This paper is an extended and supplemented version of the paper "Recommendation Rules Mining for Reducing the Spread of COVID-19 Cases", presented by the authors at the 3rd International Conference on Informatics & Data-Driven Medicine in November 2020. The paper examines the impact of government restrictive measures on the spread and effects of COVID-19. The work is devoted to the improvement of recommendation rules based on novel ensemble of machine learning methods such as regression tree and clustering. The dynamics of migration between countries in clusters, and their relationship with the number of confirmed cases and the percentage of deaths caused by COVID-19, were studied on the example of Poland, Italy and Germany. It is shown that there is a clear relationship between the cluster number and the number of new cases of diseases and death. It has also been shown that different countries' policies to prevent the disease, in particular the timing of restrictive measures, correlate with the dynamics of the spread of COVID-19 and the consequences of the disease. For example, the results show a clear proactive tactic of restrictive measures by example of Germany, and catching up on the spread of the disease by example of Italy. A regression tree and guidelines about influence of features on the spreading of COVID-19 and mortality due to this infection have been constructed. The paper predicts the number of deaths due to COVID-19 on a 21-day interval using the obtained guidelines on the example of Sweden. Such forecasting was carried out for two potential government action options: with existing precautionary actions and the same precautionary actions, if they had been taken 20 days earlier (following the example of Germany). The RMSE of the mortality forecast does not exceed 4.2, which shows a good prognostic ability of the developed model. At the same time, the simulation based on the strategy of anticipatory introduction of restrictions gives 2–6% lower values of the forecast of the number of new cases. Thus, the results of this study provide an opportunity to assess the impact of decisions about restrictive measures and predict, simulate the consequences of restrictions policy.
Citation: Vitaliy Yakovyna, Natalya Shakhovska. Modelling and predicting the spread of COVID-19 cases depending on restriction policy based on mined recommendation rules[J]. Mathematical Biosciences and Engineering, 2021, 18(3): 2789-2812. doi: 10.3934/mbe.2021142
This paper is an extended and supplemented version of the paper "Recommendation Rules Mining for Reducing the Spread of COVID-19 Cases", presented by the authors at the 3rd International Conference on Informatics & Data-Driven Medicine in November 2020. The paper examines the impact of government restrictive measures on the spread and effects of COVID-19. The work is devoted to the improvement of recommendation rules based on novel ensemble of machine learning methods such as regression tree and clustering. The dynamics of migration between countries in clusters, and their relationship with the number of confirmed cases and the percentage of deaths caused by COVID-19, were studied on the example of Poland, Italy and Germany. It is shown that there is a clear relationship between the cluster number and the number of new cases of diseases and death. It has also been shown that different countries' policies to prevent the disease, in particular the timing of restrictive measures, correlate with the dynamics of the spread of COVID-19 and the consequences of the disease. For example, the results show a clear proactive tactic of restrictive measures by example of Germany, and catching up on the spread of the disease by example of Italy. A regression tree and guidelines about influence of features on the spreading of COVID-19 and mortality due to this infection have been constructed. The paper predicts the number of deaths due to COVID-19 on a 21-day interval using the obtained guidelines on the example of Sweden. Such forecasting was carried out for two potential government action options: with existing precautionary actions and the same precautionary actions, if they had been taken 20 days earlier (following the example of Germany). The RMSE of the mortality forecast does not exceed 4.2, which shows a good prognostic ability of the developed model. At the same time, the simulation based on the strategy of anticipatory introduction of restrictions gives 2–6% lower values of the forecast of the number of new cases. Thus, the results of this study provide an opportunity to assess the impact of decisions about restrictive measures and predict, simulate the consequences of restrictions policy.

| [1] | Worldometer: Coronavirus Update (Live): 119,292,681 Cases and 2,644,627 Deaths from COVID-19 Virus pandemic, 2020. Available from: https://www.worldometers.info/coronavirus/. |
| [2] | WHO Director-General: Opening remarks at the media briefing on COVID-19, 11 March 2020. Available from: https://www.who.int/director-general/speeches/detail/who-director-general-s-opening-remarks-at-the-media-briefing-on-covid-19---11-march-2020. |
| [3] | World Health Organization: Coronavirus disease (COVID-19), 2020. Available from: https://www.who.int/emergencies/diseases/novel-coronavirus-2019. |
| [4] | X. Zhang, R. Ma, L. Wang, Predicting turning point, duration and attack rate of COVID-19 outbreaks in major Western countries, Chaos Soliton. Fract., 135 (2020), 109829. |
| [5] | K. E. Asnaoui, Y. Chawki, A. Idri, Automated methods for detection and classification pneumonia based on X-ray Images using deep learning, preprint, arXiv: 2003.14363. |
| [6] | Y. Kryvenchuk, I. Helzynskyy, T. Helzhynska, N. Boyko, R. Danel, Synthesis сontrol system physiological state of a soldier on the battlefield, CEUR-WS.org, 2488 (2019), 297-306. |
| [7] | N. Melnykova, V. Melnykov, E. Vasilevskis, The personalized approach to the processing and analysis of patients' medical data, CEUR-WS.org, 2255 (2018), 103-112. |
| [8] |
N. Shakhovska, S. Fedushko, M. Greguš ml., N. Melnykova, I. Shvorob, Y. Syerov, Big data analysis in development of personalized medical system, Proced. Computer Sci., 160 (2019), 229-234. doi: 10.1016/j.procs.2019.09.461

|
| [9] |
Z. Wang, K. Tang, Combating COVID-19: Health equity matters, Nat. Med., 26 (2020), 458-458. doi: 10.1038/s41591-020-0823-6
|
| [10] | V. Yakovyna, N. Shakhovska, K. Shakhovska, J. Campos, Recommendation rules mining for reducing the spread of COVID-19 cases, CEUR-WS.org, 2753 (2020), 219-229. |
| [11] | Covid-19 Data Science: Home, 2020. Available from: https://www.covid-datascience.com/. |
| [12] | A. Doanvo, X. Qian, D. Ramjee, H. Piontkivska, A. Desai, M. Majumder, Machine learning maps research needs in COVID-19 literature, Patterns, 1 (2020), 100123. |
| [13] | S. Basu, R. H. Campbell, Going by the numbers: Learning and modeling COVID-19 disease dynamics, Chaos Soliton. Fract., 138 (2020), 110140. |
| [14] | R. A. Neher, R. Dyrdak, V. Druelle, E. B. Hodcroft, J. Albert, Potential impact of seasonal forcing on a SARS-CoV-2 pandemic, Swiss. Med. Wkly., 150 (2020), 20224. |
| [15] | S. Tuli, S. Tuli, R. Tuli, S. S. Gill, Predicting the growth and trend of COVID-19 pandemic using machine learning and cloud computing, Int. Things, 11 (2020), 100222. |
| [16] | Z. Hu Z, Q. Ge, L. Jin, M. Xiong, Artificial intelligence forecasting of Covid-19 in China, preprint, arXiv: 200207112. |
| [17] | S. K. Bandyopadhyay, S. Dutta, Machine learning approach for confirmation of COVID-19 cases: Positive, negative, death and release, preprint, medRxiv/2020.03.25.20043505. |
| [18] | Z. Yang, Z. Zeng, K. Wang, S. S. Wong, W. Liang, M. Zanin, et al., Modified SEIR and AI prediction of the epidemics trend of COVID-19 in China under public health interventions, J. Thorac. Dis., 12 (2020), 165-174. |
| [19] | J. K. Davis, T. Gebrehiwot, M. Worku, W. Awoke, A. Mihretie, D. Nekorchuk, et al., A genetic algorithm for identifying spatially-varying environmental drivers in a malaria time series model, Environ. Model. Software, 119 (2019), 275-284. |
| [20] | J. M. Scavuzzo, F. Trucco, M. Espinosa, C. B. Tauro, M. Abril, C. M. Scavuzzo, et al., Modeling Dengue vector population using remotely sensed data and machine learning, Acta Tropica, 185 (2018), 167-175. |
| [21] | M. H. D. M. Ribeiro, R. G. da Silva, V. C. Mariani, L. dos Santos Coelho, Short-term forecasting COVID-19 cumulative confirmed cases: perspectives for Brazil, Chaos Soliton. Fract., 135 (2020), 109853. |
| [22] | D. Fanelli, F. Piazza, Analysis and forecast of COVID-19 spreading in China, Italy and France, Chaos Soliton. Fract., 134 (2020), 109761. |
| [23] | K. Roosa, Y. Lee, R. Luo, A. Kirpich, R. Rothenberg, J. Hyman, et al., Real-time forecasts of the COVID-19 epidemic in China from February 5th to February 24th, 2020, Infect. Dis. Model., 5 (2020), 256-263. |
| [24] |
J. Farooq, M. A. Bazaz, A novel adaptive deep learning model of Covid-19 with focus on mortality reduction strategies, Chaos Soliton. Fract., 138 (2020), 110148. doi: 10.1016/j.chaos.2020.110148
|
| [25] |
E. Kaxiras, G. Neofotistos, E. Angelaki, The first 100 days: Modeling the evolution of the COVID-19 pandemic, Chaos Soliton. Fract., 138 (2020), 110114. doi: 10.1016/j.chaos.2020.110114
|
| [26] | A. S. Fokas, N. Dikaios, G. A. Kastis, Predictive mathematical models for the number of individuals infected with COVID-19, preprint, medRxiv/2020.05.02.20088591. |
| [27] | R. Tkachenko, I. Izonin, P. Vitynskyi, N. Lotoshynska, O. Pavlyuk, Development of the non-iterative supervised learning predictor based on the ito decomposition and SGTM neural-like structure for managing medical insurance costs, Data, 3 (2018), 46. |
| [28] | N. Hasan, A methodological approach for predicting COVID-19 epidemic using EEMD-ANN hybrid model, Int. Things, 11 (2020), 100228. |
| [29] | K. C. Santosh, COVID-19 prediction models and unexploited data, J. Med. Syst., 44 (2020), 170. |
| [30] | S. Sengupta, S. Mugde, G. Sharma, Covid-19 pandemic data analysis and forecasting using machine learning algorithms, preprint, medRxiv/2020.06.25.20140004. |
| [31] | Azure Open Datasets Catalog: COVID-19 Data Lake, 2020. Available from: https://azure.microsoft.com/en-us/services/open-datasets/catalog/covid-19-data-lake/. |
| [32] | United Nations Department of Economic and Social Affairs: Population Dynamics, 2016. Available from: https://www.un.org/development/desa/en/key-issues/population.html. |
| [33] | D. Gamberger, N. Lavrac, C. Groselj, Experiments with noise filtering in a medical domain, in Proc. of the Sixteenth Intl. Conf. on Machine Learning, San Francisco, CA, USA, Morgan Kaufmann Publishers Inc., (1999), 143-151. |
| [34] | I. Izonin, R. Tkachenko, V. Verhun, K. Zub, An approach towards missing data management using improved GRNN-SGTM ensemble method, JESTECH, paper in press. |
| [35] |
E. Meng, S. Huang, Q. Huang, W. Fang, L. Wu, L. Wang, A robust method for non-stationary streamflow prediction based on improved EMD-SVM model, J. Hydrol., 568 (2019), 462-478. doi: 10.1016/j.jhydrol.2018.11.015
|
| [36] |
M. El-Hendawi, Z. Wang, An ensemble method of full wavelet packet transform and neural network for short term electrical load forecasting, Electr. Power Systems Res., 182 (2020), 106265. doi: 10.1016/j.epsr.2020.106265
|
| [37] | S. van Buuren, K. Groothuis-Oudshoorn, Mice: Multivariate imputation by chained equations in R, J. Stat. Soft., 45 (2011), 1-67. |
| [38] | Y. Vyklyuk, M. Manylich, M. Škoda, M. M. Radovanović, M. D. Petrović, Modeling and analysis of different scenarios for the spread of COVID-19 by using the modified multi-agent systems— evidence from the selected countries, Results Phys., 20 (2021), 103662. |
| [39] | N. Shakhovska, I. Izonin, N. Melnykova, The hierarchical classifier for COVID-19 resistance evaluation, Data, 6 (2021), 6. |
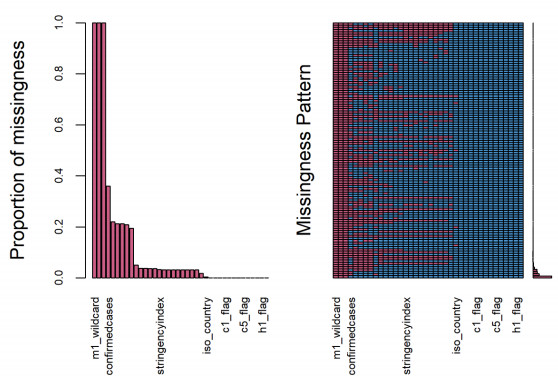
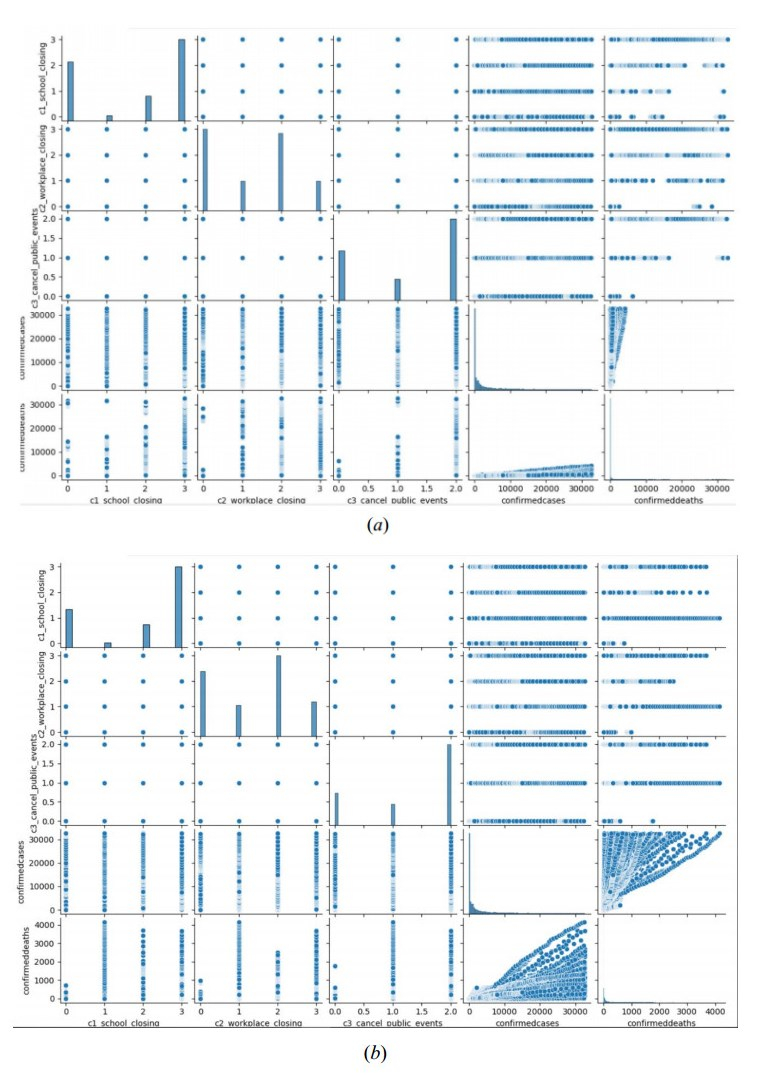
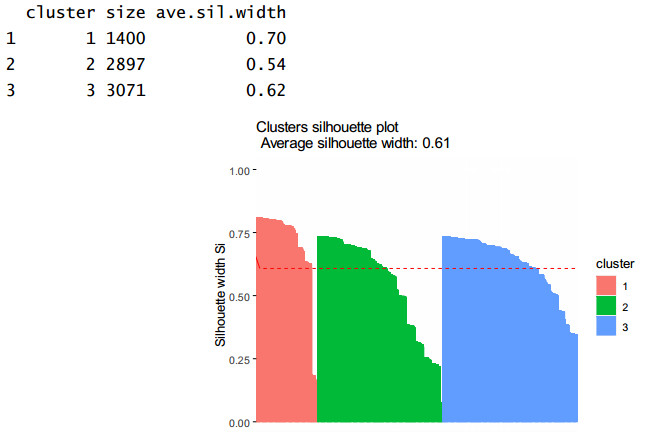
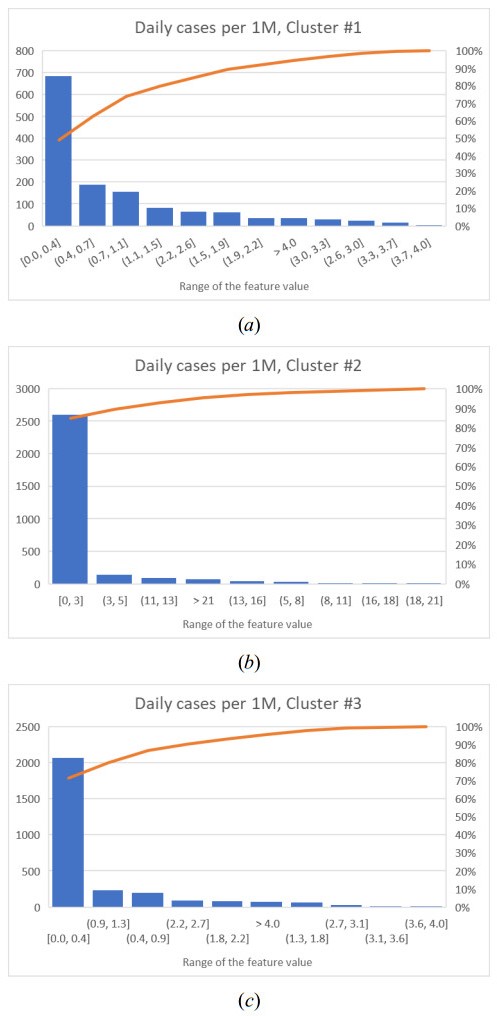
Figures(9) / Tables(6)

Vitaliy Yakovyna, Natalya Shakhovska. Modelling and predicting the spread of COVID-19 cases depending on restriction policy based on mined recommendation rules[J]. Mathematical Biosciences and Engineering, 2021, 18(3): 2789-2812. doi: 10.3934/mbe.2021142







 DownLoad:
DownLoad: