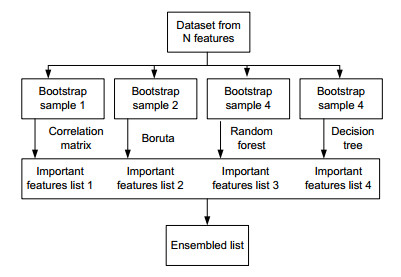
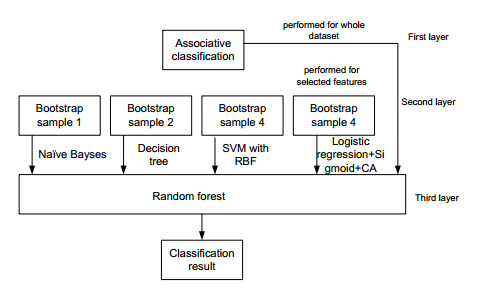
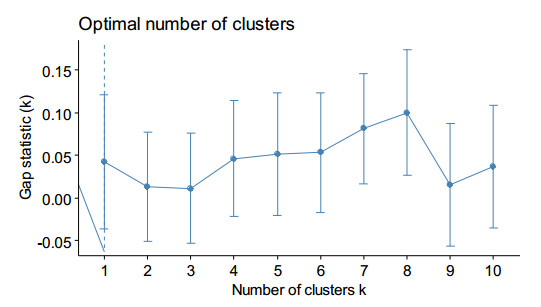
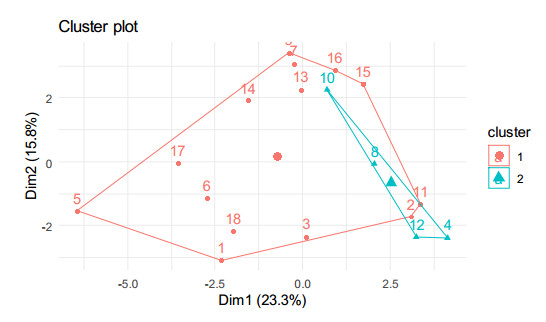
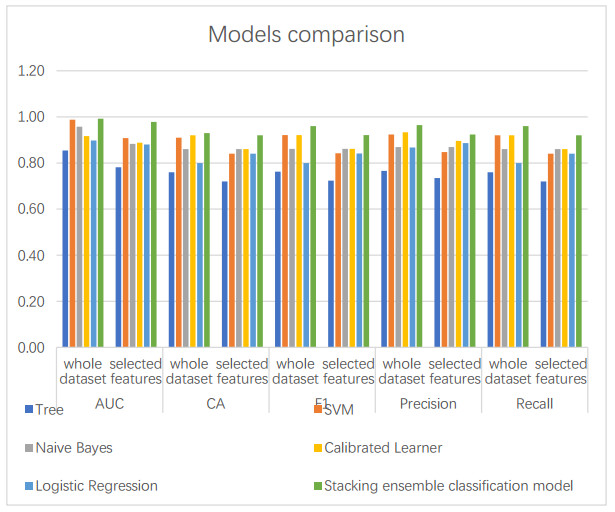
Starting from December 2019, the COVID-19 pandemic has globally strained medical resources and caused significant mortality. It is commonly recognized that the severity of SARS-CoV-2 disease depends on both the comorbidity and the state of the patient's immune system, which is reflected in several biomarkers. The development of early diagnosis and disease severity prediction methods can reduce the burden on the health care system and increase the effectiveness of treatment and rehabilitation of patients with severe cases. This study aims to develop and validate an ensemble machine-learning model based on clinical and immunological features for severity risk assessment and post-COVID rehabilitation duration for SARS-CoV-2 patients. The dataset consisting of 35 features and 122 instances was collected from Lviv regional rehabilitation center. The dataset contains age, gender, weight, height, BMI, CAT, 6-minute walking test, pulse, external respiration function, oxygen saturation, and 15 immunological markers used to predict the relationship between disease duration and biomarkers using the machine learning approach. The predictions are assessed through an area under the receiver-operating curve, classification accuracy, precision, recall, and F1 score performance metrics. A new hybrid ensemble feature selection model for a post-COVID prediction system is proposed as an automatic feature cut-off rank identifier. A three-layer high accuracy stacking ensemble classification model for intelligent analysis of short medical datasets is presented. Together with weak predictors, the associative rules allowed improving the classification quality. The proposed ensemble allows using a random forest model as an aggregator for weak repressors' results generalization. The performance of the three-layer stacking ensemble classification model (AUC 0.978; CA 0.920; F1 score 0.921; precision 0.924; recall 0.920) was higher than five machine learning models, viz. tree algorithm with forward pruning; Naïve Bayes classifier; support vector machine with RBF kernel; logistic regression, and a calibrated learner with sigmoid function and decision threshold optimization. Aging-related biomarkers, viz. CD3+, CD4+, CD8+, CD22+ were examined to predict post-COVID rehabilitation duration. The best accuracy was reached in the case of the support vector machine with the linear kernel (MAPE = 0.0787) and random forest classifier (RMSE = 1.822). The proposed three-layer stacking ensemble classification model predicted SARS-CoV-2 disease severity based on the cytokines and physiological biomarkers. The results point out that changes in studied biomarkers associated with the severity of the disease can be used to monitor the severity and forecast the rehabilitation duration.
Citation: Natalya Shakhovska, Vitaliy Yakovyna, Valentyna Chopyak. A new hybrid ensemble machine-learning model for severity risk assessment and post-COVID prediction system[J]. Mathematical Biosciences and Engineering, 2022, 19(6): 6102-6123. doi: 10.3934/mbe.2022285
Starting from December 2019, the COVID-19 pandemic has globally strained medical resources and caused significant mortality. It is commonly recognized that the severity of SARS-CoV-2 disease depends on both the comorbidity and the state of the patient's immune system, which is reflected in several biomarkers. The development of early diagnosis and disease severity prediction methods can reduce the burden on the health care system and increase the effectiveness of treatment and rehabilitation of patients with severe cases. This study aims to develop and validate an ensemble machine-learning model based on clinical and immunological features for severity risk assessment and post-COVID rehabilitation duration for SARS-CoV-2 patients. The dataset consisting of 35 features and 122 instances was collected from Lviv regional rehabilitation center. The dataset contains age, gender, weight, height, BMI, CAT, 6-minute walking test, pulse, external respiration function, oxygen saturation, and 15 immunological markers used to predict the relationship between disease duration and biomarkers using the machine learning approach. The predictions are assessed through an area under the receiver-operating curve, classification accuracy, precision, recall, and F1 score performance metrics. A new hybrid ensemble feature selection model for a post-COVID prediction system is proposed as an automatic feature cut-off rank identifier. A three-layer high accuracy stacking ensemble classification model for intelligent analysis of short medical datasets is presented. Together with weak predictors, the associative rules allowed improving the classification quality. The proposed ensemble allows using a random forest model as an aggregator for weak repressors' results generalization. The performance of the three-layer stacking ensemble classification model (AUC 0.978; CA 0.920; F1 score 0.921; precision 0.924; recall 0.920) was higher than five machine learning models, viz. tree algorithm with forward pruning; Naïve Bayes classifier; support vector machine with RBF kernel; logistic regression, and a calibrated learner with sigmoid function and decision threshold optimization. Aging-related biomarkers, viz. CD3+, CD4+, CD8+, CD22+ were examined to predict post-COVID rehabilitation duration. The best accuracy was reached in the case of the support vector machine with the linear kernel (MAPE = 0.0787) and random forest classifier (RMSE = 1.822). The proposed three-layer stacking ensemble classification model predicted SARS-CoV-2 disease severity based on the cytokines and physiological biomarkers. The results point out that changes in studied biomarkers associated with the severity of the disease can be used to monitor the severity and forecast the rehabilitation duration.

| [1] | A. M. Kalasic, O. K. Vidovic, Aging and health: priorities of the World Health Organization for the decade of healthy aging 2020-2030, Ageing Human Rights, (2018), 67. |
| [2] |
M. T. Tull, K. A. Edmonds, K. M. Scamaldo, J. R. Richmond, J. P. Rose, K. L. Gratz, Psychological outcomes associated with stay-at-home orders and the perceived impact of COVID-19 on daily life, Psychiatry Res., 289 (2020), 113098. https://doi.org/10.1016/j.psychres.2020.113098 doi: 10.1016/j.psychres.2020.113098

|
| [3] |
W. Gardner, D. States, N. Bagley, The coronavirus and the risks to the elderly in long-term care. J. Aging Soc. Policy, 32 (2020), 310-315. https://doi.org/10.1080/08959420.2020.1750543 doi: 10.1080/08959420.2020.1750543
|
| [4] | Covid2019 coronavirus disease, Retrieved on: 26 December 2021, Available from: https://www.worldometers.info/coronavirus/. |
| [5] |
G. Wu, P. Yang, Y. Xie, H. C. Woodruff, X. Rao, J. Guiot, et al., Development of a clinical decision support system for severity risk prediction and triage of COVID-19 patients at hospital admission: an international multicentre study, Eur. Respir. J., 56 (2020), 2001104. https://doi.org/10.1183/13993003.01104-2020 doi: 10.1183/13993003.01104-2020
|
| [6] |
M. Mittelbrunn, G. Kroemer, Hallmarks of T cell aging, Nat. Immunol., 22 (2021), 687-698. https://doi.org/10.1038/s41590-021-00927-z doi: 10.1038/s41590-021-00927-z
|
| [7] |
M. Jiang, Y. Guo, Q. Luo, Z. Huang, R. Zhao, S. Liu, et al., T-Cell subset counts in peripheral blood can be used as discriminatory biomarkers for diagnosis and severity prediction of coronavirus disease 2019, J. Infect. Dis., 222 (2020), 198-202. https://doi.org/10.1093/infdis/jiaa252 doi: 10.1093/infdis/jiaa252
|
| [8] |
H. Zhang, X. Wang, Z. Fu, M. Luo, Z. Zhang, K. Zhang, et al., Potential factors for prediction of disease severity of COVID-19 patients, medRxiv, 2020. https://doi.org/10.1101/2020.03.20.20039818 doi: 10.1101/2020.03.20.20039818
|
| [9] |
C. Zhang, L. Qin, K. Li, Q. Wang, Y. Zhao, B. Xu, et al., A novel scoring system for prediction of disease severity in COVID-19, Front. Cell. Infect. Microbiol., 10 (2020), 318. https://doi.org/10.3389/fcimb.2020.00318 doi: 10.3389/fcimb.2020.00318
|
| [10] |
B. K. Patterson, J. Guevara-Coto, R. Yogendra, E. B. Francisco, E. Long, A. Pise, et al., Immune-based prediction of COVID-19 severity and chronicity decoded using machine learning, Front. Immunol., 12 (2021), 700782. https://doi.org/10.3389/fimmu.2021.700782 doi: 10.3389/fimmu.2021.700782
|
| [11] | S. Yasar, C. Colak, S. Yologlu, Artificial intelligence-based prediction of Covid-19 severity on the results of protein profiling, Comput. Methods Program Biomed., 202 (2021), 105996. https://doi.org/10.1016/j.cmpb.2021.105996 |
| [12] |
T. D. Bennett, R. A. Moffitt, J. G. Hajagos, B. Amor, A. Anand, M. M. Bissell, et al., Clinical characterization and prediction of clinical severity of SARS-CoV-2 infection among US adults using data from the US national COVID cohort collaborative, JAMA Netw. Open, 4 (2021), e2116901. https://doi.org/10.1001/jamanetworkopen.2021.16901 doi: 10.1001/jamanetworkopen.2021.16901
|
| [13] |
M. Balbi, A. Caroli, A. Corsi, G. Milanese, A. Surace, F. Di Marco, et al., Chest X-ray for predicting mortality and the need for ventilatory support in COVID-19 patients presenting to the emergency department, Eur. Radiol., 31 (2021), 1999-2012. https://doi.org/10.1007/s00330-020-07270-1 doi: 10.1007/s00330-020-07270-1
|
| [14] |
R. Fusco, R. Grassi, V. Granata, S. V. Setola, F. Grassi, D. Cozzi, et al., Artificial intelligence and COVID-19 using Chest CT scan and Chest X-ray images: Machine learning and deep learning approaches for diagnosis and treatment, J. Pers. Med., 11 (2021), 993. https://doi.org/10.3390/jpm11100993 doi: 10.3390/jpm11100993
|
| [15] |
F. Shan, Y. Gao, J. Wang, W. Shi, N. Shi, M. Han, et al., Abnormal lung quantification in chest CT images of COVID-19 patients with deep learning and its application to severity prediction, Med. Phys., 48 (2021), 1633-1645. https://doi.org/10.1002/mp.14609 doi: 10.1002/mp.14609
|
| [16] |
Y. Z. Feng, S. Liu, Z. Y. Cheng, J. C. Quiroz, D. Rezazadegan, P. Chen, et al., Severity assessment and progression prediction of COVID-19 patients based on the LesionEncoder framework and chest CT, Information, 12 (2021), 471. https://doi.org/10.3390/info12110471 doi: 10.3390/info12110471
|
| [17] |
A. G. Dastider, F. Sadik, S. A. Fattah, An integrated autoencoder-based hybrid CNN-LSTM model for COVID-19 severity prediction from lung ultrasound, Comput. Biol. Med., 132 (2021), 104296. https://doi.org/10.1016/j.compbiomed.2021.104296 doi: 10.1016/j.compbiomed.2021.104296
|
| [18] | N. Alballa, I. Al-Turaiki, Machine learning approaches in COVID-19 diagnosis, mortality, and severity risk prediction: A review, Inform. Med. Unlocked, 24 (2021), 100564. https://doi.org/10.1016/j.imu.2021.100564 |
| [19] |
Z. Car, S. B. Šegota, N. Anđelić, I. Lorencin, V. Mrzljak, Modeling the spread of COVID-19 infection using a multilayer perceptron, Comput. Math. Methods Med., 29 (2020), 5714714. https://doi.org/10.1155/2020/5714714 doi: 10.1155/2020/5714714
|
| [20] |
A. Blagojević, T. Šušteršič, I. Lorencin, S. B. Šegota, N. Anđelić, D. Milovanović, et al., Artificial intelligence approach towards assessment of condition of COVID-19 patients-Identification of predictive biomarkers associated with severity of clinical condition and disease progression, Comput. Biol. Med., 138 (2021), 104869. https://doi.org/10.1016/j.compbiomed.2021.104869 doi: 10.1016/j.compbiomed.2021.104869
|
| [21] |
N. Anđelić, S. B. Šegota, I. Lorencin, V. Mrzljak, Z. Car, Estimation of COVID-19 epidemic curves using genetic programming algorithm, Health Informatics J., 27 (2021), 1460458220976728. https://doi.org/10.1177/1460458220976728 doi: 10.1177/1460458220976728
|
| [22] |
C. Iwendi, A. K. Bashir, A. Peshkar, R. Sujatha, J. M. Chatterjee, S. Pasupuleti, et al., COVID-19 patient health prediction using boosted random forest algorithm, Front. Public Health, 8 (2020), 357. https://doi.org/10.3389/fpubh.2020.00357 doi: 10.3389/fpubh.2020.00357
|
| [23] |
R. K. Zimmerman, M. P. Nowalk, T. Bear, R. Taber, K. S. Clarke, T. M. Sax, et al., Proposed clinical indicators for efficient screening and testing for COVID-19 infection using Classification and Regression Trees (CART) analysis, Hum. Vaccin. Immunother., 17 (2021), 1109-1112. https://doi.org/10.1080/21645515.2020.1822135 doi: 10.1080/21645515.2020.1822135
|
| [24] |
K. K. A. Ghany, H. M. Zawbaa, H. M. Sabri, COVID-19 prediction using LSTM algorithm: GCC case study, Inform. Med. Unlocked, 23 (2021), 100566. https://doi.org/10.1016/j.imu.2021.100566 doi: 10.1016/j.imu.2021.100566
|
| [25] |
L. J. Muhammad, M. Islam, S. S. Usman, S. I. Ayon, Predictive data mining models for novel coronavirus (COVID-19) infected patients' recovery, SN Comput. Sci., 1 (2020), 1-7. https://doi.org/10.1007/s42979-020-00216-w doi: 10.1007/s42979-020-00216-w
|
| [26] | S. K. Bandyopadhyay, S. Dutta, Machine learning approach for confirmation of COVID-19 cases: positive, negative, death and release, medRxiv, 2020. https://doi.org/10.1101/2020.03.25.20043505 |
| [27] |
F. De Felice, A. Polimeni, Coronavirus disease (COVID-19): a machine learning bibliometric analysis, In Vivo, 34 (2020), 1613-1617. https://doi.org/10.21873/invivo.11951 doi: 10.21873/invivo.11951
|
| [28] |
S. Kushwaha, S. Bahl, A. K. Bagha, K. S. Parmar, M. Javaid, A. Haleem, et al., Significant applications of machine learning for COVID-19 pandemic, J. Ind. Integr. Manag., 5 (2020), 453-479. https://doi.org/10.1142/S2424862220500268 doi: 10.1142/S2424862220500268
|
| [29] |
N. S. Punn, S. K. Sonbhadra, S. Agarwal, COVID-19 epidemic analysis using machine learning and deep learning algorithms, MedRxiv, 2020. https://doi.org/10.1101/2020.04.08.20057679 doi: 10.1101/2020.04.08.20057679
|
| [30] | Kaggle Datasets, Retrieved on: 26 December 26 2021, Available from: https://www.kaggle.com/search?q=dataset+cd4+covid, |
| [31] |
L. Yan, H. T. Zhang, J. Goncalves, Y. Xiao, M. Wang, Y. Guo, et al., An interpretable mortality prediction model for COVID-19 patients, Nat. Mach. Intell., 2 (2020), 283-288. https://doi.org/10.1038/s42256-020-0180-7 doi: 10.1038/s42256-020-0180-7
|
| [32] |
A. Trickey, M. T. May, P. Schommers, J. Tate, S. M. Ingle, J. L. Guest, et al., CD4: CD8 ratio and CD8 count as prognostic markers for mortality in human immunodeficiency virus-infected patients on antiretroviral therapy: the Antiretroviral Therapy Cohort Collaboration (ART-CC), Clin. Infect. Dis., 65 (2017), 959-966. https://doi.org/10.1093/cid/cix466 doi: 10.1093/cid/cix466
|
| [33] |
N. Hasan, A methodological approach for predicting COVID-19 epidemic using EEMD-ANN hybrid model, Internet Things, 11 (2020), 100228. https://doi.org/10.1016/j.iot.2020.100228 doi: 10.1016/j.iot.2020.100228
|
| [34] |
H. M. Gomes, J. P. Barddal, F. Enembreck, A. Bifet, A survey on ensemble learning for data stream classification, ACM Comput. Surveys, 50 (2017), 23. https://doi.org/10.1145/3054925 doi: 10.1145/3054925
|
| [35] |
S. Dˇzeroski, B. Zenko, Is combining classifiers with stacking better than selecting the best one?, Mach. Learn., 54 (2004), 255-273. https://doi.org/10.1023/B:MACH.0000015881.36452.6e doi: 10.1023/B:MACH.0000015881.36452.6e
|
| [36] |
O. Sagi, L. Rokach, Ensemble learning: A survey, WIREs Data Mining Knowl. Discov., 8 (2018), e1249. https://doi.org/10.1002/widm.1249 doi: 10.1002/widm.1249
|
| [37] | The all relevant feature selection using random forest MB Kursa, preprint, arXiv: 1106.5112. |
| [38] |
G. Chandrashekar, F. Sahin, A survey on feature selection methods. Comput. Electr.l Eng., 40 (2014), 16-28. https://doi.org/10.1016/j.compeleceng.2013.11.024 doi: 10.1016/j.compeleceng.2013.11.024
|
| [39] | A. Bommert, X. Sun, B. Bischl, J. Rahnenführer, M. Lang, Benchmark for filter methods for feature selection in high-dimensional classification data. Comput. Stat. Data Anal., 143 (2020), 106839. https://doi.org/10.1016/j.csda.2019.106839 |
| [40] |
B. Venkatesh, J. Anuradha, A review of feature selection and its methods, Cybern. Inform. Technol., 19 (2019), 3-26. https://doi.org/10.2478/cait-2019-0001 doi: 10.2478/cait-2019-0001
|
| [41] |
L. N. Sanchez-Pinto, L. R. Venable, J. Fahrenbach, M. M. Churpek, Comparison of variable selection methods for clinical predictive modeling, Int. J. Med. Inform., 116 (2018), 10-17. https://doi.org/10.1016/j.ijmedinf.2018.05.006 doi: 10.1016/j.ijmedinf.2018.05.006
|
| [42] |
M. Azmi, G. C. Runger, A. Berrado, Interpretable regularized class association rules algorithm for classification in a categorical data space, Inform. Sci., 483 (2019), 313-331. https://doi.org/10.1016/j.ins.2019.01.047 doi: 10.1016/j.ins.2019.01.047
|
| [43] | F. Thabtah, P. Cowling, Y. Peng, MCAR: multi-class classification based on association rule. In The 3rd ACS/IEEE International Conference on Computer Systems and Applications, (2005), 33. https://doi.org/10.1109/AICCSA.2005.1387030 |
| [44] | K. Mittal, G. Aggarwal, P. Mahajan, A comparative study of association rule mining techniques and predictive mining approaches for association classification, I. J. Adv. Res. Comput. Sci., 8 (2017). |
| [45] | J. Allaire, RStudio: integrated development environment for R, Boston MA, 770 (2012), 165-171. |
| [46] | W. Gardner, R. Maliki, S. M. Cutts, B. W. Muir, D. Ballabio, D. A. Winkler, et al., Self-organizing map and relational perspective mapping for the accurate visualization of high-dimensional hyperspectral data, Anal. Chem., 92 (15), 10450-10459. https://doi.org/10.1021/acs.analchem.0c00986 |
| [47] |
I. Izonin, R. Tkachenko, N. Shahovska, N. Lotoshynska, The additive input-doubling method based on the SVR with nonlinear kernels: small data approach, Symmetry, 13 (2021), 612. https://doi.org/10.3390/sym13040612 doi: 10.3390/sym13040612
|
| [48] |
I. Izonin, R. Tkachenko, I. Droniuk, P. Tkachenko, M. Gregus, M. Rashkevych, Predictive modeling based on small data in clinical medicine: RBF-based additive input-doubling method, Math. Biosci. Eng., 31 (2021), 2599. https://doi.org/10.3934/mbe.2021132 doi: 10.3934/mbe.2021132
|
Figures(6) / Tables(11)

Natalya Shakhovska, Vitaliy Yakovyna, Valentyna Chopyak. A new hybrid ensemble machine-learning model for severity risk assessment and post-COVID prediction system[J]. Mathematical Biosciences and Engineering, 2022, 19(6): 6102-6123. doi: 10.3934/mbe.2022285







 DownLoad:
DownLoad: