Citation: Chenxi Dai, ZhiWang, Weiming Wang, Yongqin Li, Kaifa Wang. Epidemics and underlying factors of multiple-peak pattern on hand, foot and mouth disease inWenzhou, China[J]. Mathematical Biosciences and Engineering, 2019, 16(4): 2168-2188. doi: 10.3934/mbe.2019106

| [1] | W. Xing, Q. Liao and C. Viboud, et al., Hand, foot, and mouth disease in China, 2008-12: An epidemiological study, Lancet Infect. Dis., 14 (2014), 308–318. |
| [2] | J. Li, Y. Fu and A. Xu, et al., A spatial-temporal ARMA model of the incidence of hand, foot, and mouth disease in Wenzhou, China, Abstr. Appl. Anal., 2014 (2014), 1–9. |
| [3] | Y. Zhu, B. Xu and X. Lian, et al., A hand-foot-and-mouth disease model with periodic transmission rate in Wenzhou, China, Abstr. Appl. Anal., 2014 (2014), 1–11. |
| [4] | Z.C. Zhuang, Z.Q. Kou and Y.J. Bai, et al., Epidemiological research on hand, foot, and mouth disease in mainland China, Viruses, 7 (2015), 6400–6411. |
| [5] | K. Kaminska, G. Martinetti and R. Lucchini, et al., Coxsackievirus A6 and hand, foot, and mouth disease: three case reports of familial child-to-immunocompetent adult transmission and a literature review, Case Rep. Dermatol., 5 (2013), 203–209. |
| [6] | J.P. Lott, K. Liu and M.L. Landry, et al., Atypical hand-foot-and-mouth disease associated with coxsackievirus A6 infection, J. Am. Acad. Dermatol., 69 (2013), 736–741. |
| [7] | M.H. Ooi, S.C. Wong and P. Lewthwaite, et al., Clinical features, diagnosis, and management of enterovirus 71, Lancet Neurol., 9 (2010), 1097–1105. |
| [8] | Q.Y. Mao, Y. Wang and L. Bian, et al., EV71 vaccine, a new tool to control outbreaks of hand, foot and mouth disease (HFMD), Expert Rev. Vacc., 15 (2016), 599–606. |
| [9] | D. Onozuka and M. Hashizume, The influence of temperature and humidity on the incidence of hand, foot, and mouth disease in Japan, Sci. Total Environ., 410-411 (2011), 119–125. |
| [10] | Z. Du, W. Zhang and D. Zhang, et al., Estimating the basic reproduction rate of HFMD using the time series SIR model in Guangdong, China, PLoS ONE, 12 (2017), 1–11. |
| [11] | F. Gou, X. Liu and J. He, et al., Different responses of weather factors on hand, foot and mouth disease in three different climate areas of Gansu, China, BMC Infect. Dis., 18 (2018), 1–10. |
| [12] | Y.L. Hii, J. Rocklöv and N. Ng, Short term effects of weather on hand, foot and mouth disease, PLoS ONE, 6 (2011), 1–6. |
| [13] | J.Wang, T. Hu and D. Sun, et al., Epidemiological characteristics of hand, foot, and mouth disease in Shandong, China, 2009-2016, Sci. Rep., 7 (2017), 1–9. |
| [14] | P. Wang, H. Zhao and F. You, et al., Seasonal modeling of hand, foot, and mouth disease as a function of meteorological variations in Chongqing, China, Int. J. Biometeorol., 61 (2017), 1411–1419. |
| [15] | W. Dong, X. Li and P. Yang, et al., The effects of weather factors on hand, foot and mouth disease in Beijing, Sci. Rep., 6 (2016), 1–9. |
| [16] | H. Feng, G. Duan and R. Zhang, et al., Time series analysis of hand-foot-mouth disease hospitalization in Zhengzhou: establishment of forecasting models using climate variables as predictors, PLoS ONE, 9 (2014), 1–10. |
| [17] | W. Liu, H. Ji and J. Shan, et al., Spatiotemporal dynamics of hand-foot-mouth disease and its relationship with meteorological factors in Jiangsu province, China, PLoS ONE, 10 (2015), 1–13. |
| [18] | Y. Liu, X. Wang and C. Pang, et al., Spatio-temporal analysis of the relationship between climate and hand, foot, and mouth disease in Shandong province, China, 2008-2012, BMC Infect. Dis., 15 (2015), 1–8. |
| [19] | J. Wei, A. Hansen and Q. Liu, et al., The effect of meteorological variables on the transmission of hand, foot and mouth disease in four major cities of Shanxi province, China: a time series data analysis (2009-2013), PLoS Negl. Trop. Dis., 9 (2015), 1–19. |
| [20] | L.Y. Chang, C.C. King and K.H. Hsu, et al., Risk factors of enterovirus 71 infection and associated hand, foot, and mouth disease/herpangina in children during an epidemic in Taiwan, Pediatrics, 109 (2002), 1–6. |
| [21] | L. Sun, H. Lin and J. Lin, et al., Evaluating the transmission routes of hand, foot, and mouth disease in Guangdong, China, Am. J. Infect. Control., 44 (2016), e13–e14. |
| [22] | Y.H. Xie, V. Chongsuvivatwong and Y. Tan, et al., Important roles of public playgrounds in the transmission of hand, foot, and mouth disease, Epidemiol. Infect., 143 (2015), 1432–1441. |
| [23] | H.W. Hethcote, The mathematics of infectious diseases, SIAM Rev., 42 (2000), 599–653. |
| [24] | Y. Cai, X. Lian and Z. Peng, et al., Spatiotemporal transmission dynamics for influenza disease in a heterogenous environment, Nonlinear Anal. Real., 46 (2019), 178–194. 25. Y. Cai, K. Wang and W.M. Wang, Global transmission dynamics of a Zika virus model, Appl. Math. Lett., 92 (2019), 190–195. |
| [25] | 26. A. Cori, N.M. Ferguson and C. Fraser, et al., A new framework and software to estimate timevarying reproduction numbers during epidemics, Am. J. Epidemiol., 178 (2013), 1505–1512. |
| [26] | 27. E. Ma, C. Fung and S.H.E. Yip, et al., Estimation of the basic reproduction number of enterovirus 71 and coxsackievirus A16 in hand, foot, and mouth disease outbreaks, Pediatr. Infect. Dis. J., 30 (2011), 675–679. |
| [27] | 28. C.C. Lai, D.S. Jiang and H.M. Wu, et al., A dynamic model for the outbreaks of hand, foot, and mouth disease in Taiwan, Epidemiol. Infect., 144 (2016), 1500–1511. |
| [28] | 29. Y. Li, J. Zhang and X. Zhang, Modeling and preventive measures of hand, foot and mouth disease (HFMD) in China, Int. J. Environ. Res. Public Health, 11 (2014), 3108–3117. |
| [29] | 30. Y. Li, L. Wang and L. Pang, et al., The data fitting and optimal control of a hand, foot and mouth disease (HFMD) model with stage structure, Appl. Math. Comput., 276 (2016), 61–74. |
| [30] | 31. Y. Ma, M. Liu and Q. Hou, et al., Modelling seasonal HFMD with the recessive infection in Shandong, China, Math. Biosci. Eng., 10 (2013), 1159–1171. |
| [31] | 32. F.C.S. Tiing and J. Labadin, A simple deterministic model for the spread of hand, foot and mouth disease (HFMD) in Sarawak, Second Asia International Conference on Modelling & Simulation (AMS), (2008), 947–952. |
| [32] | 33. J.Y. Yang, Y. Chen and F.Q. Zhang, Stability analysis and optimal control of a hand-foot-mouth disease (HFMD) model, J. Appl. Math. Comput., 41 (2012), 99–117. |
| [33] | 34. Public Health Statistical Data of Wenzhou City, Report of Wenzhou Center for Disease Control and Prevention, 2018. Available from: http://www.wzcdc.org.cn/. |
| [34] | 35. Guidelines on Drawing up the School Calendar, Report of Wenzhou Education Bureau, 2018. Available from: http://www.wzer.net/. |
| [35] | 36. Meteorological information of Wenzhou city, Report of China Meteorological Data Sharing Service System, 2018. Available from: http://data.cma.cn/. |
| [36] | 37. E. Vynnycky, A. Trindall and P. Mangtani, Estimates of the reproduction numbers of Spanish influenza using morbidity data, , Int. J. Epidemiol., (2007), 881–889. |
| [37] | 38. H. Haario, M. Laine and A. Mira, et al., DRAM: efficient adaptive MCMC, Stat. Comput., 16 (2006), 339–354. |
| [38] | 39. N. Bacaër and S. Guernaoui, The epidemic threshold of vector-borne disease with seasonality, J. Math. Biol., 53 (2006), 421–436. |
| [39] | 40. W. Wang and X.Q. Zhao, Threshold dynamics for compartmental epidemic models in periodic environments, J. Dyn. Differ. Equat., 20 (2008), 699–717. |
| [40] | 41. Y. Xiao, S. Tang and Y. Zhou, et al., Predicting the HIV/AIDS epidemic and measuring the effect of mobility in mainland China, J. Theor. Biol., 317 (2013), 271–285. |
| [41] | 42. S. Marino, I.B. Hogue and C.J. Ray, et al., A methodology for performing global uncertainty and sensitivity analysis in systems biology, J. Theor. Biol., 254 (2008), 178–196. |
| [42] | 43. J. Wu, R. Dhingra and M. Gambhir, et al., Sensitivity analysis of infectious disease models: methods, advances and their application, J. R. Soc. Interface, 10 (2013), 1–14. |
| [43] | 44. B. Yang, E.H.Y. Lau and P. Wu, et al., Transmission of hand, foot and mouth disease and its potential driving factors in Hong Kong, Sci. Rep., 6 (2016), 1–8. |
| [44] | 45. J. Wu, J. Cheng and Z. Xu, et al., Nonlinear and interactive effects of temperature and humidity on childhood hand, foot and mouth disease in Hefei, China, Pediatr. Infect. Dis. J., 35 (2016), 1086–1091. |
| [45] | 46. L.W. Ang, B.K. Koh and K.P. Chan, et al., Epidemiology and control of hand, foot and mouth disease in Singapore, 2001-2007, An. Aca. Med., 38 (2009), 106–112. |
| [46] | 47. T. Solomon, P. Lewthwaite and D. Perera, et al., Virology, epidemiology, pathogenesis, and control of enterovirus 71, Lancet Infect. Dis., 10 (2010), 778–790. |
| [47] | 48. M. B´elanger, K. Gray-Donald and J. O'loughlin, et al., Influence of weather conditions and season on physical activity in adolescents, Ann. Epidemiol., 19 (2009), 180–186. |
| [48] | 49. M.M. Suminski, W.C. Poston and P. Market, et al., Meteorological conditions are associated with physical activities performed in open-air settings, Int. J. Biometeorol., 52 (2008), 189–197. |
| [49] | 50. F.X. Abad, R.M. Pinto and A. Bosch, Survival of enteric viruses on environmental fomites, Appl. Environ. Microbiol., 60 (1994), 3704–3710. |
| [50] | 51. H.L. Chang, C.P. Chio and H.J. Su, et al., The association between enterovirus 71 infections and meteorological parameters in Taiwan, PLoS ONE, 7 (2012), 1–5. |
| [51] | 52. I. Hashimoto and A. Hashimoto, Comparative studies on the neurovirulence of temperaturesensitive and temperature-resistant viruses of enterovirus 71 in monkeys, Acta Neuropathol., 60 (1983), 266–270. |
| [52] | 53. S. Altizer, A. Dobson and P. Hosseini, et al., Seasonality and the dynamics of infectious diseases, Ecol. Lett., 9 (2006), 467–484. |
| [53] | 54. S.F. Dowell, Seasonal variation in host susceptibility and cycles of certain infectious diseases, Emerg. Infect. Dis., 7 (2001), 369–374. |
| [54] | 55. Z. Yang, Q. Zhang and B.J. Cowling, et al., Estimating the incubation period of hand, foot and mouth disease for children in different age groups, Sci. Rep., 7 (2017), 1–5. |
| [55] | 56. W.M. Koh, H. Badaruddin and H. La, et al., Severity and burden of hand, foot and mouth disease in Asia: a modelling study, BMJ Glob. Health, 3 (2018), 1–10. |
| [56] | 57. J. Liu, G.L. Zhang and G.Q. Huang, et al., Therapeutic effect of Jinzhen oral liquid for hand foot and mouth disease: a randomized, multi-center, double-blind, placebo-controlled trial, PLoS ONE, 9 (2014), 1–9. |
| [57] | 58. Wenzhou Health Statistical Year book, Report of Wenzhou Statistical Bureau, 2018. Available from: http://wztjj.wenzhou.gov.cn/. |
| [58] | 59. R. Huang, G. Bian and T. He, et al., Effects of meteorological parameters and PM10 on the incidence of hand, foot, and mouth disease in children in China, Int. J. Environ. Res. Public Health, 13 (2016), 1–13. |
| [59] | 60. H. Qi, Y. Chen and D. Xu, et al., Impact of meteorological factors on the incidence of childhood hand, foot, and mouth disease (HFMD) analyzed by DLNMs-based time series approach, Infect. Dis. Poverty, 7 (2018), 1–10. |
| [60] | 61. MCMC toolbox for Matlab, Report of Marko Laine, 2018. Available from: http://helios. fmi.fi/~lainema/mcmc/. |

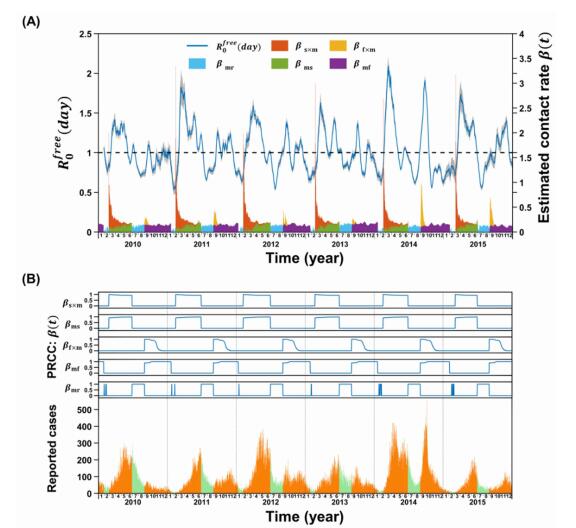
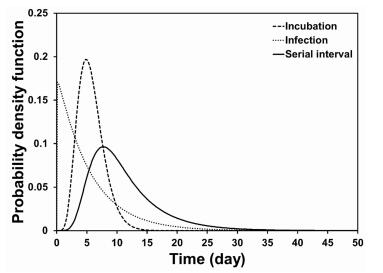
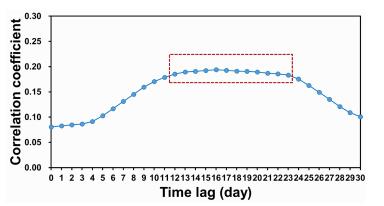
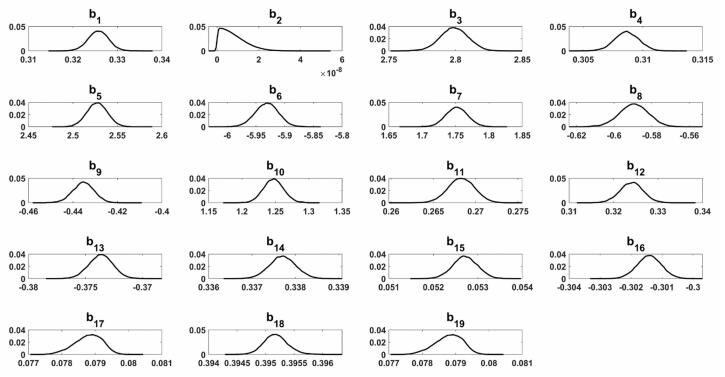
Figures(9) / Tables(5)

Chenxi Dai, ZhiWang, Weiming Wang, Yongqin Li, Kaifa Wang. Epidemics and underlying factors of multiple-peak pattern on hand, foot and mouth disease inWenzhou, China[J]. Mathematical Biosciences and Engineering, 2019, 16(4): 2168-2188. doi: 10.3934/mbe.2019106







 DownLoad:
DownLoad: