Citation: Lal Hussain, Wajid Aziz, Ishtiaq Rasool Khan, Monagi H. Alkinani, Jalal S. Alowibdi. Machine learning based congestive heart failure detection using feature importance ranking of multimodal features[J]. Mathematical Biosciences and Engineering, 2021, 18(1): 69-91. doi: 10.3934/mbe.2021004

| [1] | H. F. Jelinek, D. J. Cornforth, A. H. Khandoker, ECG Time Series Variability Analysis, CRC Press, 2017. |
| [2] | A. J. Seely, P. T. Macklem, Complex systems and the technology of variability analysis, Crit. Care., 8 (2004), R367. |
| [3] | Y. İşler, M. Kuntalp, Combining classical HRV indices with wavelet entropy measures improves to performance in diagnosing congestive heart failure, Comput. Biol. Med., 37 (2007), 1502-1510. |
| [4] | I. Awan, W. Aziz, I. H. Shah, N. Habib, J. S. Alowibdi, S. Saeed, et al., Studying the dynamics of interbeat interval time series of healthy and congestive heart failure subjects using scale based symbolic entropy analysis, PLoS One., 13 (2018), e0196823. |
| [5] |
W. Aziz, M. Rafique, I. Ahmad, M. Arif, N. Habib, M. Nadeem, Classification of heart rate signals of healthy and pathological subjects using threshold based symbolic entropy, Acta Biol. Hung., 65 (2014), 252-264. doi: 10.1556/ABiol.65.2014.3.2

|
| [6] |
A. Hossen, B. Al-Ghunaimi, A wavelet-based soft decision technique for screening of patients with congestive heart failure, Biomed. Signal Process. Control., 2 (2007), 135-143. doi: 10.1016/j.bspc.2007.05.008
|
| [7] | R. A. Thuraisingham, A classification system to detect congestive heart failure uing second-order difference plot of RR intervals, Cardiol. Res. Pract., 2009 (2009), 1-7. |
| [8] |
S. N. Yu, M. Y. Lee, Conditional mutual information-based feature selection for congestive heart failure recognition using heart rate variability, Comput. Methods Programs Biomed., 108 (2012), 299-309. doi: 10.1016/j.cmpb.2011.12.015
|
| [9] |
L. Pecchia, P. Melillo, M. Sansone, M. Bracale, Discrimination power of short-term heart rate variability easures for CHF assessment, IEEE Trans. Inf. Technol. Biomed., 15 (2011), 40-46. doi: 10.1109/TITB.2010.2091647
|
| [10] |
G. Altan, Y. Kutlu, N. Allahverdi, A new approach to early diagnosis of congestive heart failure disease by using Hilbert-Huang transform, Comput. Methods Programs Biomed., 137 (2016), 23-34. doi: 10.1016/j.cmpb.2016.09.003
|
| [11] |
G. I. Choudhary, W. Aziz, I. R. Khan, S. Rahardja, P. Franti, Analysing the dynamics of interbeat interval time series using grouped horizontal visibility graph, IEEE Access, 7 (2019), 9926-9934. doi: 10.1109/ACCESS.2018.2890542
|
| [12] |
Y. Isler, A. Narin, M. Ozer, M. Perc, Multi-stage classification of congestive heart failure based on short-term heart rate variability, Chaos Solitons Fractals, 118 (2019), 145-151. doi: 10.1016/j.chaos.2018.11.020
|
| [13] |
A. Narin, Y. Isler, M. Ozer, M. Perc, Early prediction of paroxysmal atrial fibrillation based on short-term heart rate variability, Phys. A Stat. Mech. Its Appl., 509 (2018), 56-65. doi: 10.1016/j.physa.2018.06.022
|
| [14] | T. Jagrič, M. Marhl, D. Štajer, Š. T. Kocjančič, T. Jagrič, M. Podbregar, et al., Irregularity test for very short electrocardiogram (ECG) signals as a method for predicting a successful defibrillation in patients with ventricular fibrillation, Transl. Res., 149 (2007), 145-151. |
| [15] | L. Wang, W. Xue, Y. Li, M. Luo, J. Huang, W. Cui, et al., Automatic Epileptic Seizure Detection in EEG Signals Using Multi-Domain Feature Extraction and Nonlinear Analysis, Entropy, 19 (2017), 222. |
| [16] |
L. Hussain, W. Aziz, S. Saeed, I. A. Awan, A. A. Abbasi, N. Maroof, Arrhythmia detection by extracting hybrid features based on refined Fuzzy entropy (FuzEn) approach and employing machine learning techniques, Waves Random Complex Media, 30 (2020), 656-686. doi: 10.1080/17455030.2018.1554926
|
| [17] |
S. Rathore, M. Hussain, A. Khan, Automated colon cancer detection using hybrid of novel geometric features and some traditional features, Comput. Biol. Med., 65 (2015), 279-296. doi: 10.1016/j.compbiomed.2015.03.004
|
| [18] | H. Peng, F. Long, C. Ding, Feature selection based on mutual information criteria of maxdependency, max-relevance, and min-redundancy, IEEE Trans. Pattern Anal. Mach. Intell., 27 (2005), 1226-1238. |
| [19] | H. Karnan, N. Sivakumaran, R. Manivel, An efficient cardiac arrhythmia onset detection technique using a novel feature rank score algorithm, J. Med. Syst., 43 (2019), 167. |
| [20] | M. G. Leguia, Z. Levnajić, L. Todorovski, B. Ženko, Reconstructing dynamical networks via feature ranking, Chaos Interd. J. Nonlinear Sci., 29 (2019), 093107. |
| [21] |
Z. Zhou, S. Li, G. Qin, M. Folkert, S. Jiang, J. Wang, Multi-objective-based radiomic feature selection for lesion malignancy classification, IEEE J. Biomed. Heal. Inform., 24 (2020), 194-204. doi: 10.1109/JBHI.2019.2902298
|
| [22] | M. Mourad, S. Moubayed, A. Dezube, Y. Mourad, K. Park, A. Torreblanca-Zanca, et al., Machine learning and feature selection applied to SEER data to reliably assess thyroid cancer prognosis, Sci. Rep., 10 (2020), 5176. |
| [23] |
A. P. Bradley, The use of the area under the ROC curve in the evaluation of machine learning algorithms, Patt. Recogn., 30 (1997), 1145-1159. doi: 10.1016/S0031-3203(96)00142-2
|
| [24] | A. L. Goldberger, L. A. N. Amaral, L. Glass, J. M. Hausdorff, P. C. Ivanov, R. G. Mark, et al., PhysioBank, PhysioToolkit, and PhysioNet, Circulation, 101 (2000). |
| [25] | J. T. Bigger, J. L. Fleiss, R. C. Steinman, L. M. Rolnitzky, W. J. Schneider, P. K. Stein, RR variability in healthy, middle-aged persons compared with patients with chronic coronary heart disease or recent acute myocardial infarction, Circulation, 91 (1995), 1936-1943. |
| [26] |
J. E. Mietus, The pNNx files: Re-examining a widely used heart rate variability measure, Heart, 88 (2002), 378-380. doi: 10.1136/heart.88.4.378
|
| [27] |
K. L. Dodds, C. B. Miller, S. D. Kyle, N. S. Marshall, C. J. Gordon, Heart rate variability in insomnia patients: A critical review of the literature, Sleep Med. Rev., 33 (2017), 88-100. doi: 10.1016/j.smrv.2016.06.004
|
| [28] |
M. R. Esco, H. N. Williford, A. A. Flatt, T. J. Freeborn, F. Y. Nakamura, Ultra-shortened timedomain HRV parameters at rest and following exercise in athletes: An alternative to frequency computation of sympathovagal balance, Eur. J. Appl. Physiol., 118 (2018), 175-184. doi: 10.1007/s00421-017-3759-x
|
| [29] | S. A. Geronikolou, K. Albanopoulos, G. Chrousos, D. Cokkinos, Evaluating the homeostasis assessment model insulin resistance and the cardiac autonomic system in bariatric surgery patients: A meta-analysis, in: P. Vlamos (Ed.), Springer International Publishing, Cham, 2017,249-259. |
| [30] | C. A. Sima, J. A. Inskip, A. W. Sheel, S. F. van Eeden, W. D. Reid, P. G. Camp, The reliability of short-term measurement of heart rate variability during spontaneous breathing in people with chronic obstructive pulmonary disease, Rev. Port. Pneumol. (English Ed.), 23 (2017), 338-342. |
| [31] |
L. Hussain, Detecting epileptic seizure with different feature extracting strategies using robust machine learning classification techniques by applying advance parameter optimization approach, Cogn. Neurodyn., 12 (2018), 271-294. doi: 10.1007/s11571-018-9477-1
|
| [32] | L. Hussain, I. A. Awan, W. Aziz, S. Saeed, A. Ali, F. Zeeshan, et al., Detecting congestive heart failure by extracting multimodal features and employing machine learning techniques, Biomed. Res. Int., 2020 (2020), 1-19. |
| [33] | L. Hussain, W. Aziz, J. S. Alowibdi, N. Habib, M. Rafique, S. Saeed, et al., Symbolic time series analysis of electroencephalographic (EEG) epileptic seizure and brain dynamics with eye-open and eye-closed subjects during resting states, J. Physiol. Anthropol., 36 (2017). |
| [34] |
L. Hussain, W. Aziz, A. A. Alshdadi, M. S. A. Nadeem, I. R. Khan, Q. U. A. Chaudhry, Analyzing the dynamics of lung cancer imaging data using refined fuzzy entropy methods by extracting different features, IEEE Access, 7 (2019), 64704-64721. doi: 10.1109/ACCESS.2019.2917303
|
| [35] | L. Hussain, W. Aziz, S. Saeed, S. A. Shah, M. S. A. Nadeem, A. Awan, et al., Complexity analysis of EEG motor movement with eye open and close subjects using multiscale permutation entropy (MPE) technique, Biomed. Res., 28 (2017), 104-7111. |
| [36] | L. Hussain, W. Aziz, S. Saeed, S. A. Shah, M. S. A. Nadeem, I. A. Awan, et al., Quantifying the dynamics of electroencephalographic (EEG) signals to distinguish alcoholic and non-alcoholic subjects using an MSE based K-d tree algorithm, Biomed. Eng. Biomed. Tech., 63 (2018), 481-490. |
| [37] | L. Hussain, S. Saeed, A. Idris, I. A. Awan, S. A. Shah, A. Majid, et al., Regression analysis for detecting epileptic seizure with different feature extracting strategies, Biomed. Eng. Biomed. Tech., 64 (2019), 619-642. |
| [38] |
M. Pincus, Approximate entropy as a measure of system complexity, Proc. Natl. Acad. Sci., 88 (1991), 2297-2301. doi: 10.1073/pnas.88.6.2297
|
| [39] | J. S. Richman, J. R. Moorman, Physiological time-series analysis using approximate entropy and sample entropy, Am. J. Physiol. Circ. Physiol., 278 (2000), H2039-H2049. |
| [40] | D. Wang, D. Miao, C. Xie, Best basis-based wavelet packet entropy feature extraction and hierarchical EEG classification for epileptic detection, Expert Syst. Appl., 38 (2011), 14314-14320. |
| [41] | O. A. Rosso, S. Blanco, J. Yordanova, V. Kolev, A. Figliola, M. Schürmann, et al., Wavelet entropy: A new tool for analysis of short duration brain electrical signals, J. Neurosci. Methods, 105 (2001), 65-75. |
| [42] |
Y. Wu, Y. Zhou, G. Saveriades, S. Agaian, J.P. Noonan, P. Natarajan, Local Shannon entropy measure with statistical tests for image randomness, Inf. Sci. (Ny)., 222 (2013), 323-342. doi: 10.1016/j.ins.2012.07.049
|
| [43] |
S. Ekici, S. Yildirim, M. Poyraz, Energy and entropy-based feature extraction for locating fault on transmission lines by using neural network and wavelet packet decomposition, Expert Syst. Appl., 34 (2008), 2937-2944. doi: 10.1016/j.eswa.2007.05.011
|
| [44] |
E. Avci, D. Hanbay, A. Varol, An expert discrete wavelet adaptive network based fuzzy inference system for digital modulation recognition, Expert Syst. Appl., 33 (2007), 582-589. doi: 10.1016/j.eswa.2006.06.001
|
| [45] |
I. Turkoglu, A. Arslan, E. Ilkay, An intelligent system for diagnosis of the heart valve diseases with wavelet packet neural networks, Comput. Biol. Med., 33 (2003), 319-331. doi: 10.1016/S0010-4825(03)00002-7
|
| [46] | H. Wang, T. M. Khoshgoftaar, K. Gao, A comparative study of filter-based feature ranking techniques, in: 2010 IEEE Int. Conf. Inf. Reuse Integr., IEEE, 2010, 43-48. |
| [47] | H. Shakir, Y. Deng, H. Rasheed, T. M. R. Khan, Radiomics based likelihood functions for cancer diagnosis, Sci. Rep., 9 (2019), 9501. |
| [48] | W. Wu, C. Parmar, P. Grossmann, J. Quackenbush, P. Lambin, J. Bussink, et al, Exploratory study to identify radiomics classifiers for lung cancer histology, Front. Oncol., 6 (2016), 187-194. |
| [49] |
Y. Saeys, I. Inza, P. Larranaga, A review of feature selection techniques in bioinformatics, Bioinformatics, 23 (2007), 2507-2517. doi: 10.1093/bioinformatics/btm344
|
| [50] | L. Zhu, L. Miao, D. Zhang, Iterative laplacian score for feature selection, in: Proc. 18th Int. Conf. Neural Inf. Process. Syst., 2012, 80-87. |
| [51] |
A. K. Farahat, A. Ghodsi, M. S. Kamel, Efficient greedy feature selection for unsupervised learning, Knowl. Inf. Syst., 35 (2013), 285-310. doi: 10.1007/s10115-012-0538-1
|
| [52] |
P. Mitra, C. A. Murthy, S. K. Pal, Unsupervised feature selection using feature similarity, IEEE Trans. Pattern Anal. Mach. Intell., 24 (2002), 301-312. doi: 10.1109/34.990133
|
| [53] | D. Cai, C. Zhang, X. He, Unsupervised feature selection for multi-cluster data, in: Proc. 16th ACM SIGKDD Int. Conf. Knowl. Discov. Data Min. - KDD '10, ACM Press, New York, New York, USA, New York, USA, 2010,333. |
| [54] |
H. Zeng, Y. Cheung, Feature selection and Kernel learning for local learning-based clustering, IEEE Trans. Pattern Anal. Mach. Intell., 33 (2011), 1532-1547. doi: 10.1109/TPAMI.2010.215
|
| [55] | Z. Zhao, H. Liu, Spectral feature selection for supervised and unsupervised learning, in: Proc. 24th Int. Conf. Mach. Learn. - ICML '07, ACM Press, New York, New York, USA, 2007, 1151-1157. |
| [56] | W. Yang, K. Wang, W. Zuo, Neighborhood component feature selection for high-dimensional data, J. Comput., 7 (2012), 161-168. |
| [57] | I. Kononenko, E. Šimec, M. Robnik-Šikonja, Overcoming the myopia of inductive learning algorithms with RELIEFF, Appl. Intell., 7 (1997), 39-55. |
| [58] | G. Rofo, S. Melzi, Ranking to learn: Feature ranking and selection via eigenvector centrality, in: A. Appice, M. Ceci, C. Loglisci, E. Masciari and Z. Ras, (eds.) New Frontiers in Mining Complex Patterns: 5th International Workshop, NFMCP 2016. |
| [59] | P. Bradley, O. Mangasarian, Feature selection via concave minimization and support vector machines, in: Proc. Int. Conf. Mach. Learn., 1998, : pp. 82-90. |
| [60] | S. Yu, Z. Zhang, X. Liang, J. Wu, E. Zhang, W. Qin, et al., A Matlab toolbox for feature importance ranking, in: 2019 Int. Conf. Med. Imaging Phys. Eng., IEEE, 2019, : pp. 1-6. |
| [61] |
V. N. Vapnik, An overview of statistical learning theory, IEEE Trans. Neural Networks, 10 (1999), 988-999. doi: 10.1109/72.788640
|
| [62] | P. Toccaceli, A. Gammerman, Combination of conformal predictors for classification, Proc. Sixth Work. Conform. Probabilistic Predict. Appl., 60 (2017), 39-61. |
| [63] |
A. Subasi, Classification of EMG signals using PSO optimized SVM for diagnosis of neuromuscular disorders, Comput. Biol. Med., 43 (2013), 576-586. doi: 10.1016/j.compbiomed.2013.01.020
|
| [64] | W. Liu, S. Chawla, D. A. Cieslak, N. V. Chawla, A robust decision tree algorithm for imbalanced data sets, in: Proc. 2010 SIAM Int. Conf. Data Min., Society for Industrial and Applied Mathematics, Philadelphia, PA, 2010,766-777. |
| [65] |
M. J. Aitkenhead, A co-evolving decision tree classification method, Expert Syst. Appl., 34 (2008), 18-25. doi: 10.1016/j.eswa.2006.08.008
|
| [66] |
R.Wang, S. Kwong, X.Wang, Q. Jiang, Segment based decision tree induction with continuous valued attributes, IEEE Trans. Cybern., 45 (2015), 1262-1275. doi: 10.1109/TCYB.2014.2348012
|
| [67] |
J. J. Rissanen, Fisher information and stochastic complexity, IEEE Trans. Inf. Theory., 42 (1996), 40-47. doi: 10.1109/18.481776
|
| [68] |
A. Zaidi, B. Ould Bouamama, M. Tagina, Bayesian reliability models of Weibull systems: State of the art, Int. J. Appl. Math. Comput. Sci., 22 (2012), 585-600. doi: 10.2478/v10006-012-0045-2
|
| [69] | P. Zhang, B.J. Gao, X. Zhu, L. Guo, Enabling fast lazy learning for data streams, in: 2011 IEEE 11th Int. Conf. Data Min., IEEE, 2011,932-941. |
| [70] |
F. Schwenker, E. Trentin, Pattern classification and clustering: A review of partially supervised learning approaches, Pattern Recognit. Lett., 37 (2014), 4-14. doi: 10.1016/j.patrec.2013.10.017
|
| [71] | K. Hajian-Tilaki, Receiver operating characteristic (ROC) curve analysis for medical diagnostic test evaluation, Casp. J. Intern. Med., 4 (2013), 627-635. |
| [72] | Y. Li, Y. Zhang, L. Zhao, Y. Zhang, C. Liu, L. Zhang, et al., Combining convolutional neural network and distance distribution matrix for identification of congestive heart failure, IEEE Access, 6 (2018), 39734-39744. |
| [73] |
A. Narin, Y. Isler, M. Ozer, Investigating the performance improvement of HRV Indices in CHF using feature selection methods based on backward elimination and statistical significance, Comput. Biol. Med., 45 (2014), 72-79. doi: 10.1016/j.compbiomed.2013.11.016
|
| [74] |
Işler, M. Kuntalp, Heart rate normalization in the analysis of heart rate variability in congestive heart failure, Proc. Inst. Mech. Eng. Part H J. Eng. Med., 224 (2010), 453-463. doi: 10.1243/09544119JEIM642
|
| [75] | N. Elfadil, I. Ibrahim, Self organizing neural network approach for identification of patients with Congestive Heart Failure, in: 2011 Int. Conf. Multimed. Comput. Syst., IEEE, 2011, 1-6. |
| [76] | G. Yang, Y. Ren, Q. Pan, G. Ning, S. Gong, G. Cai, et al., A heart failure diagnosis model based on support vector machine, in: 2010 3rd Int. Conf. Biomed. Eng. Informatics, IEEE, 2010, 1105-1108. |
| [77] |
C. S. Son, Y. N. Kim, H. S. Kim, H. S. Park, M. S. Kim, Decision-making model for early diagnosis of congestive heart failure using rough set and decision tree approaches, J. Biomed. Inform., 45 (2012), 999-1008 doi: 10.1016/j.jbi.2012.04.013
|
| [78] | L. Hussain, W. Aziz, S. Saeed, A. Idris, I.A. Awan, S.A. Shah, et al., Spatial wavelet-based coherence and coupling in EEG signals with eye open and closed during resting state, IEEE Access, 6 (2018), 37003-37022. |
| [79] | L. Hussain, S. Rathore, A. A. Abbasi, S. Saeed, Automated lung cancer detection based on multimodal features extracting strategy using machine learning techniques, in: H. Bosmans, G. H. Chen, T. Gilat Schmidt (Eds.), Med. Imaging 2019 Phys. Med. Imaging, SPIE, 2019,134. |
| [80] |
V. Singh, G. Kumari, B. Chhajer, A. K. Jhingan, S. Dahiya, Effectiveness of enhanced external counter pulsation on clinical profile and health-related quality of life in patients with coronary heart disease: A systematic review, Acta Angiol., 24 (2018), 105-122. doi: 10.5603/AA.2018.0021
|
| [81] |
Y. Isler, A. Narin, M. Ozer, Comparison of the effects of cross-validation methods on determining performances of classifiers used in diagnosing congestive heart failure, Meas. Sci. Rev., 15 (2015), 196-201. doi: 10.1515/msr-2015-0027
|
| [82] | R. Han, X. Liu, M. Zheng, R. Zhao, X. Liu, X. Yin, et al., Effect of remote ischemic preconditioning on left atrial remodeling and prothrombotic response after radiofrequency catheter ablation for atrial fibrillation, Pacing Clin. Electrophysiol., 41 (2018), 246-254 |
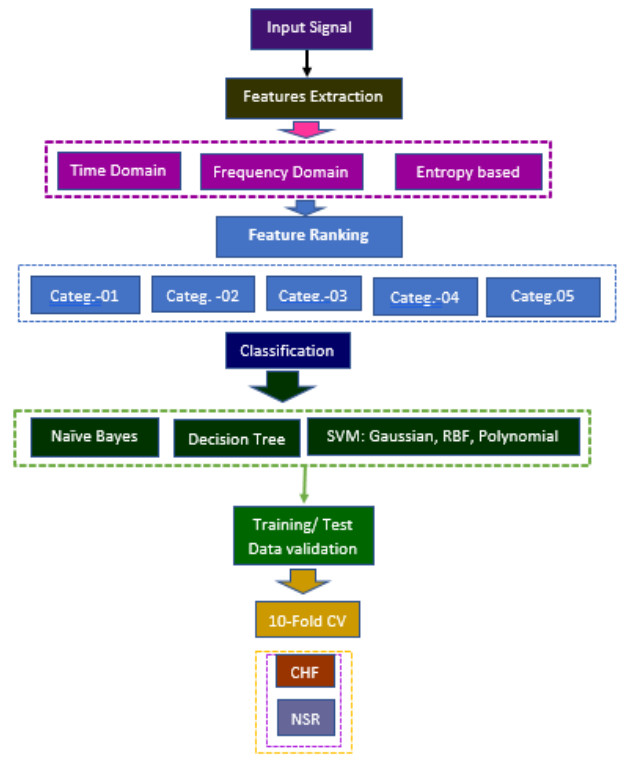
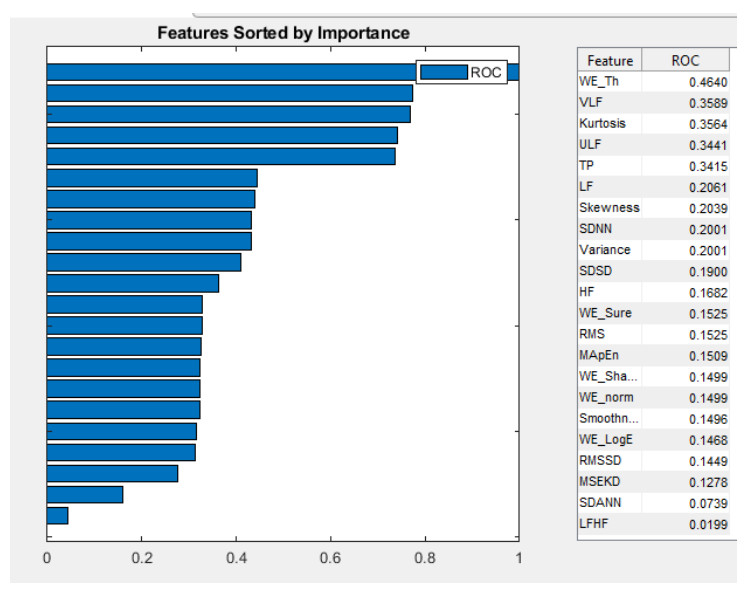
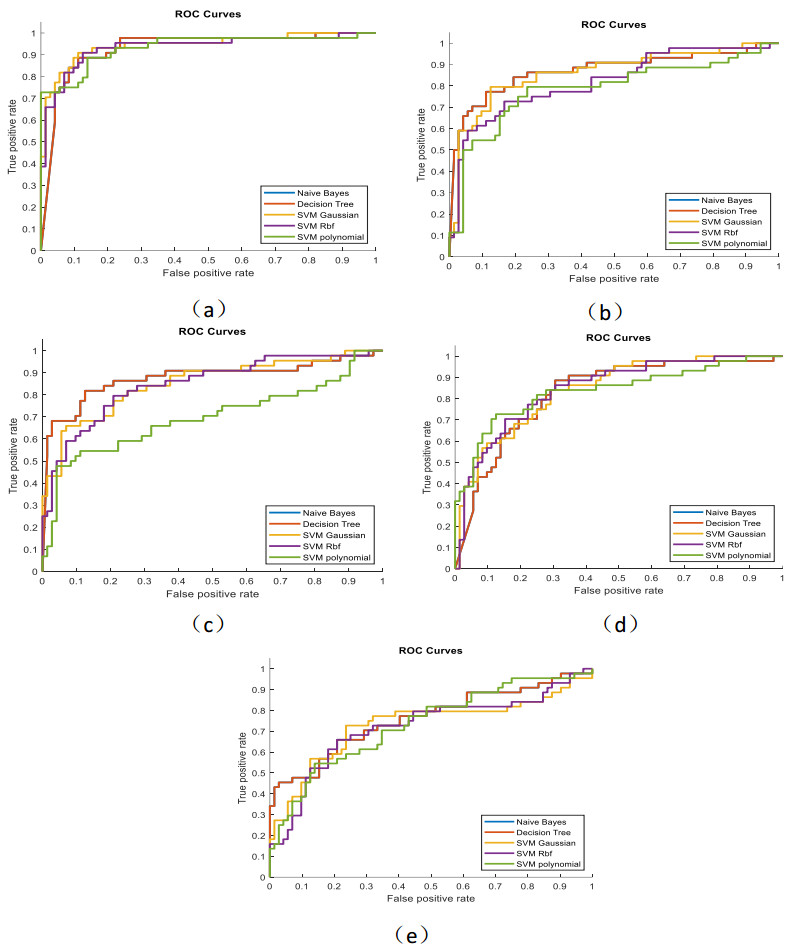
Figures(3) / Tables(2)

Lal Hussain, Wajid Aziz, Ishtiaq Rasool Khan, Monagi H. Alkinani, Jalal S. Alowibdi. Machine learning based congestive heart failure detection using feature importance ranking of multimodal features[J]. Mathematical Biosciences and Engineering, 2021, 18(1): 69-91. doi: 10.3934/mbe.2021004







 DownLoad:
DownLoad: