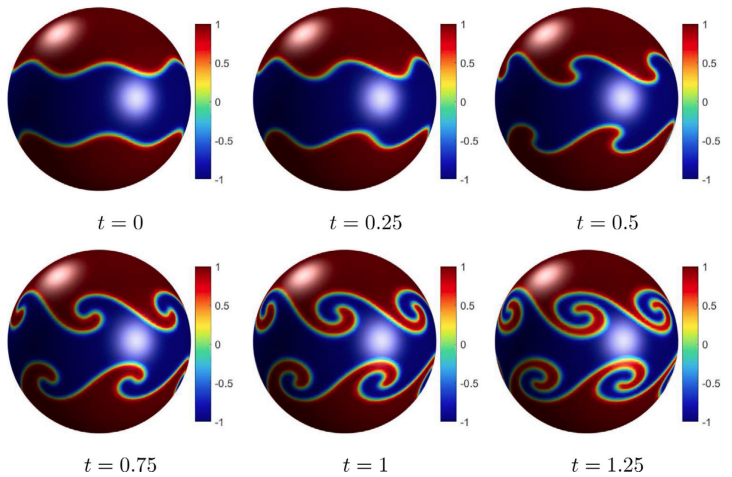
We introduced a fully explicit finite difference method (FDM) designed for numerically solving the conservative Allen–Cahn equation (CAC) on a cubic surface. In this context, the cubic surface refers to the combined areas of the six square faces that enclose the volume of a cube. The proposed numerical solution approach is structured into two sequential steps. First, the Allen–Cahn (AC) equation was solved by applying the fully explicit FDM, which is computationally efficient. Following this, the conservation term is resolved using the updated solution from the AC equation to ensure consistency with the underlying conservation principles. To evaluate the effectiveness of the proposed scheme, computational tests are performed to verify that the resulting numerical solution of the CAC equation successfully conserves the discrete mass. Additionally, the solution is examined for its ability to exhibit the property of constrained motion by mass conserving mean curvature, a critical characteristic of the CAC equation. These two properties are fundamental to the integrity and accuracy of the CAC equation.
Citation: Youngjin Hwang, Jyoti, Soobin Kwak, Hyundong Kim, Junseok Kim. An explicit numerical method for the conservative Allen–Cahn equation on a cubic surface[J]. AIMS Mathematics, 2024, 9(12): 34447-34465. doi: 10.3934/math.20241641
We introduced a fully explicit finite difference method (FDM) designed for numerically solving the conservative Allen–Cahn equation (CAC) on a cubic surface. In this context, the cubic surface refers to the combined areas of the six square faces that enclose the volume of a cube. The proposed numerical solution approach is structured into two sequential steps. First, the Allen–Cahn (AC) equation was solved by applying the fully explicit FDM, which is computationally efficient. Following this, the conservation term is resolved using the updated solution from the AC equation to ensure consistency with the underlying conservation principles. To evaluate the effectiveness of the proposed scheme, computational tests are performed to verify that the resulting numerical solution of the CAC equation successfully conserves the discrete mass. Additionally, the solution is examined for its ability to exhibit the property of constrained motion by mass conserving mean curvature, a critical characteristic of the CAC equation. These two properties are fundamental to the integrity and accuracy of the CAC equation.

| [1] |
S. M. Allen, J. W. Cahn, A microscopic theory for antiphase boundary motion and its application to antiphase domain coarsening, Acta Metall., 27 (1979), 1085–1095. https://doi.org/10.1016/0001-6160(79)90196-2 doi: 10.1016/0001-6160(79)90196-2

|
| [2] |
S. Zhai, Z. Weng, Y. Mo, X. Feng, Energy dissipation and maximum bound principle preserving scheme for solving a nonlocal ternary Allen–Cahn model, Comput. Math. Appl., 155 (2024), 150–164. https://doi.org/10.1016/j.camwa.2023.06.018 doi: 10.1016/j.camwa.2023.06.018
|
| [3] |
M. Emamjomeh, M. Nabati, A. Dinmohammadi, Numerical study of two operator splitting localized radial basis function method for Allen–Cahn problem, Eng. Anal. Bound. Elem., 163 (2024), 126–137. https://doi.org/10.1016/j.enganabound.2023.07.014 doi: 10.1016/j.enganabound.2023.07.014
|
| [4] |
L. Q. Chen, Phase-field models for microstructure evolution, Ann. Rev. Mater. Res., 32 (2002), 113–140. https://doi.org/10.1146/annurev.matsci.32.112001.132041 doi: 10.1146/annurev.matsci.32.112001.132041
|
| [5] |
M. Fatima, R. P. Agarwal, M. Abbas, P. O. Mohammed, M. Shafiq, N. Chorfi, Extension of Cubic B-Spline for Solving the Time-Fractional Allen–Cahn Equation in the Context of Mathematical Physics, Computation, 12 (2024), 51. https://doi.org/10.3390/computation12030051 doi: 10.3390/computation12030051
|
| [6] |
Z. Lu, J. Wang, A novel and efficient multi-scale feature extraction method for EEG classification, AIMS Math., 9 (2024), 16605–16622. https://doi.org/10.3934/math.2024848 doi: 10.3934/math.2024848
|
| [7] |
S. Kim, J. Kim, Automatic Binary Data Classification Using a Modified Allen–Cahn Equation, Int. J. Pattern Recognit. Artif. Intell., 35 (2021), 2150013. https://doi.org/10.1142/S021800142150013X doi: 10.1142/S021800142150013X
|
| [8] |
D. Lee, S. Lee, Image segmentation based on modified fractional Allen–Cahn equation, Math. Probl. Eng., 2019 (2019), 3980181. https://doi.org/10.1155/2019/8059716 doi: 10.1155/2019/8059716
|
| [9] |
M. Beneš, V. Chalupeck'y, K. Mikula, Geometrical image segmentation by the Allen–Cahn equation, Appl. Numer. Math., 51 (2004), 187–205. https://doi.org/10.1016/j.apnum.2004.04.006 doi: 10.1016/j.apnum.2004.04.006
|
| [10] |
D. Lee, Gradient-descent-like scheme for the Allen–Cahn equation, AIP Adv., 13 (2023), 085010. https://doi.org/10.1063/5.0154657 doi: 10.1063/5.0154657
|
| [11] |
D. Lee, Computing the area-minimizing surface by the Allen–Cahn equation with the fixed boundary, AIMS Math., 8 (2023), 23352–23371. https://doi.org/10.3934/math.20231184 doi: 10.3934/math.20231184
|
| [12] |
J. Yang, Y. Li, C. Lee, Y. Choi, J. Kim, Fast evolution numerical method for the Allen–Cahn equation, J. King Saud Univ. Sci., 35 (2023), 102430. https://doi.org/10.1016/j.jksus.2022.102430 doi: 10.1016/j.jksus.2022.102430
|
| [13] |
B. Xia, R. Yu, X. Song, X. Zhang, J. Kim, An efficient data assimilation algorithm using the Allen–Cahn equation, Eng. Anal. Bound. Elem., 155 (2023), 511–517. https://doi.org/10.1016/j.enganabound.2023.07.005 doi: 10.1016/j.enganabound.2023.07.005
|
| [14] |
H. Zhang, X. Qian, S. Song, Third-order accurate, large time-stepping and maximum-principle-preserving schemes for the Allen–Cahn equation, Numer. Algorithms, 95 (2024), 1213–1250. https://doi.org/10.1007/s11075-023-01482-w doi: 10.1007/s11075-023-01482-w
|
| [15] |
J. Sun, H. Zhang, X. Qian, S. Song, Up to eighth-order maximum-principle-preserving methods for the Allen–Cahn equation, Numer. Algorithms, 92 (2023), 1041–1062. https://doi.org/10.1007/s11075-022-01324-w doi: 10.1007/s11075-022-01324-w
|
| [16] |
J. Choi, S. Ham, S. Kwak, Y. Hwang, J. Kim, Stability analysis of an explicit numerical scheme for the Allen–Cahn equation with high-order polynomial potentials, AIMS Math., 9 (2024), 19332–19344. https://doi.org/10.3934/math.2024803 doi: 10.3934/math.2024803
|
| [17] |
H. Kim, G. Lee, S. Kang, S. Ham, Y. Hwang, J. Kim, Hybrid numerical method for the Allen–Cahn equation on nonuniform grids, Comput. Math. Appl., 158 (2024), 167–178. https://doi.org/10.1016/j.camwa.2023.07.010 doi: 10.1016/j.camwa.2023.07.010
|
| [18] |
X. Chen, X. Qian, S. Song, Fourth-order structure-preserving method for the conservative Allen–Cahn equation, Adv. Appl. Math. Mech., 15 (2023), 159–181. https://doi.org/10.4208/aamm.OA-2021-0303 doi: 10.4208/aamm.OA-2021-0303
|
| [19] |
J. Rubinstein, P. Sternberg, Nonlocal reaction-diffusion equations and nucleation, IMA J. Appl. Math., 48 (1992), 249–264. https://doi.org/10.1093/imamat/48.3.249 doi: 10.1093/imamat/48.3.249
|
| [20] |
M. Brassel, E. Bretin, A modified phase field approximation for mean curvature flow with conservation of the volume, Math. Meth. Appl. Sci., 10 (2011), 1157–1180. https://doi.org/10.1002/mma.1348 doi: 10.1002/mma.1348
|
| [21] |
J. Yang, J. Kim, Efficient and structure-preserving time-dependent auxiliary variable method for a conservative Allen–Cahn type surfactant system, Eng. Comput., 38 (2022), 5231–5250. https://doi.org/10.1007/s00366-021-01583-5 doi: 10.1007/s00366-021-01583-5
|
| [22] |
L. Bronsard, B. Stoth, Volume-preserving mean curvature flow as a limit of a nonlocal Ginzburg–Landau equation, SIAM J. Math. Anal., 28 (1997), 769–807. https://doi.org/10.1137/S0036141096298974 doi: 10.1137/S0036141096298974
|
| [23] |
X. Yang, J. J. Feng, C. Liu, J. Shen, Numerical simulations of jet pinching-off and drop formation using an energetic variational phase-field method, J. Comput. Phys., 218 (2006), 417–428. https://doi.org/10.1016/j.jcp.2006.02.010 doi: 10.1016/j.jcp.2006.02.010
|
| [24] |
Z. Zhang, H. Tang, An adaptive phase field method for the mixture of two incompressible fluids, Comput. Fluids, 36 (2007), 1307–1318. https://doi.org/10.1016/j.compfluid.2006.10.001 doi: 10.1016/j.compfluid.2006.10.001
|
| [25] |
B. Xia, Y. Li, Z. Li, Second-order unconditionally stable direct methods for Allen–Cahn and conservative Allen–Cahn equations on surfaces, Mathematics, 8 (2020), 1486. https://doi.org/10.3390/math8091486 doi: 10.3390/math8091486
|
| [26] |
Z. Sun, S. Zhang, A radial basis function approximation method for conservative Allen–Cahn equations on surfaces, Appl. Math. Lett., 143 (2023), 108634. https://doi.org/10.1016/j.aml.2023.108634 doi: 10.1016/j.aml.2023.108634
|
| [27] |
X. Liu, Q. Hong, H. L. Liao, Y. Gong, A multi-physical structure-preserving method and its analysis for the conservative Allen–Cahn equation with nonlocal constraint, Numer. Algorithms, 97 (2024), 1–21. https://doi.org/10.1007/s11075-023-01502-9 doi: 10.1007/s11075-023-01502-9
|
| [28] |
J. Yang, J. Kim, Numerical study of incompressible binary fluids on 3D curved surfaces based on the conservative Allen–Cahn–Navier–Stokes model, Comput. Fluids, 228 (2021), 105094. https://doi.org/10.1016/j.compfluid.2021.105094 doi: 10.1016/j.compfluid.2021.105094
|
| [29] |
J. Yang, J. Kim, A phase-field model and its efficient numerical method for two-phase flows on arbitrarily curved surfaces in 3D space, Comput. Meth. Appl. Mech. Eng., 372 (2020), 113382. https://doi.org/10.1016/j.cma.2020.113382 doi: 10.1016/j.cma.2020.113382
|
| [30] |
C. Lee, S. Kim, S. Kwak, Y. Hwang, S. Ham, S. Kang, J. Kim, Semi-automatic fingerprint image restoration algorithm using a partial differential equation, AIMS Math., 8 (2023), 27528–27541. https://doi:10.3934/math.20231408 doi: 10.3934/math.20231408
|
| [31] |
Y. Choi, J. Kim, Maximum principle preserving and unconditionally stable scheme for a conservative Allen–Cahn equation, Eng. Anal. Bound. Elem., 150 (2023), 111–119. https://doi.org/10.1016/j.enganabound.2023.05.005 doi: 10.1016/j.enganabound.2023.05.005
|
| [32] |
J. Kim, S. Lee, Y. Choi, A conservative Allen–Cahn equation with a space–time dependent Lagrange multiplier, Int. J. Eng. Sci., 84 (2014), 11–17. https://doi.org/10.1016/j.ijengsci.2014.06.004 doi: 10.1016/j.ijengsci.2014.06.004
|
| [33] |
Y. Hwang, J. Yang, G. Lee, S. Ham, S. Kang, S. Kwak, et al., Fast and efficient numerical method for solving the Allen–Cahn equation on the cubic surface, Math. Comput. Simul., 215 (2024), 338–356. https://doi.org/10.1016/j.matcom.2023.07.024 doi: 10.1016/j.matcom.2023.07.024
|
| [34] |
Y. Wang, X. Xiao, X. Feng, Numerical simulation for the conserved Allen–Cahn phase field model of two-phase incompressible flows by an efficient dimension splitting method, Commun. Nonlinear Sci. Numer. Simul., 131 (2024), 107874. https://doi.org/10.1016/j.cnsns.2024.107874 doi: 10.1016/j.cnsns.2024.107874
|
| [35] |
X. Yang, Efficient, second-order in time, and energy stable scheme for a new hydrodynamically coupled three components volume-conserved Allen–Cahn phase-field model, Math. Models Meth. Appl. Sci., 31 (2021), 753–787. https://doi.org/10.1142/S0218202521500184 doi: 10.1142/S0218202521500184
|
| [36] |
W. Cai, J. Ren, X. Gu, Y. Wang, Parallel and energy conservative/dissipative schemes for sine–Gordon and Allen–Cahn equations, Comput. Meth. Appl. Mech. Eng., 425 (2024), 116938. https://doi.org/10.1016/j.cma.2024.116938 doi: 10.1016/j.cma.2024.116938
|
| [37] |
J. Kim, D. Jeong, S. D. Yang, Y. Choi, A finite difference method for a conservative Allen–Cahn equation on non-flat surfaces, J. Comput. Phys., 334 (2017), 170–181. https://doi.org/10.1016/j.jcp.2016.12.060 doi: 10.1016/j.jcp.2016.12.060
|









Figures(10) / Tables(1)

Youngjin Hwang, Jyoti, Soobin Kwak, Hyundong Kim, Junseok Kim. An explicit numerical method for the conservative Allen–Cahn equation on a cubic surface[J]. AIMS Mathematics, 2024, 9(12): 34447-34465. doi: 10.3934/math.20241641







 DownLoad:
DownLoad: