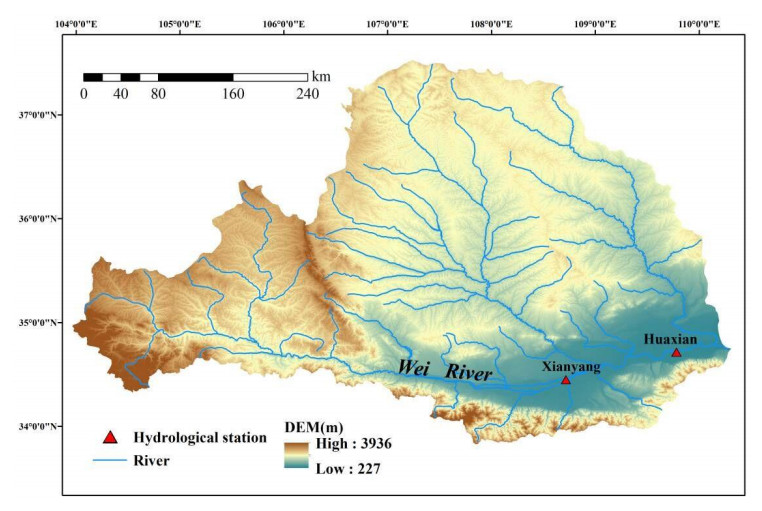
Accurate runoff forecasting plays a vital role in water resource management. Therefore, various forecasting models have been proposed in the literature. Among them, the decomposition-based models have proved their superiority in runoff series forecasting. However, most of the models simulate each decomposition sub-signals separately without considering the potential correlation information. A neoteric hybrid runoff forecasting model based on variational mode decomposition (VMD), convolution neural networks (CNN), and long short-term memory (LSTM) called VMD-CNN-LSTM, is proposed to improve the runoff forecasting performance further. The two-dimensional matrix containing both the time delay and correlation information among sub-signals decomposing by VMD is firstly applied to the CNN. The feature of the input matrix is then extracted by CNN and delivered to LSTM with more potential information. The experiment performed on monthly runoff data investigated from Huaxian and Xianyang hydrological stations at Wei River, China, demonstrates the VMD-superiority of CNN-LSTM to the baseline models, and robustness and stability of the forecasting of the VMD-CNN-LSTM for different leading times.
Citation: Xin Jing, Jungang Luo, Shangyao Zhang, Na Wei. Runoff forecasting model based on variational mode decomposition and artificial neural networks[J]. Mathematical Biosciences and Engineering, 2022, 19(2): 1633-1648. doi: 10.3934/mbe.2022076
Accurate runoff forecasting plays a vital role in water resource management. Therefore, various forecasting models have been proposed in the literature. Among them, the decomposition-based models have proved their superiority in runoff series forecasting. However, most of the models simulate each decomposition sub-signals separately without considering the potential correlation information. A neoteric hybrid runoff forecasting model based on variational mode decomposition (VMD), convolution neural networks (CNN), and long short-term memory (LSTM) called VMD-CNN-LSTM, is proposed to improve the runoff forecasting performance further. The two-dimensional matrix containing both the time delay and correlation information among sub-signals decomposing by VMD is firstly applied to the CNN. The feature of the input matrix is then extracted by CNN and delivered to LSTM with more potential information. The experiment performed on monthly runoff data investigated from Huaxian and Xianyang hydrological stations at Wei River, China, demonstrates the VMD-superiority of CNN-LSTM to the baseline models, and robustness and stability of the forecasting of the VMD-CNN-LSTM for different leading times.

| [1] |
Y. Huang, L. Yang, S. Liu, G. Wang, Multi-step wind speed forecasting based on ensemble empirical mode decomposition, long short term memory network and error correction strategy, Energies, 12 (2019), 18−22. doi: 10.3390/en12101822. doi: 10.3390/en12101822

|
| [2] |
G. K. Devia, B. P. Ganasri, G. S. Dwarakish, A review on hydrological models, Aquat. Proc., 4 (2015), 1001–1007. doi: 10.1016/j.aqpro.2015.02.126. doi: 10.1016/j.aqpro.2015.02.126
|
| [3] |
J. W. Kirchner, Getting the right answers for the right reasons: Linking measurements, analyses, and models to advance the science of hydrology, Water Resour. Res., 42 (2006). doi: 10.1029/2005WR004362. doi: 10.1029/2005WR004362
|
| [4] |
B. Shirmohammadi, M. Vafakhah, V. Moosavi, A. Moghaddamnia, Application of several data-driven techniques for predicting groundwater level, Water Resour. Manag., 27 (2013), 419–432. doi: 10.1007/s11269-012-0194-y. doi: 10.1007/s11269-012-0194-y
|
| [5] |
H. Chu, J. Wei, T. Li, K. Jia, Application of support vector regression for mid-and long-term runoff forecasting in "Yellow river headwater" region, Proc. Eng., 154 (2016), 1251–1257. doi: 10.1016/j.proeng.2016.07.452. doi: 10.1016/j.proeng.2016.07.452
|
| [6] |
C. Hu, Q. Wu, H. Li, S. Jian, N. Li, Z. Lou, Deep learning with a long short-term memory networks approach for rainfall-runoff simulation, Water, 10 (2018), 1543. doi: 10.3390/w10111543. doi: 10.3390/w10111543
|
| [7] |
G. Zuo, J. Luo, N. Wang, Y. Lian, X. He. Two-stage variational mode decomposition and support vector regression for streamflow forecasting, Hydrol. Earth Syst. Sci., 24 (2020), 5491–5518. doi: 10.5194/hess-24-5491-2020. doi: 10.5194/hess-24-5491-2020
|
| [8] |
N. Neeraj, J. Mathew, M. Agarwal, R. K. Behera, Long short-term memory-singular spectrum analysis-based model for electric load forecasting, Electr. Eng., 103 (2021), 1067–1082. doi: 10.1007/s00202-020-01135-y. doi: 10.1007/s00202-020-01135-y
|
| [9] |
X. He, J. Luo, P. Li, G. Zuo, J. Xie, A hybrid model based on variational mode decomposition and gradient boosting regression tree for monthly runoff forecasting, Water Resour. Manag., 34 (2020), 865–884. doi: 10.1007/s11269-020-02483-x. doi: 10.1007/s11269-020-02483-x
|
| [10] |
Q. F. Tan, X. H. Lei, X. Wang, H. Wang, X. Wen, Y. Ji, et al., An adaptive middle and long-term runoff forecast model using EEMD-ANN hybrid approach, J. Hydrol., 567 (2018), 767–80. doi: 10.1016/j.jhydrol.2018.01.015. doi: 10.1016/j.jhydrol.2018.01.015
|
| [11] |
H. Niu, K. Xu, W. Wang, A hybrid stock price index forecasting model based on variational mode decomposition and LSTM network, Appl. Intell., 50 (2020), 4296–4309. doi: 10.1007/s10489-020-01814-0. doi: 10.1007/s10489-020-01814-0
|
| [12] |
H. Liu, X. Mi, Y. Li, Smart multi-step deep learning model for wind speed forecasting based on variational mode decomposition, singular spectrum analysis, LSTM network and ELM, Energy Convers. Manag., 159 (2018), 54–64. doi: 10.1016/j.enconman.2018.01.010. doi: 10.1016/j.enconman.2018.01.010
|
| [13] |
Y. Chen, H. Jiang, C. Li, X. Jia, P. Ghamisi, Deep feature extraction and classification of hyperspectral images based on convolutional neural networks, IEEE Trans. Geosci. Remote Sens., 54 (2016), 6232–6251. doi: 10.1109/TGRS.2016.2584107. doi: 10.1109/TGRS.2016.2584107
|
| [14] |
J. Chang, Y. Wang, E. Istanbulluoglu, T. Bai, Q. Huang, D. Yang, et al., Impact of climate change and human activities on runoff in the Weihe River Basin, China, Quat. Int., 380 (2015), 169–179. doi: 10.1016/j.quaint.2014.03.048. doi: 10.1016/j.quaint.2014.03.048
|
| [15] |
K. Dragomiretskiy, D. Zosso, Variational mode decomposition, IEEE Trans. Signal Process., 62 (2013), 531–544. doi: 10.1109/TSP.2013.2288675. doi: 10.1109/TSP.2013.2288675
|
| [16] |
W. Liu, S. Cao, Y. Chen, Applications of variational mode decomposition in seismic time-frequency analysis, Geophysics, 81 (2016), 365-378. doi: 10.1190/geo2015-0489.1. doi: 10.1190/geo2015-0489.1
|
| [17] |
G. Zhao, G. Liu, L. Fang, B. Tu, P. Ghamisi, Multiple convolutional layers fusion framework for hyperspectral image classification, Neurocomputing, 339 (2019), 149–160. doi: 10.1016/j.neucom.2019.02.019. doi: 10.1016/j.neucom.2019.02.019
|
| [18] |
F. Kratzert, D. Klotz, C. Brenner, K. Schulz, M. Herrnegger, Rainfall-runoff modelling using long short-term memory (LSTM) networks, Hydrol. Earth Syst. Sci., 22 (2018), 6005–6022. doi: 10.5194/hess-22-6005-2018. doi: 10.5194/hess-22-6005-2018
|
| [19] |
Z. Zhao, W. Chen, X. Wu, P. C. Y. Chen, J. Liu, LSTM network: a deep learning approach for short-term traffic forecast, IET Intell. Transp. Syst., 11 (2017), 68–75. doi: 10.1049/iet-its.2016.0208. doi: 10.1049/iet-its.2016.0208
|
| [20] | A. Berryman, P. Turchin, Identifying the density-dependent structure underlying ecological time series, Oikos, 92 (2001), 265−270. doi: 0.1034/j.1600-0706.2001.920208.x. |
| [21] |
S. Hwang, Cross-validation of short-term productivity forecasting methodologies, J. Constr. Eng. Manag., 136 (2010), 1037–46. doi: 10.1061/(ASCE)CO.1943-7862.0000230. doi: 10.1061/(ASCE)CO.1943-7862.0000230
|
| [22] |
M. S. Voss, X. Feng, ARMA model selection using particle swarm optimization and AIC criteria. IFAC Proc. Vol., 35 (2002), 349–354. doi: 10.3182/20020721-6-ES-1901.00469. doi: 10.3182/20020721-6-ES-1901.00469
|
| [23] |
J. Wu, X. Y. Chen, H. Zhang, L. D. Xiong, H. Lei, S. H. Deng, Hyperparameter optimization for machine learning models based on Bayesian optimization. J. Electron. Sci. Technol., 17 (2019), 26–40. doi: 10.11989/JEST.1674-862X.80904120. doi: 10.11989/JEST.1674-862X.80904120
|
| [24] |
S. Yang, J. Liu, Time-series forecasting based on high-order fuzzy cognitive maps and wavelet transform. IEEE Trans. Fuzzy Syst., 26 (2018), 3391–402. doi: 10.1109/tfuzz.2018.2831640. doi: 10.1109/tfuzz.2018.2831640
|








Figures(9) / Tables(4)

Xin Jing, Jungang Luo, Shangyao Zhang, Na Wei. Runoff forecasting model based on variational mode decomposition and artificial neural networks[J]. Mathematical Biosciences and Engineering, 2022, 19(2): 1633-1648. doi: 10.3934/mbe.2022076







 DownLoad:
DownLoad: