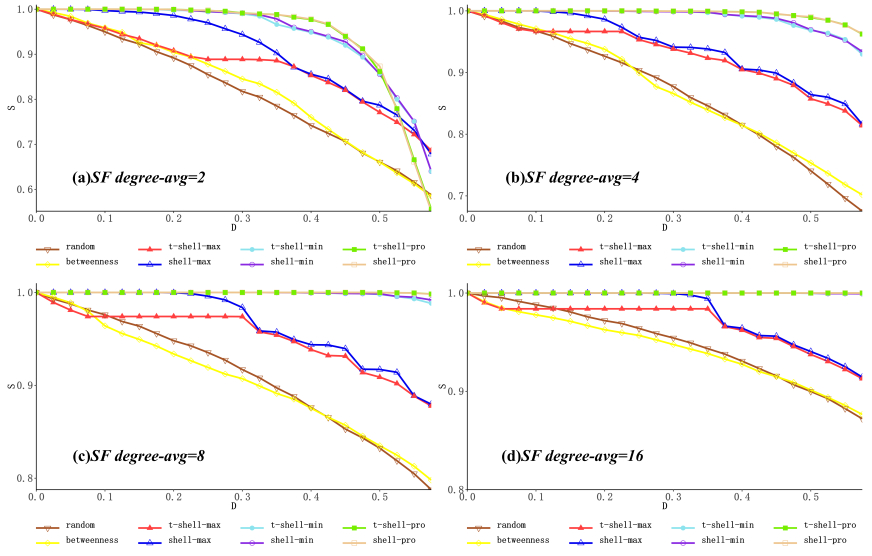
Improving the effectiveness of target link importance assessment strategy has become an important research direction within the field of complex networks today. The reasearch shows that the link importance assessment strategy based on betweenness centrality is the current optimal solution, but its high computational complexity makes it difficult to meet the application requirements of large-scale networks. The $ k $-core decomposition method, as a theoretical tool that can effectively analyze and characterize the topological properties of complex networks and systems, has been introduced to facilitate the generation of link importance assessment strategy and, based on this, a link importance assessment indicator link shell has been developed. The strategy achieves better results in numerical simulations. In this study, we incorporated topological overlap theory to further optimize the attack effect and propose a new link importance assessment indicator link topological shell called $ t $-$ shell $. Simulations using real world networks and scale-free networks show that $ t $-$ shell $ based target link importance assessment strategies perform better than $ shell $ based strategies without increasing the computational complexity; this can provide new ideas for the study of large-scale network destruction strategies.
Citation: Yongheng Zhang, Yuliang Lu, GuoZheng Yang. Link importance assessment strategy based on improved $ k $-core decomposition in complex networks[J]. Mathematical Biosciences and Engineering, 2022, 19(7): 7019-7031. doi: 10.3934/mbe.2022331
Improving the effectiveness of target link importance assessment strategy has become an important research direction within the field of complex networks today. The reasearch shows that the link importance assessment strategy based on betweenness centrality is the current optimal solution, but its high computational complexity makes it difficult to meet the application requirements of large-scale networks. The $ k $-core decomposition method, as a theoretical tool that can effectively analyze and characterize the topological properties of complex networks and systems, has been introduced to facilitate the generation of link importance assessment strategy and, based on this, a link importance assessment indicator link shell has been developed. The strategy achieves better results in numerical simulations. In this study, we incorporated topological overlap theory to further optimize the attack effect and propose a new link importance assessment indicator link topological shell called $ t $-$ shell $. Simulations using real world networks and scale-free networks show that $ t $-$ shell $ based target link importance assessment strategies perform better than $ shell $ based strategies without increasing the computational complexity; this can provide new ideas for the study of large-scale network destruction strategies.

| [1] | A. L. Barabasi, E. Bonabeau, Scale-free network, Sci. Am., 288 (2003), 60–69. http://www.jstor.org/stable/26060284 |
| [2] |
L. A. N. Amaral, A. Scala, M. Barthelemy, H. E. Stanley, Classes of small-world networks, Proc. Natl. Acad. Sci., 97 (2000), 11149–11152. https://doi.org/10.1073/pnas.200327197 doi: 10.1073/pnas.200327197

|
| [3] | J. Jarillo, F. J. Cao-García, F. D. Laender, Spatial and ecological scaling of stability in spatial community networks, preprint, arXiv: 2201.09683. https://doi.org/10.48550/arXiv.2201.09683 |
| [4] | P. Berenbrink, M. Hoefer, D. Kaaser, P. Lenzner, M. Rau, D. Schmand, Asynchronous opinion dynamics in social networks, preprint, arXiv: 2201.12923. https://doi.org/10.48550/arXiv.2201.12923 |
| [5] |
D. Duan, C. Wu, S. Si, Predicting the survivability of invasive species with mutualistic and competing interaction networks, Phys. A: Stat. Mech. Appl., 587 (2022), 126515. https://doi.org/10.1016/j.physa.2021.126515 doi: 10.1016/j.physa.2021.126515
|
| [6] |
Z. Wang, D. Delahaye, J. L. Farges, S. Alam, Air traffic assignment for intensive urban air mobility operations, J. Aerosp. Inf. Syst., 18 (2021), 860–875. https://doi.org/10.2514/1.I010954 doi: 10.2514/1.I010954
|
| [7] |
J. H. Zhao, D. L. Zeng, J. T. Qin, H. M. Si, X. F. Liu. Simulation and modeling of microblog-based spread of public opinions on emergencies, Neural Comput. Appl., 33 (2021), 547–564. https://doi.org/10.1007/s00521-020-04919-2 doi: 10.1007/s00521-020-04919-2
|
| [8] | Y. Shi, X. Qiu, S. Guo, Genetic algorithm-based redundancy optimization method for smart grid communication network, China Commun., 12 (2015), 73–84. |
| [9] |
S. Omranian, A. Angeleska, Z. Nikoloski, Efficient and accurate identification of protein complexes from protein-protein interaction networks based on the clustering coefficient, Comput. Struct. Biotechnol. J., 19 (2021), 5255–5263. https://doi.org/10.1016/j.csbj.2021.09.014 doi: 10.1016/j.csbj.2021.09.014
|
| [10] | R. Duffey, Critical infrastructure: the probability and duration of national and regional power outages, Reliab. Theory Appl., 15 (2020), 62–71. |
| [11] |
S. Borsky, C. Unterberger, Bad weather and flight delays: The impact of sudden and slow onset weather events, Econ. Transp., 18 (2019), 10–26. https://doi.org/10.1016/j.ecotra.2019.02.002 doi: 10.1016/j.ecotra.2019.02.002
|
| [12] |
B. Corominasmurtra, B. Fuchs, S. Thurner, Detection of the elite structure in a virtual multiplex social system by means of a generalised k-core, Environ. Sci. Pollut. Res., 21 (2014), 10294–10306. https://doi.org/10.1371/journal.pone.0112606 doi: 10.1371/journal.pone.0112606
|
| [13] |
D. H. Silva, S. C. Ferreira, Activation thresholds in epidemic spreading with motile infectious agents on scale-free networks, Chaos: Interdiscip. J. Nonlinear Sci., 28 (2018), 123112. https://doi.org/10.1063/1.5050807 doi: 10.1063/1.5050807
|
| [14] | J. Alvarez-Hamelin, L. Dall'Asta, A. Barrat, A. Vespignani, K-core decomposition of internet graphs: hierarchies, self-similarity and measurement biases, preprint, arXiv: cs/0511007v4. https://doi.org/10.48550/arXiv.cs/0511007 |
| [15] |
Y. Shang, Attack robustness and stability of generalized k-cores, New J. Phys., 21 (2019), 093013. https://doi.org/10.1088/1367-2630/ab3d7c doi: 10.1088/1367-2630/ab3d7c
|
| [16] | S. Sun, X. Liu, L. Wang, C. Xia, New link attack strategies of complex networks based on k-core decomposition, IEEE Trans. Circuits Syst. II Express Briefs, 67 (2020), 3157–3161. |
| [17] | A. Montresor, F. D. Pellegrini, D. Miorandi, Distributed k-core decomposition, IEEE Trans. Parallel Distrib. Syst., 24 (2012), 288–300. |
| [18] |
J. P. Onnela, J. Saramaeki, J. Hyvoenen, G. Szabo, D. Lazer, K. Kaski, et al., Structure and tie strengths in mobile communication networks, Proc. Natl. Acad. Sci. U.S.A., 104 (2007), 7332–7336. https://doi.org/10.1073/pnas.0610245104 doi: 10.1073/pnas.0610245104
|
| [19] |
M. Girvan, M. E. Newman, Community structure in social and biological networks, Proc. Natl. Acad. Sci. U.S.A., 99 (2002), 7821–7826. https://doi.org/10.1073/pnas.122653799 doi: 10.1073/pnas.122653799
|
| [20] |
L. C. Freeman, A set of measures of centrality based on betweenness, Sociometry, 40 (1977), 35–41. https://doi.org/10.2307/3033543 doi: 10.2307/3033543
|
| [21] | R. Rossi, N. Ahmed, The network data repository with interactive graph analytics and visualization, in Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, 2015. |
| [22] | J. Kunegis, Konect: The koblenz network collection, in Proceedings of the 22nd international conference on world wide web, (2013), 1343–1350. |
| [23] | J. Leskovec, A. Krevl, SNAP Datasets: Stanford large network dataset collection, 2014. Avaliable from: http://snap.stanford.edu/data. |
| [24] |
J. Bae, S. Kim, Identifying and ranking influential spreaders in complex networks by neighborhood coreness, Phys. A Stat. Mech. Appl., 395 (2014), 549–559. https://doi.org/10.1016/j.physa.2013.10.047 doi: 10.1016/j.physa.2013.10.047
|
| [25] |
W. Jing, Y. Li, X. Zhang, J. Zhang, Z. Jin, A rumor spreading pairwise model on weighted networks, Phys. A Stat. Mech. Appl., 585 (2022), 126451. https://doi.org/10.1016/j.physa.2021.126451 doi: 10.1016/j.physa.2021.126451
|
| [26] | C. W. Wu, Synchronization in dynamical systems coupled via multiple directed networks, IEEE Trans. Circuits Syst. II Express Briefs, 68 (2021), 1660–1664. |
| [27] |
H. M. Tornyeviadzi, E. Owusu-Ansah, H. Mohammed, R. Seidu, A systematic framework for dynamic nodal vulnerability assessment of water distribution networks based on multilayer networks, Reliab. Eng. Syst. Saf., 219 (2022), 108217. https://doi.org/10.1016/j.ress.2021.108217 doi: 10.1016/j.ress.2021.108217
|
| [28] |
C. Xia, Z. Wang, C. Zheng, Q. Guo, Y. Shi, M. Dehmer, et al., A new coupled disease-awareness spreading model with mass media on multiplex networks, Inf. Sci., 471 (2019), 185–200. https://doi.org/10.1016/j.ins.2018.08.050 doi: 10.1016/j.ins.2018.08.050
|
| [29] |
Y. Shang, Generalized k-core percolation in networks with community structure, SIAM J. Appl. Math., 80 (2020), 1272–1289. https://doi.org/10.1137/19M1290607 doi: 10.1137/19M1290607
|
| [30] | S. di Bartolomeo, M. Riedewald, W. Gatterbauer, C. Dunne, Stratisfimal layout: A modular optimization model for laying out layered node-link network visualizations, IEEE Trans. Visual Comput. Graphics, 28 (2022), 324–334. |
Figures(5) / Tables(1)

Yongheng Zhang, Yuliang Lu, GuoZheng Yang. Link importance assessment strategy based on improved $ k $-core decomposition in complex networks[J]. Mathematical Biosciences and Engineering, 2022, 19(7): 7019-7031. doi: 10.3934/mbe.2022331







 DownLoad:
DownLoad: